Computer Science and Application
Vol.05 No.03(2015), Article ID:15117,11
pages
10.12677/CSA.2015.53009
Multi-Objective Scheduling of Jobs on Parallel Batch Machines with Pareto Algorithm
Chao Wang, Zhaohong Jia, Hao Song
School of Computer Science and Technology, Anhui University, Heifei
Email: wangchao6439@foxmail.com
Received: Apr. 5th, 2015; accepted: Apr. 22nd, 2015; published: Apr. 27th, 2015
Copyright © 2015 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
In this paper, the batch scheduling problem is extended to the multi-objective (sumCj, MOC) batch scheduling problem. The scheduling problem is divided into two stages: batching and batch scheduling. In the batching process using the traditional BFLPT batch rule to obtain the batching results; while in the batch scheduling process, for the multi-objective function, this paper not only presents improved evolutionary algorithm Improved-NSGA-II to solve the multi-objectives minimization problem, but also lists the algorithms of NSGA-II and SPEA2 as the contrast. Through the simulation experiment, to compare the three algorithms in three aspects, respectively from the number, the quality and the running time of Pareto solution set, this paper proves the effectiveness of the Improved-NAGS-II algorithm.
Keywords:Ulti-Objective, Batch Scheduling, Pareto Solution Set, MOC,
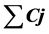

使用帕累托方法解决多目标平行机批调度问题
王 超,贾兆红,宋 浩
安徽大学计算机科学与技术学院,安徽 合肥
Email: wangchao6439@foxmail.com
收稿日期:2015年4月5日;录用日期:2015年4月22日;发布日期:2015年4月27日

摘 要
本文将批调度问题扩展到针对多目标(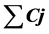 , MOC)的批调度问题,这一调度问题分为两个阶段:分批和批调度。分批过程使用的是传统的BFLPT分批规则,得到分批结果;而批调度过程中,针对多个目标函数,本文提出了改进型进化算法Improved-NSGA-II来完成多目标的极化问题,同时列举了算法NSGA-II和SPEA2作为对比。通过仿真实验,分别从帕累托解集的数量、质量和算法运行时间三个方面对三种算法进行比较,从而证明算法Improved-NAGS-II的有效性。
, MOC)的批调度问题,这一调度问题分为两个阶段:分批和批调度。分批过程使用的是传统的BFLPT分批规则,得到分批结果;而批调度过程中,针对多个目标函数,本文提出了改进型进化算法Improved-NSGA-II来完成多目标的极化问题,同时列举了算法NSGA-II和SPEA2作为对比。通过仿真实验,分别从帕累托解集的数量、质量和算法运行时间三个方面对三种算法进行比较,从而证明算法Improved-NAGS-II的有效性。
关键词 :多目标,批调度,帕累托解集,MOC,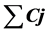

1. 引言
批处理机(Batch processing machine, BPM)调度问题兴起于二十世纪九十年代初,是从半导体生产过程的最后阶段中提炼出来的一种新型调度问题,具有广泛的应用背景(Uzsoy, 1994 [1] ; Dupont and Ghazvini, 1998 [2] ; Melouk et al., 2004 [3] )。平行机批处理是一个非常传统的研究分支,也是调度问题的一个重要分支。于经典调度问题不同的是,一个机器加工多个工件。因为这类问题不仅要把工件按要求分配到机器上,还要把工件按照不同的规则分批。这类问题要比经典调度复杂的多,已知的批调度问题都是NP难问题。从现有的文献调查平行机批调度问题去解决的目标有最小化最大完工时间、总加工时间、总成本等等。找到正确的工件分配序列来满足上面的多个目标问题的约束仍是个具有挑战的任务。
目前有大量的研究人员对上述的目标问题进行研究,发现的各种确定性和不确定性类型方法来解决上述问题。如线性规划、遗传算法[4] 、动态规划、整数编程、蚁群优化[5] 、微粒群(Patrical Swarm Optimization, PSO)算法[6] 、模拟退火等等。
现在关于批调度的研究通常集中在生产效率和完工时间相关的目标上,此类目标倾向于找到较早或按时完工的方案,总体上与客户满意度相关。而在另一方面,制造商所关注的利润成本上的研究较少。在当前的绿色背景下,能源所占的比重较增大,成本更应成为评价调度的重要指标。
在考虑到成本目标的双目标平行机批调度比传统的单目标批调度更为复杂的组合优化问题,本文在此基础上提出双目标(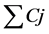 , MOC)。其中
, MOC)。其中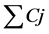 为工件的总加工时间,MOC是每台机器上工件加工时所产生的成本。工件加工分为两个阶段:分批,批调度。本文的重点集中在批调度中,采用两种最新的多目标进化算法进行求解最优帕累托解集。并在此基础上提出一种新的进化算法Improved-NSGA-II。
为工件的总加工时间,MOC是每台机器上工件加工时所产生的成本。工件加工分为两个阶段:分批,批调度。本文的重点集中在批调度中,采用两种最新的多目标进化算法进行求解最优帕累托解集。并在此基础上提出一种新的进化算法Improved-NSGA-II。
本文的第二章对问题进行详细描述,介绍了问题的一些概念和对应的数学模型;第三章介绍三种进化算法(NSGA-II、SPEA2及Improved-NSGA-II算法);第四章设计算例,进行实验仿真,对比各算法的实验结果,分析得出结论;文章的最后说明了接下可以继续研究的方向。
2. 问题描述
2.1. 问题模型
本文研究的多目标调度问题可具体描述如下:
(1) 给定m台机器平行机的集合M,n个工件的集合为N,每个工件可以分配到任一个机器上加工。
(2) 机器为批处理机,其容量为C,单个工件尺寸不会超过机器容量且批内工件尺寸之和小于批的容量。
(3) 分批后用B表示批集合,b表示批。批的加工时间为批内工件的最大的加工时间,批的尺寸为批内工件尺寸之和,批的加工成本为批内工件加工成本之和。且批在加工过程中不允许中断,也不允许加入新的工件。
(4) 优化目标位( , MOC),求出在两目标最优的解集。
, MOC),求出在两目标最优的解集。
2.2. 数学模型Pm|sj,cj,batch| ( , MOC)
, MOC)
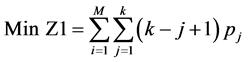 (1)
(1)
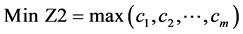 (2)
(2)
s.t.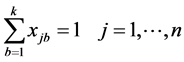 (3)
(3)
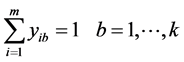 (4)
(4)
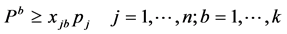 (5)
(5)
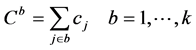 (6)
(6)
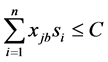 (7)
(7)
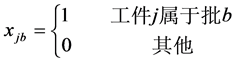 (8)
(8)
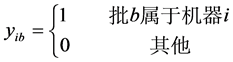 (9)
(9)
其中(1)最小化第一个目标函数,总完工时间等于所有机器上的总完工时间。(2)最小化第二个目标函数,最大完工时间等于m台机器中最大的完工时间。(3)表示每个工件只能由一个机器加工。(4)表示每个批只能由一个机器加工。(5)批的加工时间等于批内工件的最大加工时间。(6)批的加工成本等于批内所有工件加工成本。(7)批内所有工件的尺寸之和小于等于批的空间。(8)和(9)约束决策变量只能取0或1。
2.3. 多目标优化的基本概念
设有r个优化目标,且这些目标间互相冲突,在一个目标上优化会使另一个目标变差。优化目标表示为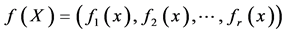 多目标优化中的最优解一般称为pareto最优解。
多目标优化中的最优解一般称为pareto最优解。
给定一个多目标问题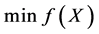 ,这个问题的解空间
,这个问题的解空间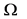 。若
。若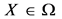 ,且不存在其他的
,且不存在其他的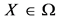 使
使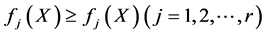 成立,且其中至少有一个严格的不等式成立,则X是
成立,且其中至少有一个严格的不等式成立,则X是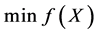 的pareto最优解。
的pareto最优解。
个体间的支配关系:p和q是多目标问题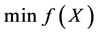 的两个不同解,若同时满足以下两个条件,则称p支配q,符号表示为
的两个不同解,若同时满足以下两个条件,则称p支配q,符号表示为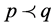 。
。
(1) 对所有的优化目标,p不比q差,即为 。
。
(2) 至少有一个目标,p在该目标上的值小于q。即为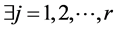 ,使
,使 。
。
3. 算法介绍
多目标批调度问题分为两个步骤,一是分批过程,一个是批处理过程,以优化MOC和makespan 为目标。这两个问题都是NP难问题,本文在分批中使用BFLPT规则,以减轻计算的复杂度。文章的侧重点在批调度过程,下面介绍本文在批调度阶段使用的几个算法的流程。
3.1. BFLPT介绍
多目标调度中分批过程也是很重要的阶段,介于本文研究问题的特征,选择了BFLPT (best-fit longest processing time)启发式规则,它是由L. Dupont等[7] 已提出的,并且在后续的研究中被广泛使用,能够得到较优的分批方案,具体步骤如下:
算法BFLPT:
(1) 加工件按加工时间pi非递增排序,得到工件序列L;
(2) 从序列L选择工件,放入可行批中,使该批的剩余空间最小;如果没有可以放入的批,则重新创建一个批,将工件放入进去,更新批属性。重复步骤2直到所有工件都分配到批中。
(3) 将批排序,随机分配到机器上加工。
这一启发式式算法,前两步完成分批操作,通常根据不同的问题修改第三步的机器选择策略,从而能得到较优的目标函数解。
3.2. NSGA-II介绍
NSGA-II (Non-dominated Sorting Genetic Algorithm II) [8] 是Deb et al. [9] 在2012年提出的基于多目标的进化算法,相对于此前版本NGSA [10] (Srinivas and Deb, 1994)的一点缺点,主要有以下几个优点。一是它改进了Pareto最有解集的构造,同时降低的时间复杂度。二是加入的精英保留机制[11] ,在搜索过程中更好的保留住非支配解集。三是解决多目标问题的参数共享问题。
3.2.1. 编码与解码
每个染色体都代表所有批的序列,每个批都有原始的序列号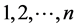 。则这个染色体的长度为n ´ (n/2 + 1),染色体上每(n/2 + 1)位上存储一个批的序列号。在编码时将按一定初始顺序将每个批的序列号转为(n/2+1)位的二进制码。在解码时进行反转即可。
。则这个染色体的长度为n ´ (n/2 + 1),染色体上每(n/2 + 1)位上存储一个批的序列号。在编码时将按一定初始顺序将每个批的序列号转为(n/2+1)位的二进制码。在解码时进行反转即可。
3.2.2. 算法的基本流程
首选随机产生一个新的初始种群A。然后对其进行竞标赛选择,变异,交叉操作后形成一个新的种群B。将种群A和种群B合并成为一个具有2n个染色体的种群C。
对种群C进行构造其边界集[12] 。并在其中某个边界集上计算所有个体的聚集距离,以此来建立这个边界集上的个体偏序关系。以此为基础,从C中选择出n个染色体进入新一代种群A。重复上述过程直到到达预定的迭代次数或指定的条件。
3.2.3. 边界集的构建(图1)
边界集的定义:群体C中有N个解,按照某种策略分类为m个子集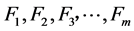 ,若满足下列心智,则这些子集构成群体C的m级边界集:
,若满足下列心智,则这些子集构成群体C的m级边界集:
(1)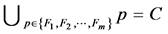 ;
;
(2)
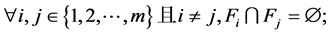
(3) 即
即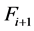 中的个体直接受Fi中的某个个体支配。
中的个体直接受Fi中的某个个体支配。
在NSGA-II中,为了从现有的种群中选择高质量的个体进入新一代种群,需要对种群构造边界集。
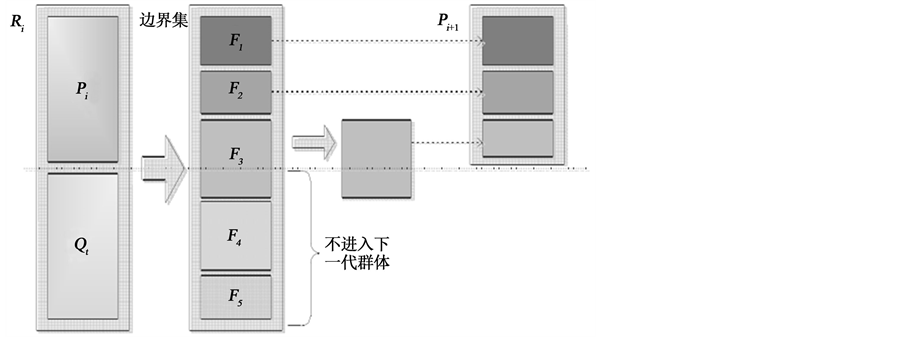
Figure 1. Construction of boundary set
图1. 边界集构建
设对于每个个体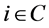 有两个变量si和ti,其中si记录种群中支配个体i的个体数,ti记录被i支配的个体集合,即
有两个变量si和ti,其中si记录种群中支配个体i的个体数,ti记录被i支配的个体集合,即
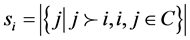

构造边界集时,先为每个个体计算出si和ti,算法的伪代码如下,然后构造边界集。
//计算si和ti
do while
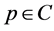
do while
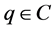
if

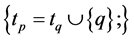
else if

end while
end while
//构造边界集
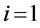 ;
;
While
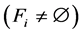
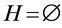 ;
;
do while
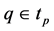
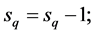
if

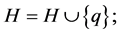
End while
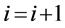 ;
;
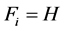 ;
;
End while
3.2.4. 聚集距离计算
设Fi代表边界集i内的染色体数目,其满足以下条件:
1)
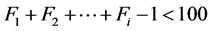
2)
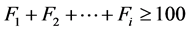
如图上所示比Fi高的边界集内的染色体全部进入下一代,并在Fi内选择100 −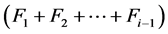 个染色体进入下一代,选择规则即是聚集距离(图2)。
个染色体进入下一代,选择规则即是聚集距离(图2)。
聚集距离用于区分同一边界集上的个体好坏,公式为:
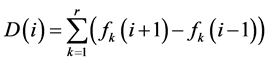
根据目标k上的值为每个个体排序,r代表目标个数,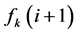 与
与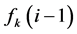 代表目标k在与i相邻的两个个体的函数值。
代表目标k在与i相邻的两个个体的函数值。
3.3. SPEA2介绍
SPEA2 [13] 算法是在SPEA (Strength Pareto Evolutionary Algorithm) [14] 基础上进行改进,解决多目标问题的帕累托算法。最初的SPEA算法,将每个个体的适应度称为Pareto强度,首先把算法每次迭代过程中产生的所有个体的值进行适应度定义,并设定一个外部的种群来保留当前进化群体中较优秀的个体。本文用此算法解决调度此调度问题,其编码与解码和NSGA-II相同。
算法SPEA2:群体P的规模为N,存档集Q为M,迭代次数为T;
(1) 随机产生一个存档集和初始种群Q0,P0。迭代器 ;
;
(2) 为PT与QT中的个体计算适应度;(3.3.1)
(3) 将PT与QT里的所有非支配个体保持入下一代存档集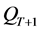 中,若此时
中,若此时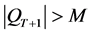 ,则利用修剪去除多余的个体;若
,则利用修剪去除多余的个体;若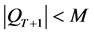 ,则在PT和QT中按一定的规则选择一些个体加入
,则在PT和QT中按一定的规则选择一些个体加入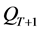 ,使
,使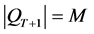 ;(3.3.2)
;(3.3.2)
(4) 若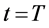 或满足其他终止条件,输出
或满足其他终止条件,输出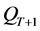 中的非支配解为算法结果;
中的非支配解为算法结果;
(5) 对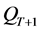 执行竞标赛选择,交叉和变异,把结果保持到PT+1中,
执行竞标赛选择,交叉和变异,把结果保持到PT+1中,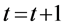 ,转入(2)。
,转入(2)。
3.3.1. 适应度分配
为了使每个个体拥有不同的适应度值,同时考虑在迭代中的群体和外部群体的所有的个体的情况,通过计算个体与它相邻的个体间的距离来确定拥挤情况,即计算群体PT(初始集)和QT(存档集)中每个个体的适应度,本文分为两个方面讨论。总适应度F(i)由R(i)和D(i)综合决定:
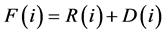
其中R(i) (图3)是整数部分,R(i)的计算公式如下:
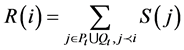
其中S(j)为群体Pt和Qt中j支配的个体数。R(i)越低代表解的质量越好,D(i)是小数部分,其计算公式如下:
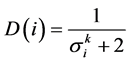 其中
其中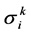 是个体i到其第k个最近个体的距离,分母加2是为了是距离不为0,且
是个体i到其第k个最近个体的距离,分母加2是为了是距离不为0,且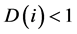 ,其中k为
,其中k为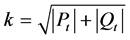 。对外部种群的维护,选择当前迭代种群和外部种群的非支配解集,当外部种群的数量大于我们预设的值时,删除外部种群中较差的个体。否则选取迭代中的种群中较好的个体进行补充。重复这个过程,直到外部种群的规模达到我们预先设定的值。虽然没有降低算法的复杂度,但由于考虑了每个个体的拥挤情况,可以得出的结果有着更均匀的分布。
。对外部种群的维护,选择当前迭代种群和外部种群的非支配解集,当外部种群的数量大于我们预设的值时,删除外部种群中较差的个体。否则选取迭代中的种群中较好的个体进行补充。重复这个过程,直到外部种群的规模达到我们预先设定的值。虽然没有降低算法的复杂度,但由于考虑了每个个体的拥挤情况,可以得出的结果有着更均匀的分布。

Figure 2. Gathering distance calculation
图2. 聚集距离计算
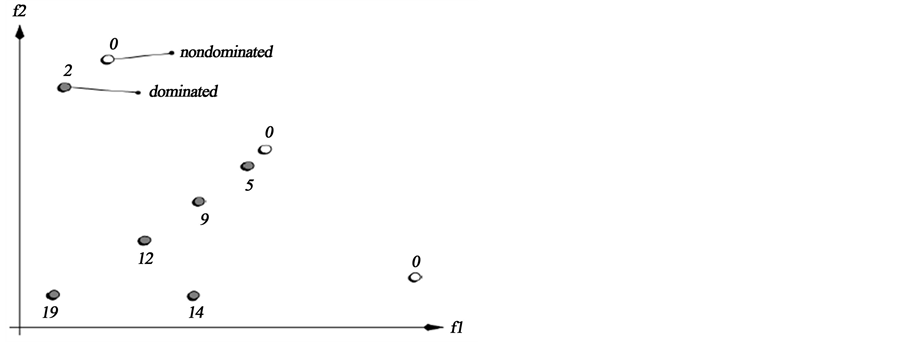
Figure 3. Fitness Ri calculation
图3. 适应度Ri计算
3.3.2. 环境选择
从群体PT和存档集QT中选择合适的个体存入下一代存档集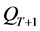 中,首选对PT和QT中
中,首选对PT和QT中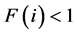 的(即非支配个体)存入
的(即非支配个体)存入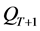 。如果
。如果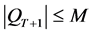 ,则从PT和QT中选择剩余F(i)最小的加入,直到
,则从PT和QT中选择剩余F(i)最小的加入,直到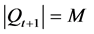 。如果
。如果 ,则利用存档修剪不断删去
,则利用存档修剪不断删去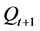 中的个直到
中的个直到 。利用
。利用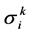 发现个体间的距离,删去与选择个体距离最小的个体(图4)。
发现个体间的距离,删去与选择个体距离最小的个体(图4)。
3.4. 基于改进型NSGA-II的批调度算法
前文介绍过在批调度多目标算法中,我们将算法分为两个阶段。而在批调度阶段,用进化算法来求问题的解。本文在此NSGA-II的基础的上进行改进,在批调度的种群迭代中加入一个启发式算法,优化种群中的每个个体。
3.4.1. 改进策略
在批处理阶段,将批分批到每台机器上加工。对本文的目标问题(XQMOC),我们可以通过分级思想,来确保第一个目标不变的情况下来优化第二个目标。在NSGA-II的进化算法中,对于每代种群中的个体
我们都将对其进行优化。在种群的迭代过程中,通过进化算法在每次种群迭代结束后,都能得到更优的个体,然后将更优的个体放于下一代中。
算法Improved-NSGA-II的流程如图5所示。
3.4.2. 批处理阶段的启发式算法
在批分配阶段,应用启发式算法主要考虑以下三个方面:
①种群的迭代过程中得到的各个个体的批序列;
②基于分级思想调整每级上的工件顺序,将排好序的批分配到各机器上;
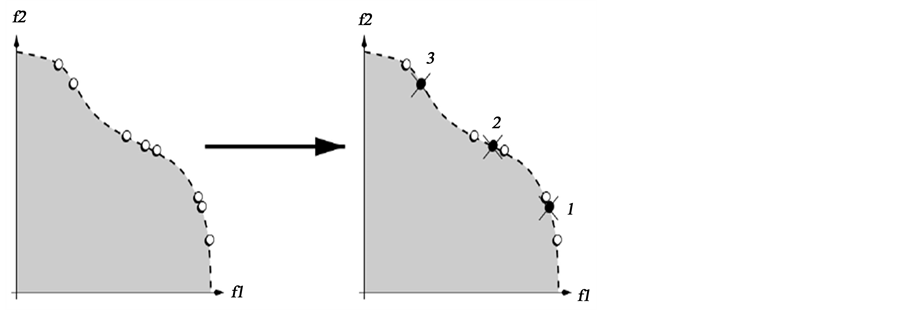
Figure 4. Trim archive collection
图4. 存档集的修剪
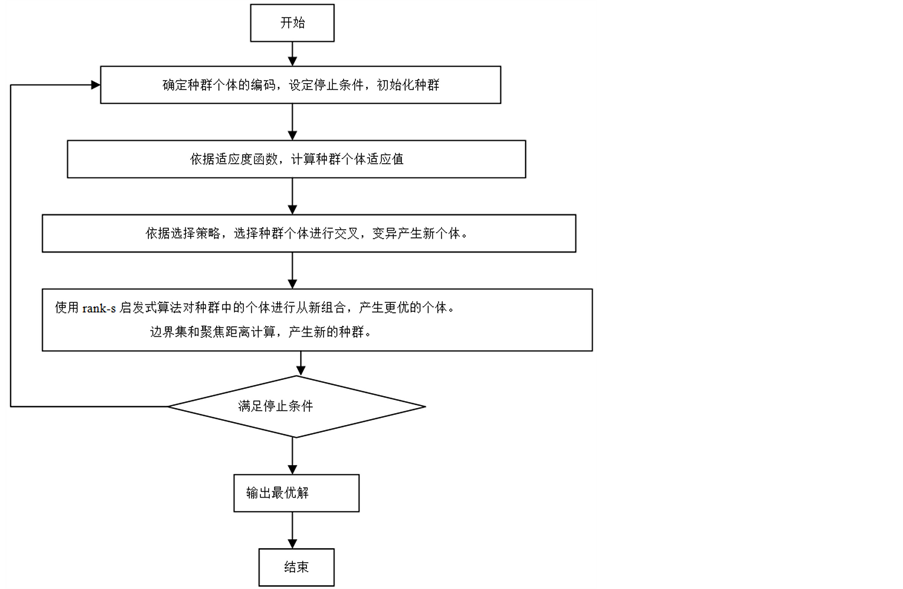
Figure 5. Algorithm process diagram
图5. 算法流程
③我们使用启发式算法调整得到:在保证第一目标总完工时间不变的基础。
上考虑如何最小化第二目标:机器的最大加工成本MOC。
算法步骤如下:
(1) 在经过一次交叉变异后,我们得到一个种群。解码得到每个种群个体的批序列,将批按照自定好的序安放在机器上,则批数量 ;
;
(2) 将最后m个批分配到最后一级上,将倒数第2 m个批分配到倒数第二级上,基于帕累托方法的多目标平行机批调度问题直到分完 个批到
个批到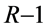 级上,最后将剩下的x个工件分配到第一级上;
级上,最后将剩下的x个工件分配到第一级上;
(3) 从第二级开始,将当前级上加工成本最大的批放到前一级中机器加工成本最小的机器上,执行此过程直到最后一级第R级为止。
从启发式算法rank − s对每个种群的个体进行改进,可以保证个体的第一个目标不变的情况下,达到优化第二个目标的目的。再把优化后的群体按照NSGA-II进行选择,对于每一代的群体都要进行优化,这样我们每代可以得到更优的个体。
4. 实验设计与结果分析
4.1. 实验设计
通过仿真实验来比较几个多目标算法。实验中算例的生成主要考虑一下几个方面:工件数量,加工时间,加工成本,机器数量(表1)。
4.2. 算法参数设置
通过初步的实验,我们得到三种算法在以下参数的设置情况可以得到较为理想的结果参数设置参照以下列表(表2):
所有算法在eclipse平台下运行,硬件为dual core 2.3Ghz处理器,2G内存。每种算法运行10次实例。
4.3. 算法的评价指标
为了衡量三种算法在不同情况下的表现,我们在实验中釆用以下的几种指标来评价算法的性能。
(1) 非支配解集的质量,各个算法得到非支配解集的质量是一个非常直观的指标,能很清晰表明算法在某种情况下的表现。优质的帕累托解集更加接近边界的近似值。
(2) 帕累托的解集数量,即是各个算法得到的非支配解集的规模。解集的数量越多,我们也就有着越大的选择空间,从而可以更好的构造帕累托曲线,得到更优的解决方案。
(3) 算法所运行的时间,因为这类问题都是NP难问题,求解的时间很大程度上可以看出一个算法的好坏。

Table 1. Parameter settings of jobs and machines
表1. 工件机器参数设置表
4.4. 实验结果与讨论
在表3中我们列出了几种算法在不同情况下找到的非支配解的个数。在类型列第一个数值代表工件
Table 2. Algorithm parameters
表2. 算法参数表
Table 3. The compare of three algorithms’ results
表3. 三种算法解数量的实验结果对比
数,第二个数值代表机器数,第三个数值代表工件尺寸。其中MAX、AVG、MIN,在列表中示几种算法在运行过程中找到非支配解的最大值、平均值、和最小值。从数据中,我们可以看出,在工件数较小的情况下,几种算法的性能都差不多。但当随着工件的增加,在大规模的工件中NSGA-II相对于SPEA2可以找到更多的解集。而Improved-NSGA-II又比NSGA-II要有更好的效果。因为存档集的原因,SPEA2的非支配解集是从存档集中找出的,因此我们得到的非支配解集的规模是不可能大于存档集的规模的。总体来看,找到的非支配解集的数量是随着工件规模的增加而增加的,因为解空间的增加会找到更多符合帕累托曲线的解集。
表4中列出了三种算法的运行时间,单位为秒(s)。从表中我们可以看到,但工件数位20时,三种算法的运行时间并没有太大的区别。但随着问题规模的增大,Improved-NSGA-II的运行时间相较与NSGA-II和SPEA2有着明显的增大。这是因为,我们在NGSA-II中加入了mnk-s的分级算法,此算法在随着层次的增加,加工时间会曾显指数级增长。NSGA-II和SPEA2只需通过交叉变异来选出优秀个体。这两则间,SPEA2在所有的算例的时间上都要长于NSGA-II,这是因为SPEA2的复杂度是由存档集M和种群N共同决定的,而NSGA-II的时间幵销只是由种群的规模N决定的。这是NSGA-II要更快点。
5. 总结
本文从该问题的模型特征入手,针对调度过程中的两个阶段分批阶段和批调度阶段。使用了两种进
Table 4. The compare of three algorithms’ running time
表4. 三种算法运行时间的实验结果对比
化算法NSGA-II和SPEA2,并在此基础上提出了Improved-NSGA-II算法。这三个算法主要用的批调度阶段,我们从解的质量,解的数量和算法运行时间三个方面进行了比较。实验结果表明在工件集较小的时候三个算法的加工时间基本相同,而Midified-NSGA-II有较优的解。而随着工件数量的增加,Midified-NSGA-II的运算时间较其他两个进化算法也会快速增加。本文得出的结论,Midified-NSGA-II在工件集较小,机器台数较多时,获得的非支配解集优于SPEA2和NSGA-II。而SPEA2和NSGA-II在工件规模大的时候有着更优的运行时间。
对于未来的研究,可以从这几个方面进行:在工件加工时间,加工成本和工件尺寸三个维度上进行进一步的研究,使分布更加均匀,来提高解集的质量;本文提出Midified-NSGA-II算法在面对工件集数量较多时,运行时间方面的效果并不是很好,还有着较大的改进空间;对于工件分级思想上可以找到新的方法来降低时间复杂度,这也是接下来工作的主要方向。
文章引用
王 超,贾兆红,宋 浩, (2015) 使用帕累托方法解决多目标平行机批调度问题
Multi-Objective Scheduling of Jobs on Parallel Batch Machines with Pareto Algorithm. 计算机科学与应用,03,62-73. doi: 10.12677/CSA.2015.53009
参考文献 (References)
- 1. Uzsoy, R. (1994) Scheduling a single batch processing machine with nonidentical job sizes. International Journal of Production Research, 32, 1615-1635.
- 2. Dupont, L. and Ghazvini, F.J. (1998) Minimizing makespan on a single batch processing machine with non-identical job sizes. European Journal of Automation, 32, 431-440.
- 3. Melouk, S., Damodaran, P. and Chang, P.Y. (2004) Minimizing makespan for single machine batch processing with non-identical job sizes using simulated annealing. International Journal of Production Economics, 87, 141-147.
- 4. 席裕庚, 柴天佑, 恽为民 (1996) 遗传算法综述. 控制理论与应用, 06, 697-708.
- 5. 刘彦鹏 (2007) 蚁群优化算法的理论研究及其应用. 浙江大学, 杭州.
- 6. 杨维, 李歧强 (2004) 粒子群优化算法综述. 中国工程科学, 05, 87-94.
- 7. Dupont, L. and Dhaenens-Flipo, C. (2002) Minimizing the makespan on a batch machine with non-identical job sizes: An exact procedure. Computers & Operations Research, 29, 807-819.
- 8. Deb, K., Pratap, A., Agarwal, S., et al. (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation, 6, 182-197.
- 9. Deb, K., Agrawal, S., Pratap, A. and Meyarivan, C. (2000) A fast elitist non-dominated sorting genetic algorithm for multiobjective optimization: NSGA-II. Proceedings of the Parallel Problem Solving from Nature VI Conference, 849- 858.
- 10. Deb, K. and Srinivas, N. (1994) Multiobjective optimization using nondominated sorting in genetic algorithms. Evolutionary Computation, 221-248.
- 11. Zitzle, E. and Thiele, L. (1999) Multiobjective evolutionary algorithms: A comparative case study and the Strength Pareto approach. IEEE Transactions on Evolutionary Computation, 3, 257-271.
- 12. 舒锋 (2011) SAGA算法在差异工件平行机批调度问题中的应用研究. 中国科学技术大学, 合肥.
- 13. Zitzler, E., Laumams, M. and Thiele, L. (2001) SPEA2: Improving the strength Pareto evolutionary algorithm: Evolutionary Methods for Desigri. Optimization and Control with Applications to Industrial Problems, Athens, 95-100.
- 14. 杜冰 (2011) 批处理机调度问题的模型与优化方法研究. 中国科学技术大学, 合肥.