Computer Science and Application
Vol.
12
No.
12
(
2022
), Article ID:
59687
,
12
pages
10.12677/CSA.2022.1212297
基于强化学习的多信道车联网频谱聚合共享
唐嘉程1,王辛果2
1成都信息工程大学,四川 成都
2中国航空工业无线电电子研究所,上海
收稿日期:2022年11月22日;录用日期:2022年12月21日;发布日期:2022年12月29日

摘要
针对车联网需求日益增多以及频谱资源的短缺问题,本文结合认知无线电的频谱聚合功能以及多智能体强化学习方法,提出了基于强化学习的多信道车联网频谱聚合共享模型。每一条车辆到车辆链路作为一个智能体,共同与通信环境交互。各链路独立获得观测结果,同时获得共同的奖励。用这样的设置来促进多个智能体进行合作来训练Q网络,达到改善频谱聚合位置选取和功率分配这一智能体动作的目的。仿真结果表明,通过适当的奖励设计和训练机制,多个智能体能成功学会以分布式方式合作。在不损失车辆到基础设施链路传输总带宽的前提下,本模型能大幅度提高车辆到车辆链路的负载交付率。
关键词
车联网,多智能体强化学习,认知无线电,DQN,多信道

Reinforcement Learning-Based Aggregated Spectrum Sharing for Multi-Channel Vehicular Networking
Jiacheng Tang1, Xinguo Wang2
1School of Computer Science, Chengdu University of Information Technology, Chengdu Sichuan
2Chinese Aeronautical Radio Electronics Research Institute, Shanghai
Received: Nov. 22nd, 2022; accepted: Dec. 21st, 2022; published: Dec. 29th, 2022

ABSTRACT
In response to the increasing demand of vehicular networks and the shortage of spectrum resources, this paper proposes a reinforcement learning-based spectrum aggregation and sharing model for multi-channel vehicular networks by combining the spectrum aggregation function of cognitive radio and a multi-agent reinforcement learning. Each vehicle-to-vehicle link, as an agent, interacts with the communication environment together. Each link obtains observations independently while receiving a common reward. Such a setup is used to facilitate cooperation among multiple agents to train the Q-network for the purpose of improving spectrum aggregation location picking and power allocation as an agent action. Simulation results show that multiple agents can successfully learn to cooperate in a distributed manner through appropriate reward design and training mechanisms. Without losing the total bandwidth of vehicle-to-infrastructure link transmission, this model can substantially improve the load delivery rate of vehicle-to-vehicle links.
Keywords:The Vehicular Network, Multi-Agent Reinforcement Learning, Cognitive Radio, Deep Q Network, Multi-Channal

Copyright © 2022 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
车联网V2X (vehicle-to-Everything)主要由V2I链路(Vehicle-to-Infrastructure)和V2V链路(Vehicle-to-Vehicle)组成。车载娱乐服务要求通常需要更高带宽的V2I链路,将每辆车连接到BS (Base Station)进而连接到互联网,因此判断V2I性能的QoS优劣看重的指标是链路的传输总带宽大小。在尽可能保证V2I传输总带宽的条件下,高级驾驶功能需要通过V2V链路在相邻车辆之间定期相互通信,交换单位数据包的安全消息来获取CSI (Channel State Information),CSI通常包括车辆位置、速度、行驶方向等信息,用来提高所有车辆对实时驾驶环境的“合作意识”,所以V2V链路的QoS (Quality of Service)要求尽可能低的延迟和高度的可靠性。在频谱资源日益紧缺的当下,共享信道是提高V2X链路QoS的一个不错的方向。
针对如何使用共享信道提高V2X链路QoS的问题,本文结合了认知无线电中的频谱聚合功能 [1]。频谱聚合是指次要用户可以通过正交频分多路复用方法 [2] 同时访问多个未被主要用户有效利用的离散频谱空洞并将空洞聚合成足够宽的频带以成功地完成传输任务。为了充分利用频谱资源,我们对V2I链路进行了简化,使其以正交方式占据频谱,并用固定功率进行传输。因此,频谱聚合优化的方向将聚焦于V2V链路将采取何种设计策略与V2I链路共享频谱进行数据传输,包括频谱子带的聚合范围选择和发射功率的控制。本模型虽然增加了V2V链路在有限频谱上获得共享信道的机会,但也使系统的干扰设计更加复杂,解决此问题这也是本研究的重点。
然而,车辆的高速运动带来了CSI变化的极大不确定性,但RL (Reinforcement Learning)提供了一种稳定且有效的方法来处理车联网的环境变化并执行一系列动作。文献 [3] 针对车载环境中信道快速变化所带来的挑战,提出了一种基于设备到设备的空间频谱复用方案,缓解了对全局CSI的要求。在 [4] 中,通过对V2X资源进行合理分配可最大化V2I链路的吞吐量,以适应缓慢变化的大规模信道衰落,从而降低网络信令开销。除了传统的优化方法外,最近的几个研究中还提出了基于RL的方法来解决V2X网络中的频谱分配问题 [5] [6]。在 [7] 中研究了提高多智能体V2V链路传输交付成功率问题,该研究中对于多智能体的处理思路值得参考。因此,我们将在研究中使用MARL (Multi-Agent Reinforcement Learning)来解决多信道聚合接入中的V2X频谱访问控制问题。
本文研究了多信道车联网的频谱聚合共享问题,多个V2V链路通过多信道频谱聚合共享V2I链路使用的频谱。为了实现车联网的多样化需求,我们设计了V2V链路的频谱聚合和功率分配方案。该方案最大限度地提高V2V链路的安全信息负载交付率,同时实现V2I链路的高带宽内容交付。在本研究中至少在两个方面与现有研究有所不同。首先,本研究结合频谱聚合的方法,在提高V2V负载交付率的同时,还扩展了V2I链路的传输总带宽。其次,本研究提出了一种基于MARL的频谱聚合共享方法,让V2V链路作为agent以合作的方式根据本地CSI分布式地决策出频谱聚合接入策略。
2. 问题建模
如图1所示,本研究基于蜂窝网对车联网进行建模,如3GPP第15版中针对蜂窝V2X网络补充中所讨论的一样 [8]。本模型包含M条V2I链路和K条V2V链路,在为车载高速娱乐提供同时支持的同时,为高级驾驶服务提供稳定的定期安全消息共享。V2I链路利用蜂窝网的Uu接口将车辆连接到BS以提供高速率内容服务,V2V链路则通过具有本地化D2D通信的侧链PC5接口传输周期生成的安全消息。我们假设所有收发器都使用单个天线,车联网中V2I和V2V的聚合信道集合可表示为 和 ,其中h表示每条V2I链路聚合的信道数,g表示每条V2V链路聚合的信道数。
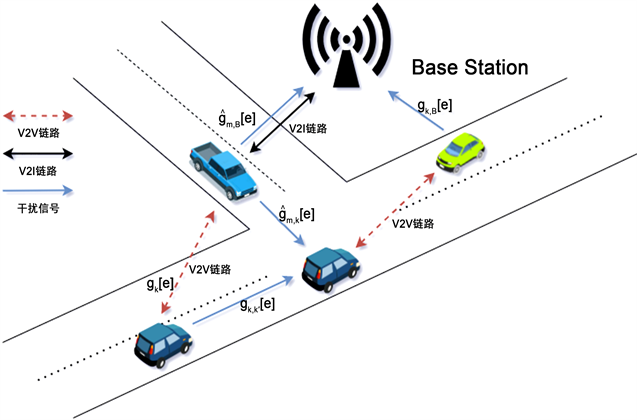
Figure 1. Vehicular network scenario diagram
图1. 车联网场景示意图
在蜂窝V2X架构的模式4中,车辆有一个无线电资源池可以自主选择是否用于V2V通信 [9]。如果有合适的干扰管理设计,那么该资源池就能与V2I链路的资源池重叠,提高频谱利用率。我们在考虑上行链路的情况下,进一步假设m条V2I链路已经提前分配完了聚合范围内具有固定传输功率的正交频谱子带,即第m条V2I链路使用了第 到 共h条频谱子带。因此,设计的主要任务是如何为V2V链路设计一种有效的频谱聚合共享方案,使V2I和V2V链路在车辆复杂高机动性环境下以最小的信令开销实现目标。
我们将几个连续的子载波组成一个频谱子带,假设在同一个子带内信道衰落相同,并且不同子带之间独立。第m条V2I链路和第k条V2V链路在第e条子带上的接收信噪比表示为
(1)
和
(2)
其中 和 分别表示第m条V2I链路和第k条V2V链路在第e条子带上的发射功率,i和j分别表示V2I链路和V2V链路在聚合范围内的子带序号。在第e条子带上,第k条V2V链路功率增益为 ,第k′条V2V链路对第k条V2V链路的干扰衰减为 ,第k条V2V链路对BS的干扰衰减为 ,第m条V2I链路对BS的干扰为 ,第m条V2I链路到第k条V2V链路的干扰为 , 是噪声功率,干扰功率表示为
(3)
其中 是二元频谱分配标志, 表示V2V链路在使用第e条子带,否则标志为0。我们假设每条V2V链路聚合g条子带,即 。第m条V2I链路和第k条V2V链路在第e条子带上的带宽为
(4)
和
(5)
其中W是每条频谱子带的带宽。
V2I链路目的是提供移动环境下的高速率服务,因此其设计目标是最大化传输总带宽 。同时,V2V链路负责周期性传递高级驾驶服务的关键安全消息。对于这样的需求,V2V链路在固定时间约束T内交付率为
(6)
式中B表示周期性生成的V2V有效负载的大小,∆T是信道相干时间, 中的时隙t表示第k条V2V链路传输时不相干时隙的间隔。
因此,本文研究的车联网多信道聚合频谱共享问题可以表述为:设计一个合理的V2V频谱聚合共享策略,用二进制变量 和V2V传输功率 同时最大化V2I链路的总带宽 和(6)中定义的V2V链路的数据交付率。
3. 基于MARL的多信道频谱聚合分配
车辆高移动性带来的复杂环境变化使得集中处理全局CSI不切实际,因此采用分布式来进行决策更加合理。在本研究中,多条V2V链路尝试聚合共享V2I链路占用的有限频谱可以建模为MARL问题。每条V2V链路作为一个agent并与未知环境交互获得经验,然后将其用于更新自己的决策网络。多个agent共同探索环境,并根据自己对环境状态的观察来改善频谱聚合和功率控制策略。本文通过对所有agent设置相同的奖励,将原本的竞争博弈变为了合作博弈。提出的基于MARL的方法分为训练和应用两个阶段,本文将聚焦于集中式训练和分布式应用的设置。在训练阶段,每个agent都可以单独获得以系统性能为导向的奖励,然后通过更新DQN (Deep Q-Network)来使动作决策调整为最优策略。在应用阶段,每个agent基于其本身对于环境的观察,使用与小规模信道衰落相当的时间尺度上根据训练出来的DQN进行动作选择。
3.1. 状态与观测空间
在频谱聚合共享问题的MARL模型中,在时间约束T内,每条V2V链路作为一个agent,按时间步t为周期同时进行未知环境探索 [10] [11]。在数学以按照部分可观察马尔可夫决策过程进行建模。如图2所示,在每个相干时间的时间步t内,给定当前环境状态 ,每个agent观测的环境 由观测函数O确定 ,然后采取一个动作 ,形成一个联合动作 。之后agent收到奖励Rt,环境以概率 进入下一个状态 ,每个agent也能收到新的观测值 ,此时所有的agent共享同一个奖励,以促进他们的合作意识。
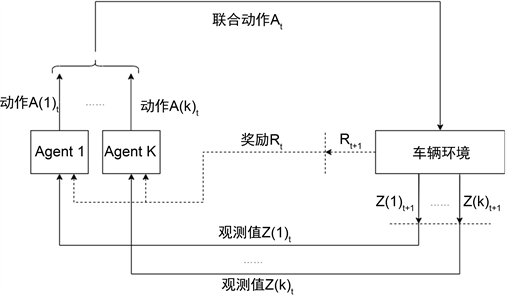
Figure 2. The interaction between agent and vehicular network
图2. Agent与车联网交互
环境状态St包含全局CSI和所有agent的动作,但对于单独的agent来说St是未知的,每个agent只能通过观测函数来获取局部CSI。局部CSI包含agent自身对所有信道的干扰 ,其在信道e上受到其他agent的衰减 ,以及此agent受到V2I链路的衰减 。这些信道信息在每个时隙t开始时由agent提前计算完毕,我们假设这些信息可以被agent即时获取 [12]。而agent对BS的干扰 在每个时隙t开始时在BS处计算,以很小的开销广播给其覆盖范围内所有车辆。(4)中的信道上的干扰功率 可以在agent处获得。此外,观测空间还包括表示agent传输状态的V2V剩余有效载荷 和剩余时间预算 。因此,agent的观测函数表示为
(7)
其中 。
通常在MARL问题中 [13],每个agent将其他agent视为环境的一部分,基于自己的动作和观测进行分布式学习。在DQN训练时,经验回放是必要的步骤,但每个agent面临都是非稳态环境,同时其他agent也在训练并调整他们的动作,这会导致经验回放取样的经验和当前环境相关性不高,DQN训练将很难收敛。为了解决这个问题,在 [11] 中提出了一个低维特征方案来跟踪其他agent的策略变化。其思想是,在每个agent的观测空间里增加其他agent策略的低维特征观测项来促进模型收敛。同时agent的策略由一个高维DQN组成,低维特征代替高维策略可以避免模型复杂度的提升。进一步分析发现,Q-Learning常用的 -greedy策略中,agent的决策变化与训练迭代次数e及其探索速率 高度相关。因此agent的观测函数表示为
(8)
3.2. 动作空间
车联网的多信道频谱聚合共享设计的动作可视为V2V链路的频谱子带聚合位置选择和发射功率控制。如图3所示,频谱分成 条不相交的子带,由B条V2I链路分别占据h条连续信道,K条V2V链路分别独立地选择g条连续信道进行数据传输,每条V2V链路有 种聚合位置选择。出于训练和实际算力的限制,我们将V2V功率控制限制为[18, −100] dBm两个级别,低于V2I链路的23 dBm传输功率。在功率选择中,−100 dBm实际上意味着V2V传输功率为零。同时,对于h和g两个频谱聚合宽度都选取为4个信道。因此动作空间的维度为 ,每个动作对应一种特定的频谱子带聚合位置选择和功率选择的组合。
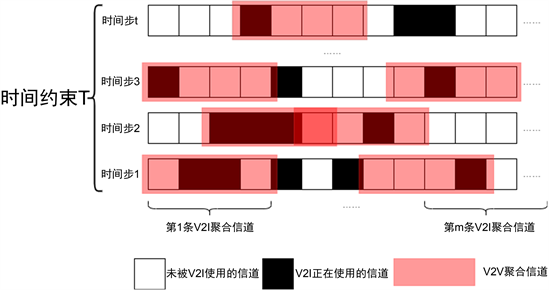
Figure 3. Agent aggregation channel action
图3. Agent聚合信道动作
3.3. 奖励设计
在第2节中说明了本研究有两个实现目标:在时间约束T内,最大化V2I传输总速率的同时,尽可能提高V2V有效负载的交付成功率。针对第一个目标,在每个时间步t中,我们简单地将奖励设为如(4)中定义所有V2I链路的即时总带宽 。为了实现二个目标,对每个agent我们都将奖励 设置为V2V传输速率减去未传输负载 ,直到有效负载交付完成,之后奖励设置为常数 ,其值大于最大的V2V传输速率。因此,每个时间步t的V2V相关奖励设置为
(9)
训练目的是找到一个从状态集合S到动作集合A概率映射的最优策略 ,它使任意初始状态s的预期回报最大化,含折扣率 的累积折扣回报 表示为
(10)
若将折扣率 设置为1,V2V链路的累积奖励越大,传输数据量就越大,直到有效载荷交付完成。因此,当剩余有效载荷 时,最大化累积奖励将会使V2V链路传输更多数据。此外,训练中获得越多 奖励,V2V有效负载的成功传输率就越高。
在训练中,理想情况下 的值要小于调整经验中V2V传输速率最大值的两倍。若将每个时间步t的奖励设置为0,直到V2V有效负载传输完成后奖励变为1,这样agent在每一回合开始时很难得到有效的反馈,模型很难收敛。所以在训练前将先验知识传授给奖励,这样有助于提高V2V有效载荷的成功交付率。当环境干扰过强时,agent会采取加大传输速率的动作,这会造成环境干扰继续加强的负反馈循环。因此,我们提出了(9)中奖励设计,在未完成负载传输时将奖励与传输速率和剩余负载挂钩来避免上述极端的奖励设计。最终每个时间步t的奖励设置为
(11)
其中 和 用来调整V2I 和V2V在设计中的权重。
3.4. 学习算法
在本研究场景中,每个回合开始会初始化包含所有V2V链路初始传输功率和CSI的环境状态,并开始传输大小为B的V2V负载直到时间约束T结束,若负载提前传输完成传输速率会提前降为0。期间小规模信道衰落的变化会改变环境状态,并让每个agent有针对地调整其动作。
1) 集中式训练:我们同时对多个agent采用深度Q-Learning和经验回放 [14] 方法来训练其频谱聚合共享策略。Q-Learning [15] 基于策略 的动作价值函数 ,它被定义为从状态s开始,遵循策略 来进行动作a,表示为
(12)
其中 在(10)中定义。一旦获得动作价值函数,最优策略 也能推导出来 [16]。中表明,随着学习率的随机近似条件变化和所有的状态–动作对不断更新,Q-Learning中训练完成的动作价值函数必将收敛到最优 。在深度Q-Learning [14] 中,用 参数化的深度神经网络DQN表示动作价值函数。
每个agent都有一个专用的DQN,其将当前观测 作为输入,输出所有动作对应的价值。我们进行多次回合来确保DQN训练成功,训练中agent使用 -greedy策略探索状态动作空间,这意味着为了避免收敛到局部最优,除了选出最大估值的动作外还可能以 的概率来随机选取一个动作。因为信道环境一直在变化,所以每个agent都会收集当前时刻转换元组 并存储在回放内存中。在经验回放中,每一回合从内存中均匀地抽取一小批转换元组D通过随机梯度下降方法更新 :
(13)
式中 是目标Q网络的参数集,到达一定回合数后固定从训练Q网络参数集 中复制。训练过程在算法1中总结:
2) 分布式实现:在每个时间步t开始时,每个agent根据 和(8)得出最新的环境观测值Z(k)t,然后通过观测值和训练完的Q网络选出估值最大的动作A(k)t。所有agent按照A(k)t进行发射功率和聚合频谱子带选取并进行传输。
在算法1中,集中式训练可在不同信道环境下离线执行多回合,而低消耗的实现过程可在线执行以进行网络部署。所有agent训练的DQN只需要在环境发生重大变化时进行更新,具体时间取决于环境变化和网络性能要求。
4. 仿真分析
我们按照3GPP TR 36.885 [17] 附录A中定义的城市案例评估方法搭建模拟场景,该方法详细描述了车辆衰落模型、密度、速度、移动方向、车辆通道、V2V数据流量等。表1列出了主要仿真参数,本文所有参数均设置均依照表1。

Table 1. Simulation parameters
表1. 仿真参数
每个agent的DQN由3个全连接的隐藏层组成,分别包含500个、250个、120个神经元。校正线性单元ReLU用作激活函数 。RMSProp优化器 [18] 以0.001的学习率更新神经网络参数。每个agent的Q网络训练3000回合,在前2400回合探索率 从1线性退火降到0.02后保持不变。此外,训练阶段将V2V有效负载大小为2 × 1060 btypes,但测试阶段会改变负载以验证本方法的鲁棒性。
图4是训练时模型的累积奖励,每回合累积奖励随着训练迭代次数不断增加直到趋于稳定,证明所研究的MARL达到收敛状态。从图中可以看出,当训练回合数达到2600左右时,尽管CSI由于车辆移动引起的信道衰落而出现一些性能的波动,但总体趋于收敛。基于对该图的观察,可以推断对Q网络进行3000回合的训练,能保证DQN达到评估V2I和V2V链路性能的标准。

Figure 4. Training accumulative reward
图4. 训练累积奖励
我们将以下两种分布式执行的方法作为baseline,并在图5和图6中与MARL进行比较。一种是基于单代理RL的算法SARL [19],该方法中所有agent共享一个DQN,每一时间步t只有一个agent基于训练的DQN更新其动作,而其他agent的行为保持不变。另外一种方法是随机baseline,在每个时间步t开始时以随机方式为每个agent选择频谱聚合位置和传输功率。
图5显示了不同方法在不同V2V传输负载下V2I的传输性能。在图中可以看出,随着V2V有效负载的增加,所有方案的性能都会下降。V2V有效负载增加会延长V2V传输持续时间和输出更高的V2V传输功率,这将在较长时间内对V2I链路造成更强的干扰。虽然它以2 × 1060字节的固定大小负载进行训练,但这足以证明其对V2V有效负载变化的鲁棒性。MARL方法的性能与baseline比较,传输损失都只在5 Mbps内,性能差距几乎可忽略不计。
图6展现的是不同频谱聚合共享方案在有效负载增大时V2V传输成功率的变化。从图中可以看出,随着V2V有效载荷的增大,MARL方法的传输成功率处于下降趋势,两个baseline方法则一直处于20%到40%的传输成功率区间。与两种baselines分布式方法相比,本文所提出的MARL方法性能具有显著优势。对于小于2 × 1060字节的传输负载,MARL方法的V2V负载传输成功率能高于90%。并且对于3 × 1060字节的传输负载,MARL的传输成功率也能高于75%,而此时的传输负载大小已远远高于V2V所需的传输需求。
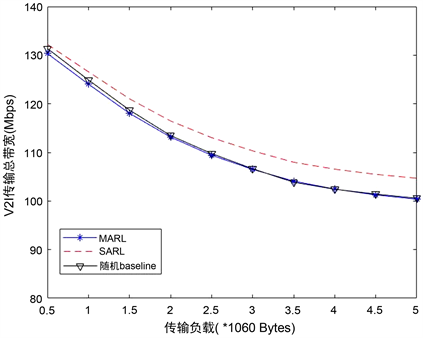
Figure 5. Total bandwidth of V2I transmission
图5. V2I传输总带宽
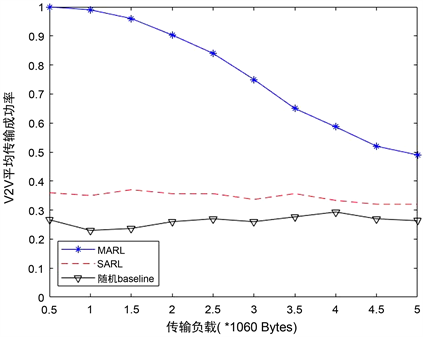
Figure 6. Average transmission success rate of V2V
图6. V2V的平均传输成功率
结合图5和图6来看,MARL方法在基本没有牺牲V2I传输带宽的情况下,大幅度的提升了V2V的传输成功率。我们可以得出结论,MARL方法在传输负载合适的区域内,经过训练的DQN表现良好,但如果V2V传输负债超出适应范围,则DQN需要重新训练。对于当前设置,我们可以得出结论,当数据包大小不大于2 × 1060字节时,不会发现明显的性能损失,即使V2V负载大小突增到3 × 1060字节,V2V的传输成功率也保持在75%以上。即使如此,我们仍然可确定所提出的MARL频谱聚合接入设计的优势,因为即使在未经训练的高负载情况下,它也优于其他两个分布式baseline。
5. 结论
在本文中,我们研究了一种基于MARL的,用于具有多个V2V链路的车联网与其V2I链路共享其频谱。我们所提出的资源共享方案可以有效地鼓励V2V链路之间的合作,在不损失V2I传输性能的情况下,大幅度提高V2V负载的传输成功率。我们未来的工作将包括深入分析和比较SARL和MARL算法的鲁棒性,更好地理解何时需要更新Q网络以及如何有效地执行此类更新,以及尝试采用新的强化学习方法看是否可以提高传输效率。
文章引用
唐嘉程,王辛果. 基于强化学习的多信道车联网频谱聚合共享
Reinforcement Learning-Based Aggregated Spectrum Sharing for Multi-Channel Vehicular Networking[J]. 计算机科学与应用, 2022, 12(12): 2925-2936. https://doi.org/10.12677/CSA.2022.1212297
参考文献
- 1. Li, Y., Zhang, W., Wang, C.-X., Sun, J. and Liu, Y. (2020) Deep Reinforcement Learning for Dynamic Spectrum Sens-ing and Aggregation in Multi-Channel Wireless Networks. IEEE Transactions on Cognitive Communications and Net-working, 6, 464-475. https://doi.org/10.1109/TCCN.2020.2982895
- 2. Poston, J.D. and Horne, W.D. (2005) Discontiguous OFDM Considerations for Dynamic Spectrum Access in Idle TV Channels. First IEEE International Symposium on New Frontiers in Dynamic Spectrum Access Networks, 2005, Baltimore, 8-11 November 2005, 607-610. https://doi.org/10.1109/DYSPAN.2005.1542679
- 3. Botsov, M., Klügel, M., Kellerer, W. and Fertl, P. (2014) Location Dependent Resource Allocation for Mobile Device-to-Device Communications. 2014 IEEE Wireless Commu-nications and Networking Conference (WCNC), Istanbul, 6-9 April 2014, 1679-1684. https://doi.org/10.1109/WCNC.2014.6952482
- 4. Sun, W., Ström, E.G., Brännström, F., Sou, K.C. and Sui, Y. (2016) Radio Resource Management for D2D-Based V2V Communication. IEEE Transactions on Vehicular Technolo-gy, 65, 6636-6650. https://doi.org/10.1109/TVT.2015.2479248
- 5. Ye, H., Liang, L., Li, G.Y., Kim, J., Lu, L. and Wu, M. (2018) Machine Learning for Vehicular Networks: Recent Advances and Application Examples. IEEE Vehicular Technology Magazine, 13, 94-101. https://doi.org/10.1109/MVT.2018.2811185
- 6. Liang, L., Ye, H. and Li, G.Y. (2019) Toward Intelligent Vehic-ular Networks: A Machine Learning Framework. IEEE Internet of Things Journal, 6, 124-135. https://doi.org/10.1109/JIOT.2018.2872122
- 7. Liang, L., Ye, H. and Li, G.Y. (2019) Spectrum Sharing in Ve-hicular Networks Based on Multi-Agent Reinforcement Learning. IEEE Journal on Selected Areas in Communications, 37, 2282-2292. https://doi.org/10.1109/JSAC.2019.2933962
- 8. (2017) Technical Specification Group Radio Access Network. Study Enhancement 3GPP Support for 5G V2X Services. Release 15, Document 3GPP TR 22.886 V15.1.0, 3rd Gener-ation Partnership Project.
- 9. Molina-Masegosa, R. and Gozalvez, J. (2017) LTE-V for Sidelink 5G V2X Vehicular Communications: A New 5G Technology for Short-Range Vehicle-to-Everything Communications. IEEE Vehicular Technology Magazine, 12, 30-39. https://doi.org/10.1109/MVT.2017.2752798
- 10. Omidshafiei, S., Pazis, J., Amato, C., How, J.P. and Vian, J. (2017) Deep Decentralized Multi-Task Multi-Agent Reinforcement Learning under Par Tial Observability. Proceedings of the 34th International Conference on Machine Learning, (ICML), Sydney, 6-11 August 2017, 2681-2690.
- 11. Foerster, J., et al. (2017) Stabilising Experience Replay for Deep Multi-Agent Rein-forcement Learning. Proceedings of the 34th International Conference on Machine Learning, Sydney, 6-11 August 2017, 1146-1155.
- 12. Nasir, Y.S. and Guo, D. (2018) Deep Reinforcement Learning for Distributed Dynamic Pow-er Allocation in Wireless Networks. ArXiv: 1808.00490. https://arxiv.org/abs/1808.00490
- 13. Tan, M. (1993) Multi-Agent Reinforcement Learning: Independent vs. Cooperative Agents. Proceedings of the 10th International Con-ference, University of Massachusetts, Amherst, 27-29 June 1993, 330-337. https://doi.org/10.1016/B978-1-55860-307-3.50049-6
- 14. Mnih, V., et al. (2015) Human-Level Control through Deep Reinforcement Learning. Nature, 518, 529-533. https://doi.org/10.1038/nature14236
- 15. Watkins, C.J.C.H. and Dayan, P. (1992) Q-Learning. Machine Learning, 8, 279-292. https://doi.org/10.1007/BF00992698
- 16. Sutton, R.S. and Barto, A.G. (1998) Reinforcement Learning: An Intro-duction. MIT Press, Cambridge.
- 17. (2016) Technical Specification Group Radio Access Network. Study LTE-Based V2X Services, Release 14, Document 3GPP TR 36.885 V14.0.0, 3rd Generation Partnership Project.
- 18. Ruder, S. (2016) An Overview of Gradient Descent Optimization Algorithms. ArXiv: 1609.04747. https://arxiv.org/abs/1609.04747
- 19. Ye, H., Li, G.Y. and Juang, B.-H.F. (2019) Deep Reinforcement Learning Based Resource Allocation for V2V Communications. IEEE Transactions on Vehicular Technology, 68, 3163-3173. https://doi.org/10.1109/TVT.2019.2897134