Computer Science and Application
Vol.
12
No.
04
(
2022
), Article ID:
49979
,
12
pages
10.12677/CSA.2022.124080
基于实例的多视角多标签学习算法
苏可政1,肖燕珊1,刘波2
1广东工业大学,计算机学院,广东 广州
2广东工业大学,自动化学院,广东 广州
收稿日期:2022年3月1日;录用日期:2022年3月30日;发布日期:2022年4月6日

摘要
在多视角多标签学习中,一个实例可以由多个数据视角表示,并与多个类标签相关联。目前现有的多视角多标签学习算法研究的是变量与类标签之间的关系。在这篇文章中,我们提出了一种基于实例的多视角多标签学习算法。与现有的多视角多标签算法不同,我们利用训练实例和测试实例的相关性进行建模。在多视角多标签学习中,数据来自多个视角。在每个视角中,通过构建偏最小二乘回归模型来探索训练实例和测试实例之间的相关性,而不是像传统的多视角多标签学习算法一样探索变量和类标签之间的映射函数。因此,我们可以从多视角数据中学习到多个偏最小二乘回归模型。此外,为了保证不同视角的一致性,在多个回归模型中加入视角一致性约束。对比实验表明,与现有的多视角多标签算法相比,所提算法获得了更好的分类结果。
关键词
偏最小二乘(PLS)回归,多视角多标签学习,视角一致性

Multi-View Multi-Label Learning by Exploiting Instance Correlations
Kezheng Su1, Yanshan Xiao1, Bo Liu2
1Department of Computer, Guangdong University of Technology, Guangzhou Guangdong
2Department of Automation, Guangdong University of Technology, Guangzhou Guangdong
Received: Mar. 1st, 2022; accepted: Mar. 30th, 2022; published: Apr. 6th, 2022

ABSTRACT
In multi-view multi-label learning, an instance can be represented by multiple data views, and associated with multiple class labels. The existing multi-view multi-label learning works explore the relationship between the variables and the class labels. In this paper, we present an instance-based multi-view multi-label learning algorithm. Different from the existing multi-view multi-label algorithms, we model the correlations of training instances and testing instances. In multi-view multi-label learning, the data is from multiple views. In each view, we build a partial least square regression model to explore the correlation between the training instances and the test instances, rather than the mapping function between the variables and the class labels. As a result, we can learn multiple partial least square regression models from multi-view data. Moreover, in order to ensure the mutual agreement on distinct views, a view consensus constraint is proposed based on the multiple regression models. The comparison experiments show that our algorithm obtains better classification results in comparing with the state-of-the-art multi-view multi-label algorithms.
Keywords:Partial Least Square (PLS) Regression, Multi-View Multi-Label Learning, View Consensus

Copyright © 2022 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
在多标签学习中,每个对象都与多个类标签相关联。这些类标签是相关的,每个类标签通常与其他类标签相互依赖。多标签学习的目标是基于类标签的相关性构建一个分类模型 [1]。近几年,多标签学习在很多场景中得到了广泛的应用,例如图像分类 [2],文本识别 [3],情绪分类 [4] 和社交网络挖掘 [5]。然而,在多标签学习中仍然存在两个开放性的挑战:1) 如何利用相关性有效地建立模型;2) 如何有效地处理多标签数据的高维问题。目前,已经有许多算法被提出用来解决第一个挑战 [6] [7] [8] [9] [10],然而这些算法的复杂度相对较高 [11]。对于第二个挑战,有两种解决方案:特征选择和降维。但是特征选择忽略了标签之间的相关性,传统降维的结果可解释性也很差。为了解决这些问题,Liu等人提出了一种基于实例的稀疏的加权多标签学习算法SWIM [12]。SWIM采用偏最小二乘(PLS)回归来研究训练集实例和测试集实例的相关性。SWIM将实例映射到一个潜在空间中,可以更有效地降维,从而解决高维问题 [13]。实验结果已经证明SWIM的分类效果明显高于对比的其他多标签学习算法。
尽管SWIM有更好的性能,但是它是用于解决单视角多标签学习问题的,不能直接用在多视角多标签学习数据上。而在现实中,可以从多个不同的方面来描述一个对象。例如,在web图像检索中,一个实例可以用两个特征集来描述:图像的视觉特征以及用于描述图像的文字特征。另外,在图像分类中,我们可以用多个不同的特征集合来描述一幅图像,例如RGB,SIFT和GIST [14]。在这些应用中,一个对象与多个特征集合(即多个视角)相关联,并且每个视角表示了同一对象的不同方面。因此,一个视角可能包含了其他视角所没有的一些独特的分类信息 [15] [16]。这表示,相较于在每个视图中分别训练单独的分类器,利用不同视角的一致性和互补的信息来建立模型会拥有更好的性能 [17] [18]。SWIM在每个数据视角中单独学习对应的多标签分类器,所以只能用于解决单视角多标签学习。它不能利用不同视角的一致性和互补信息来提高分类器的性能。
综上所述,我们提出了一种包含了多个视角的一致性和互补信息的模型,用来提高多标签分类器的性能。具体而言,考虑到每个对象都用多个视角表示,我们采用PLS回归算法将多视角实例映射到多个潜在空间中,从而可以在降维的同时构建多标签分类器,从而更好地解决高维问题。此外,为了保证不同视角的一致性,基于PLS回归模型提出了视角一致性约束,提高了分类器的性能。我们工作的主要贡献如下:
1) 我们首次提出了一种新颖的算法,基于实例的多视角多标签学习算法,该算法能够将多视角的一致性和互补性信息整合到多标签分类器中,以提高多标签学习的分类性能。
2) 将模型转化为LASSO (Least absolute shrinkage and selection operator)问题,并采用NIPALS (Non-linear iterative Partial Least Squares)求解相应的优化问题。
3) 现有的多视角多标签模型研究变量与标签之间的相关性,而我们的算法却是对训练实例和测试实例的相关性进行研究和建模。大量的实验表明,提出的算法相较于现有的算法具有更好的性能。
2. 基于实例的多视角多标签学习算法
2.1.算法框架
给定一个有n个已标记样本的多视角多标签学习训练集 ,其中 和 分别是视角A和视角B的特征向量。 的上标A和B指的是第i个实例( )的两个视角。在对视角多标签学习中,一个样本 有多个标签,因此有 ,其中 为样本 的第j个标签。此外, 和 分别是 和 的矩阵。 是一个 的矩阵,其中 是样本 的类标签。 和 分别是两视角多标签数据集的视角A和视角B数据集。让 和 ,其中数据集D的下标s和t分别表示训练集和测试集。
我们提出的基于实例的多视角多标签学习算法的框架图如图1所示。定义训练集为 和测试集为 ,且 。目前的多视角多标签学习方法根据变量和类标签之间的函数关系构造模型 [15] [16] [17] [18] [19]。在多视角多标签数据集中,训练集 和测试集 的数据分布是相同的,这意味着,如果可以得到训练集 的变量和类标签之间的映射关系(即图1的 和 ),那么映射函数 和 可以分别被直接应用在数据集 和 里。综上所述,如果 是 和 之间的映射函数(即, ),我们就可以利用它来得到 的预测标签,即 。

Figure 1. General diagram of algorithm
图1. 算法框架图
与上述的多视角多标签不同,我们所提的算法利用了不同的映射方式来构造模型:确定训练示例 和测试示例 之间的函数关系 ,并通过 来构造模型(即图1的 和 )。该映射方法的工作原理如下:变量空间 和类标签空间Y是同一个示例的输入空间和输出空间,它们具有相同的关联性,因此同一个数学定理既可以应用在变量空间 上,也可以应用在类标签空间Y上。综上所述,当得到训练示例 和测试示例 之间的映射函数 后(即 ),映射函数也可以应用在 和 上,即: 。因此,我们分别利用 和 为数据集 和 建立分类模型。
2.2. 构建模型
设 和 分别为 和 的转置矩阵, 为Y的转置矩阵。此外,设 和 分别为 和 的矩阵,其中 和 分别是训练集和测试集里示例的个数,而 是视角A里示例的维数。类似的, 和 分别为 和 的矩阵,其中 是视角B里示例的维数。设 和 分别为 和 的矩阵,其中q是标签空间的维数。
和 拥有相同的数据分布,所以存在一个共同的潜在的实例空间,它们拥有相似的特征。因此,我们利用PLS来探索两个潜在空间,其中一个潜在空间来自于 和 ,而另一个则来自于 和 。且 ,, 和 可以表示为如下形式:
(1)
(2)
(3)
(4)
其中 和 分别是从 和 提取的 和 的潜在向量。加载矩阵 和 分别为 和 的潜在向量的对应系数。加载矩阵 和 则分别为 和 的潜在向量的系数。 ,, 和 则是随机误差。 和 可以表示为等价的线性变换形式,如下所示:
(5)
(6)
其中 和 是权重矩阵。这表示 和 可以分别由嵌套在 和 中 和 个独立的方向向量来表示。一旦得到 和 ,我们就可以利用最小二乘回归方法根据公式(1)~(6)来计算 和 :
(7)
(8)
和Y是相同示例的变量空间和类标签空间,所以它们拥有相同的属性。我们采用PLS判别分析来获得潜在成分 ,此时变量空间 的投影比原始投影的误差更小。这里使用PLS是为了研究 隐藏在 的主要编码信息,即
(9)
其中 是协方差函数,而I是单位矩阵。
如果我们用暴力解法来解决优化问题(9),那么将会相当耗时。根据PLS判别分析的特点 [11],可知潜在向量 和 是正交的,并且其中的每一个方向向量 (即 的列向量)都与 有最大的协方差。因此,我们可以每次只考虑一个单一的向量 来近似求解优化问题(9)。基于公式(5)和(6),有 和 。在问题(9)中充分考虑协方差函数,则可以将它转换为:
(10)
我们通过在公式(10)上应用拉格朗日乘子来得到 和 ,然后可以计算得到潜在成分 和 。因此,目标函数可以改写为:
(11)
其中 和 分别是荷载矩阵 和 的列向量, 和 是非负数参数。
在现实中,观察值与有限的类标签相关联,因此标签空间应该是稀疏的。然而,公式(11)的 和 通常是密集且连续的,这使得结果的可解释性变差。为了解决这个问题,我们在 上加入 范数惩罚约束(因为潜变量 是正交的),这为变量 提供了变量选择并使它变得稀疏。同时,我们在目标函数里加入了视角约束项 来最大化不同视图的一致性。 和 分别是 视角A和视角B的预测值。因此,公式(11)可以写为:
(12)
为了简化公式,我们让 ,,,, 和 ,其中 和 是 的向量,这两个向量中的元素分别都是0和1。因此,公式(12)可以转换成:
(13)
设 为公式(13)的优化函数:
(14)
问题(14)是一个传统的LASSO问题 [20],为了降低模型的复杂性,我们使用软阈值操作来获得每个 的系数。因此,对公式(14)求 的偏导,可得:
(15)
其中 是a的符号函数,如果 则 为1;否则 为−1。设公式(15)为0,则有:
(16)
其中 是软阈值运算符,它的定义如下:
(17)
一旦求得 ,就可以得到 和 ,从而可以得到 和 。则 和 的回归模型为:
(18)
(19)
根据公式(18) (19),视角A和视角B对应的类标签预测值如下:
(20)
(21)
则测试集最终的预测值为:
(22)
预测值 是连续的,但多视图多标签数据的标签空间应该是稀疏的。因此,我们引入 函数将预测值转换为二进制值:如果预测值大于0,则将其重新赋值为1;否则,它将被重新赋值为0。
上述基于实例的多视角多标签学习算法模型,我们提出了该算法的完整过程,具体的算法实现步骤如表1所示。该算法的时间复杂度为 ,而 。其中, 和 是视角A和视角B中潜在变量的数量, 是非负参数。

Table 1. Algorithm implementation steps
表1. 算法实现步骤
3. 实验与分析
3.1. 实验数据
为了验证模型的有效性和鲁棒性,我们对多个多视角多标签数据集进行了对比实验,这些数据集包括mirickr,pascal07,corel5k,espgame,iapart12 [21],Health和Social [22]。在mirickr,pascal07,corel5k,espgame和iapart12数据集里,我们使用HSV作为A视角的特征,使用RGB作为视角B的特征。在Health和Social数据集里,我们将特征分为两个相等的部分,分别将它们视为视角A和视角B的特征。数据集的详情描述见表2。
Table 2. Experimental data combination
表2. 实验数据组合
3.2. 实验设置
为了验证算法的性能,我们选择了四个评价指标,分别是Hamming loss、Ranking loss、One error和Average precision。其中Hamming loss、Ranking loss和One error的值越低,则表示算法的性能越好;而Average precision的值越高,则算法的性能越好。为了证明算法的有效性,我们选取了四种算法作对比,如下所示:
• SWIM [12]:该方法是一种单视角多标签学习算法,它利用PLS来研究示例间的映射关系。
• lrMMC [19]:该方法是一种多视角多标签学习算法,它首先在所有数据视角中分别找到一个低秩的公共表示特征,然后将这些低秩的公共表示特征嵌入到基于矩阵补全的图像分类器中来预测变量对应的标签。
• SSDR-MML [23]:该方法是一种多视角多标签学习算法,它利用了基于重构误差的框架去构建分类器。
• GLMVML [24]:该方法是一种多视角多标签学习算法,它从不同视角中结合了全局标签相关性和局部标签相关性,然后提出了一种共识多视角表示方法来预测数据的类标签。
由于SWIM是一种单视角多标签学习算法,它不能处理多视角多标签数据。因此,我们首先利用SWIM算法为每个数据视角构建单视角多标签学习分类器(SWIM-A和SWIM-B),然后再将视角A和视角B合并成一个单独的视角,并基于该视角构建分类器(SWIM-all)。
在SWIM里,参数 和 设为0.1,m的取值范围为 。对于lrMMC,公共子空间的维数k的取值范围为 ,参数 的取值范围为 。对于SSDR-MML,我们将惩罚参数 设为100,让 ,参数 ,, 和 的取值范围为 。对于GLMVML,我们让 ,, 和 相等并设为 ,让 ,, 和 相等并设为 ,让 和 相等并设为 。对于我们的算法,参数 和 的取值范围为 ,让潜在变量的个数相等( )并将其取值范围设为 。本文中所有的实验都是在Conroe IV上进行的,CPU为2.8 GHz,主内存为12 GB。我们用MATLAB 2018b实现了算法的性能对比,在实验中,我们采用5倍交叉验证和实验的平均值,实验选取80%的数据作为训练集,20%的数据作为测试集。
3.3. 实验结果及分析
3.3.1. 算法的性能对比
在本节中,我们将比较提出的方法和四个对比方法的性能。表3~6分别汇总了四个评价指标下的比较算法的性能。
Table 3. Hamming loss statistic
表3. 汉明损失统计
Table 4. Ranking loss statistic
表4. 排序损失统计
Table 5. One error statistic
表5. 首标记错误统计
Table 6. Average precision statistic
表6. 平均精度统计
根据实验结果,我们提出的算法与其他对比算法相比,拥有最好的性能。例如,在表6得pascal07一列中,lrMMC、SSDR-MML和GLMVML的Average precision分别为0.381,0.629,0.584,而提出的算法的Average precision为0.657,分别比对比算法高出0.276,0.028和0.073。除pascal07数据集外,在其他实验数据集上也可以发现类似的观察结果。
从实验结果可以看出,SWIM-all的平均性能要优于SWIM-A和SWIM-B。在所有数据集中,SWIM-all的四项评价指标结果均高于单视角方法SWIM-A和SWIM-B。以Social数据集为例,SWIM-all的Hamming loss,Ranking loss和One error分别为0.023,0.071和0.328,要明显低于SWIM-A的0.024,0.079和0.342,以及SWIM-B的0.024,0.085和0.365。同时,SWIM-all的Average precision为0.746,分别比SWIM-A的0.733和SWIM-B的0.721的值高0.013和0.025。这些实验结果表明,不同视角可以直接提供编码在类标签中的互补信息,因此使用所有视角作为特征变量的分类器性能要优于使用单个视角为特征变量的分类器。
从表3~6可以看出,所提算法的性能要优于但是叫多标签算法的性能,包括SWIM-all,SWIM-A和SWIM-B。在所有的数据集中,我们所提算法的性能都要明显优于SWIM-all。以pascal07数据集为例,所提算法的Hamming loss,Ranking loss和One error分别为0.076,0.147和0.403,明显低于SWIM-A (0.097,0.197,0.491),SWIM-B (0.094,0.193,0.478)和SWIM-all (0.089、0.186和0.455)。而所提算法的Average precision为0.657,分别比SWIM-A (0.601),SWIM-B (0.605)和SWIM-all (0.617)高0.056,0.052和0.040。这说明来自不同数据视角的数据具有不同的数据分布特征。与直接将两个视角连接成为一个单一视角相比,分别训练不同的数据视角再结合这些视角构建分类器分类器,会更有利于学习不同视角的特征,并且分类器的性能也会更好。
3.3.2. 参数影响
下面,我们将研究所提算法在不同参数值下的性能变化。我们提出的算法中,有两种参数影响算法的性能,即正则化常量 和 ,以及潜在变量的个数 和 。为了说明参数的作用,我们用不同参数值的来训练模型,并对比不同参数对模型性能的影响。
我们对数据集运行算法,得到 和 不同值时Hamming loss的变化,如图2所示。实验中,我们将 和 固定为30,并令 。从图2可以看出,随着 值的增加,Hamming loss也在逐渐增大,但是增加值的变化很小。 值越大模型的稀疏性越好,但性能相对较差。总的来说,算法的分类性能随着 值的变化是相对稳定的。
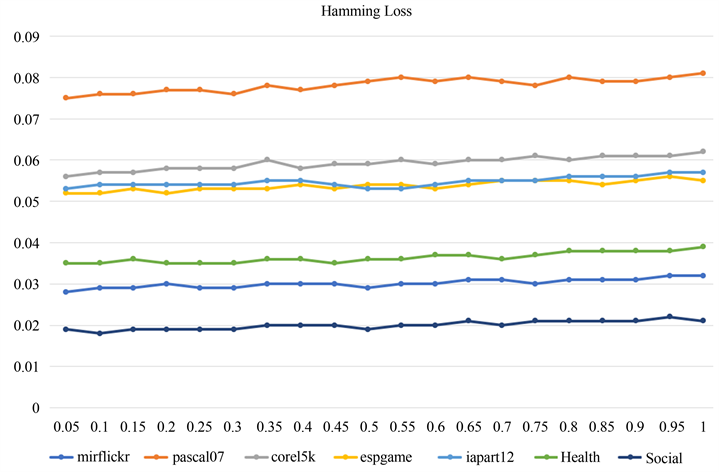
Figure 2. Hamming Loss with different values of
图2. 不同 值的Hamming Loss变化曲线
为了说明潜在变量数m的影响,我们用不同潜在变量数在数据集上进行了实验。我们令 ,令 。 和 不同值时Average precision的变化如图3所示。显然,随着潜在变量数量的增加,Average precision在开始时大幅上升,而当潜在变量数量 后Average precision的增加趋于缓慢,模型相对稳定。虽然 和 的值越大模型的平均精度越高,但模型的时间复杂度也在迅速增加。因此,潜在变量 和 的数量设置为30是相对合理的。
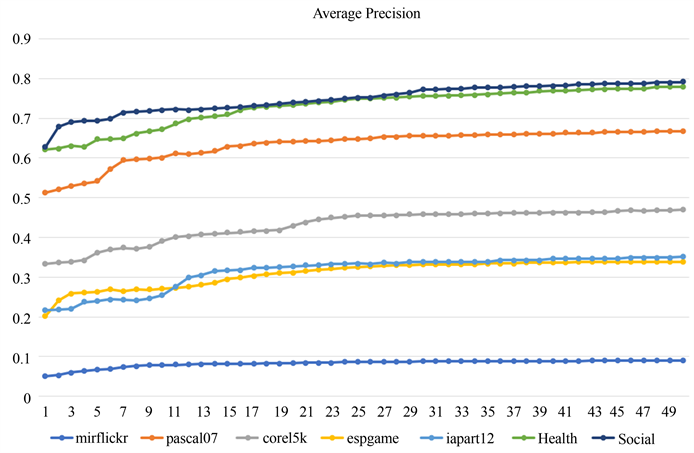
Figure 3. Average precision with different values of m
图3. 不同m值的Average precision变化曲线
4. 总结
在本文中,我们提出了一种基于实例的多视角多标签方法,该方法通过映射训练示例和测试示例之间的关系来构建模型。简单来说,我们利用带 范数惩罚的PLS判别分析为每个数据视角构建多标签分类器,以使模型稀疏化并提高其鲁棒性。然后,根据视角一致性原则将所有数据视角的分类器结合起来,将不同视角的一致性和互补信息加入到多标签分类器中,从而提高模型的性能。我们在公共数据集上的实验结果表明,我们提出的算法表现出优异的性能。
基金项目
本文得到国家自然科学基金资助项目(No. 62076074)的资助。
文章引用
苏可政,肖燕珊,刘 波. 基于实例的多视角多标签学习算法
Multi-View Multi-Label Learning by Exploiting Instance Correlations[J]. 计算机科学与应用, 2022, 12(04): 785-796. https://doi.org/10.12677/CSA.2022.124080
参考文献
- 1. 唐静静, 田英杰. 多视角学习综述[J]. 数学建模及其应用, 2017, 6(3): 1-15+25.
- 2. 吕卫, 李德盛, 谭浪, 等. 基于多视角低秩表征的短视频多标签学习模型[J]. 激光与光电子学进展, 2020, 57(22): 139-146.
- 3. 黄家君. 情感分析中的方面类别识别研究[D]: [硕士学位论文]. 南京: 南京大学, 2016.
- 4. 温雯, 陈颖, 蔡瑞初, 等. 基于多视角多标签学习的读者情绪分类[J]. 计算机科学, 2018, 45(8): 191-197.
- 5. Feng, L., An, B. and He, S. (2019) Collaboration Based Multi-Label Learning. Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, 27 January-1 February 2019, 3550-3557.
- 6. Fürnkranz, J., Hüllermeier, E., Loza Mencía, E., et al. (2008) Multilabel Classification via Calibrated Label Ranking. Machine Learning, 73, 133-153. https://doi.org/10.1007/s10994-008-5064-8
- 7. Guo, Y. and Xue, W. (2013) Probabilistic Multi-Label Classifica-tion with Sparse Feature Learning. Proceedings of the Twenty-Third International Joint Conference on Artificial Intelli-gence, Beijing, 3-9 August 2013, 1373-1379.
- 8. Su, H. and Rousu, J. (2013) Multilabel Classification through Ran-dom Graph Ensembles. Machine Learning, 99, 231-256. https://doi.org/10.1007/s10994-014-5465-9
- 9. Enrique Sucar, L., Bielza, C., Morales, E.F., et al. (2014) Multi-Label Classification with Bayesian Network-Based Chain Classi-fiers. Pattern Recognition Letters, 41, 14-22. https://doi.org/10.1016/j.patrec.2013.11.007
- 10. Zhu, S., Ji, X., Xu, W., et al. (2005) Multi-Labelled Classification Using Maximum Entropy Method. Proceedings of the 28th Annual Inter-national ACM SIGIR Conference on Research and Development in Information Retrieval, Salvador, 15-19 August 2005, 274-281. https://doi.org/10.1145/1076034.1076082
- 11. Liu, H., Ma, Z., Zhang, S., et al. (2015) Penalized Partial Least Square Discriminant Analysis with ℓ1-Norm for Multi-Label Data. Pattern Recognition, 48, 1724-1733. https://doi.org/10.1016/j.patcog.2014.11.007
- 12. Liu, H., Li, X. and Zhang, S. (2016) Learning Instance Correla-tion Functions for Multilabel Classification. IEEE Transactions on Cybernetics, 47, 499-510. https://doi.org/10.1109/TCYB.2016.2519683
- 13. Liu, H., Ma, Z., Han, J., et al. (2018) Regularized Partial Least Squares for Multi-Label Learning. International Journal of Machine Learning and Cybernetics, 9, 335-346. https://doi.org/10.1007/s13042-016-0500-8
- 14. Yin, Q., Wu, S. and Wang, L. (2017) Unified Subspace Learning for Incomplete and Unlabeled Multi-View Data. Pattern Recognition, 67, 313-327. https://doi.org/10.1016/j.patcog.2017.01.035
- 15. Tan, Q., Yu, G., Domeniconi, C., et al. (2018) Multi-View Weak-Label Learning Based on Matrix Completion. Proceedings of the 2018 SIAM International Conference on Data Mining, San Diego, 3-5 May 2018, 450-458. https://doi.org/10.1137/1.9781611975321.51
- 16. Tan, Q., Yu, G., Domeniconi, C., et al. (2018) Incomplete Mul-ti-View Weak-Label Learning. International Joint Conference on Artificial Intelligence, Stockholm, 13-19 July 2018, 2703-2709.
- 17. Zhang, J., Li, C., Sun, Z., et al. (2019) Towards a Unified Multi-Source-Based Optimization Frame-work for Multi-Label Learning. Applied Soft Computing, 76, 425-435. https://doi.org/10.1016/j.asoc.2018.12.016
- 18. Huang, J., Qu, X., Li, G., et al. (2019) Multi-View Multi-Label Learning with View-Label-Specific Features. IEEE Access, 7, 100979-100992. https://doi.org/10.1109/ACCESS.2019.2930468
- 19. Liu, M., Luo, Y., Tao, D., et al. (2015) Low-Rank Mul-ti-View Learning in Matrix Completion for Multi-Label Image Classification. Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, 25-30 January 2015, 2778-2784.
- 20. Friedman, J., Hastie, T. and Tibshirani, R. (2010) Regulari-zation Paths for Generalized Linear Models via Coordinate Descent. Journal of Statistical Software, 33, 1-22.
- 21. http://lear.inrialpes.fr/people/guillaumin/data.php
- 22. Learning from Multi-Label Data. MLKD. (2012) http://mlkd.csd.auth.gr/multilabel.html
- 23. Qian, B., Wang, X., Ye, J., et al. (2014) A Reconstruction Error Based Framework for Multi-Label and Multi-View Learning. IEEE Transactions on Knowledge and Data Engineering, 27, 594-607. https://doi.org/10.1109/TKDE.2014.2339860
- 24. Zhu, C., Miao, D., Wang, Z., et al. (2020) Global and Local Multi-View Multi-Label Learning. Neurocomputing, 371, 67-77. https://doi.org/10.1016/j.neucom.2019.09.009