Operations Research and Fuzziology
Vol.
13
No.
02
(
2023
), Article ID:
63991
,
11
pages
10.12677/ORF.2023.132075
XGBoost算法在二手房价格预测中的应用
王美1,朱珊艳2,陈鹏蕾1,武业文1*
1南京信息工程大学数学与统计学院,江苏 南京
2浙江科技学院理学院,浙江 杭州
收稿日期:2023年2月21日;录用日期:2023年4月7日;发布日期:2023年4月17日

摘要
随着近些年社会经济的快速发展,房地产的开发也如火如荼展开,二手房市场也得到迅猛发展,在如今存量房时代,二手房交易成为房地产市场的重要部分,二手房的价格是诸多购房者的关注点,因此对二手房价格预测是有必要的。本文围绕XGBoost算法学习,借助网络爬虫技术,从链家网站采集了杭州九堡1500条在售二手房信息,将数据清洗并提取特征后,在Shiny平台进行展示,并以2023年2月江干区二手房均价34,381元/平米为分界线,将该地二手房分为高、低价格共两类。本文就影响二手房房价的因素进行深入研究,进而对房价进行分类预测。通过对影响二手房价格的特征因素提取并排序,结果显示第一重要的特征是房屋面积,其次是二手房屋关注的人数及发布时间、建筑结构、房间数量、房屋装修情况这四个特征,而房本时间、客厅和餐厅数量是重要性最弱的特征。本文基于XGBoost算法对房价预测,结果分类效果较为理想,说明算法的应用性较好,同时为后续我国二手房价格预测或其他问题的预测扩充探索的道路。
关键词
XGBoost,网络爬虫,分类预测,二手房

The Application of XGBoost Algorithm in Second-Hand House Price Prediction
Mei Wang1, Shanyan Zhu2, Penglei Chen1, Yewen Wu1*
1School of Mathematics and Statistics, Nanjing University of Information Science and Technology, Nanjing Jiangsu
2College of Science, Zhejiang University of Science and Technology, Hangzhou Zhejiang
Received: Feb. 21st, 2023; accepted: Apr. 7th, 2023; published: Apr. 17th, 2023

ABSTRACT
With the rapid socio-economic development in recent years, real estate development has been in full swing and the secondary housing market has also developed rapidly. Nowadays, in the era of inventory, second-hand house transactions have become an important part of the real estate market, and the price of second-hand houses is a concern for many home buyers, so it is necessary to predict the price of second-hand houses. In this paper, around XGBoost algorithm, with the help of web crawler technology, 1500 second-hand houses for sale in Jiubao, Hangzhou are collected from the website of Chain Home, the data are cleaned and features are extracted and displayed in Shiny platform, and the average price of second-hand houses in Jianggan District in February 2023 is 34,381 Yuan every square meter as the dividing line, and the second-hand houses in the area are divided into two categories of high and low prices in total. This paper conducts an in-depth study on the factors affecting the price of second-hand houses, and then categorizes and predicts the price of houses. By extracting and ranking the feature factors affecting the price of second-hand houses, the results show that the first important feature is the house area, followed by the four features of the number of people concerned about second-hand houses and the release time, the building structure, the number of rooms, and the house decoration, while the time of the house book and the number of living and dining rooms are the features with the weakest importance. This paper is based on the XGBoost algorithm for house price prediction, and the results of the classification effect is more satisfactory, which indicates that the algorithm has better applicability, and also expands the path of exploration for the subsequent prediction of second-hand house price or other problems in China.
Keywords:XGBoost, Web Crawler, Classification Prediction, Second-Hand Houses

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
二手房市场以房源流动性强、交易活跃性高的特点始终保持着良好稳定的发展,在部分一线城市的市场占比已然超过新房市场。每一个房产销售者都会将李嘉诚说的话作为房产的卖点,即“决定房地产价值的因素,第一是地段,第二是地段,第三还是地段”。地段是影响房产当下价格的主要因素,也是影响房产未来一个时期价格变化的重要因素。如何综合考虑地段、房屋结构等因素,选择可量化的指标,对二手房价格进行合理有效的评估,是促进二手房交易市场稳定发展的关键。龚洪亮等人基于XGBoost方法对武汉市二手房价格进行预测,并与LASSO方法进行对比,结果表明XGBoost方法预测精度提升明显 [1] 。刘锋等人对重庆市2012年的统计年鉴房价数据,采用变系数模型预测,结论是拟合效果比现行回归模型更好 [2] 。魏云云等人通过采用灰度系数分析,选出了对西安房屋价格影响较大的一些因素,然后使用BP神经网络预测了价格,通过这种过程建立的预测模型加快了神经网络的训练速度,同时也得到了很好的预测结果 [3] 。
英国统计学家George E. P. Box曾说“All models are wrong,but some are useful”。没有模型能够完全正确,但它们确实能够刻画或表达出我们想要的能够解释现象的规律,尽管,有些时候这类规律并不如线性模型那般能够明确表示,而是像诸多机器学习算法一样,规律被隐藏于黑箱中。XGBoost (Extreme Gradient Boosting)是近几年在Kaggle竞赛中较为流行的机器学习算法,其本质仍是基于决策树的,以梯度提升为框架的算法。其应用范围广泛,可以帮助解决回归、分类、时间序列等预测问题。
本文是以XGBoost算法学习为出发点,将其应用在二手房价格预测中,学习其在分类预测中的算法流程。基于机器学习算法和网络爬虫技术,对二手房价格进行预测,本文的技术路线如图1所示。首先,借助R软件中的rvest包从链家网站爬取杭州九堡所有挂牌的二手房信息,共1500套房源信息。其次,对爬取的房源信息进行特征提取,借助Shiny搭建搜索平台,对房源信息进行展示;最后,以2023年2月江干区二手房均价34,381元/平米为分界线,将高于该价格的房源定位为高价格类,低于该价格的房源定位为低价格类,在划分为训练集和测试集后,进行XGBoost分类模型的训练和测试。

Figure 1. Technical roadmap
图1. 技术路线图
2. XGBoost理论介绍
2.1. XGBoost预测原理介绍
XGBoost (Extreme Gradient Boosting)的基本框架是boosting,其主要基础思想来源于决策树和集成学习,被广泛应用于分类和回归分析中。XGBoost算法思想是:对所有特征的值进行排序,并存储为块结构,然后遍历所有分割点找到一个特征上最优的分割点,将数据分裂成左右子节点,其目标就是找到一组树,以这组树作为样本预测值,利用算法使得样本预测误差即目标函数达到最小的同时,还具有一定的鲁棒性和泛化能力。其公式推导流程如下:
第一步,构建目标函数 ,由模型损失函数 + 正则化形式构成,其中通过添加正则项防止模型出现过拟合。
(1)
其中 为正则项, 为损失函数, 为样本量, 为样本的实际值, 为模型第 个样本的输出值, 为决策树个数, 为第 棵树用于到叶子点的映射。
第二步,对损失函数 进行泰勒展开,记为:
(2)
其中 ,用于定义一棵树, 为叶子节点总数, 为正则项,用来定义一棵树的复杂度。
(3)
第三步,对叶子节点进行分组的目标函数核函数为:
(4)
定义 , ,则其最优点为:
(5)
第四步,将数据集分成两组,数据集在分裂后各自的损失记为 和 ,计算分裂后的收益:
(6)
然后利用最优切分点划分算法遍历所有的决策树节点找到目标函数。
XGBoost最优切分点划分算法常见的有两种:一种是贪婪算法,一种是近似算法 [4] [5] 。贪婪算法是从深度为0的树开始,对每个节点的所有样本按照每个特征的特征值进行升序排列后,找到最佳分裂点并记录分裂收益Gain,选择Gain最大的特征为分裂特征,并以此作为分裂位置。并对该叶子节点上新分裂的两个叶节点关联其样本集。依次重复直至满足条件。由于贪婪算法当数据量太大时无法进入内存找到最优解。针对这一缺点,近似算法只考虑每个特征的分位点,利用分位数策略,大大减少计算的复杂度,从而找到最优解。
2.2. XGBoost模型参数
XGBoost算法的作者将模型参数分为三类,分别是通用参数、Booster参数和学习目标参数。
通用参数也叫一般参数,作用是对宏观函数进行控制。silent默认值是0,静默模式为1,0为连续输出消息。Booster默认值为gbtree,上升模型为树模型,gblinear是指上升模型为线性函数。num_pbuffer和num_feature均由XGBoost自动设置。
Booster参数用于控制每一步的booster。eta默认值为0.3,可取范围是0~1,用于更新补偿收缩,防止过度拟合。gamma默认值为0,指定最小损失减少应进一步划分树的叶节点。max_depth默认为6,是指一棵树的最大深度,参数范围1到 。min_child_weight默认为1,是指在子树中指定最小的海塞权重的和,参数范围0到 。max_delta_step默认为0,意味着没有约束。subsample默认为1,指定训练实例的子样品比,设置为0.5意味着XGBoost随机收集一半的数据实例来生成树来防止过度拟合,参数范围是0~1。colsample_bytree默认值为1,指定列的子样品比,范围是0~1。
任务参数是指控制训练目标的表现,决定学习场景。base_score默认值设置为0.5,制定初始预测分数作为全局偏差。objective默认值设置为reg:liner,指定想要的学习类型,有线性回归、逻辑回归、泊松回归等。eval_metric为指定验证数据的评估指标,例如回归中,默认rmse,分类中,默认error。seed为随机数种子,以便数据重现。
2.3. XGBoost模型效果评价
在回归预测中,评价回归模型好坏的常见指标是MAE、MSE和RMSE:
MAE (Mean Absolute Error)是平均绝对误差: ;
MSE (Mean Square Error)是均方误差: ;
RMSE (Root Mean Square Error)是均方均根误差: 。
在分类预测中,衡量学习器优劣的指标为AUC (Area Under Curve),通过绘制ROC曲线,计算曲线下方面积即为AUC的值。ROC平面的横坐标是false positive rate (FPR),纵坐标是true positive rate (TPR)。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个TPR和FPR点对。将分类器映射成ROC平面上的一个点。调整分类器分类时使用的阈值,可以得到一个经过(0, 0),(1, 1)的曲线,这就是此分类器的ROC曲线。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。AUC的取值范围是0~1,越接近1说明分类效果越好,当小于0.5时,分类器意味着随机分类,没有意义。
3. 二手房价格分类预测
3.1. 网络爬虫
3.1.1. 基本原理及流程
本文进行数据采集的R语言包是rvest,基本原理是通过编写自动化程序,在html树上找到相应的字符、数值等内容,存放回本地。
网络爬虫的流程如下:
1) 设置起始URL地址,放入待采集队列;
2) 自动化程序从待采集的队列中选一个URL地址,发送请求获取网页信息;
3) 信息采集后,将已采集的URL地址从队列中剔除;
4) 获取新的URL地址加入队列,直至遍历完所有待采集网页。
3.1.2. 功能实现
本文采集的是链家网站上杭州九堡二手房在售数据,2023年2月20日关于该地区的在售二手房共1500套,共50页,每页30条信息。在此,批量采集二手房信息。
1) 初始URL
杭州九堡二手房页面的初始网址为http://hz.lianjia.com/ershoufang/jiubao/,这是首页,第二页的网络地址是http://hz.lianjia.com/ershoufang/jiubao/pg2/,然后能够发现,当把/pg1/作为后缀加入首页地址后,其仍表示首页,因此,可以在pg后方设置页面循环参数i,i的取值范围为1~50。
2) 批量爬取
本文较为关注的网页上二手房信息主要是六个html_nodes,以下以房屋单价数据的批量爬取为例进行说明:
unitprice<-c()
for (i in 1:50){
pathfile<-sub(pattern = d, replacement = i, x = http://XXXXX/pgd/)
print(pathfile)
position_name.temp <-read_html(pathfile) %>%
html_nodes(div.positionInfo) %>%
html_text()
position_name<-c(position_name, position_name.temp)
print(paste(... ... Page, i, Done!))
}
首先,定义一个空的向量,用于存放爬取的批量数据;其次,编写循环函数,用于重复在多页上进行数据采集的行为,并设置网页上unitprice所在位置的html_nodes;再次,将该nodes处的数据采集放入事先定义的空向量处;最后,完成以上步骤后,每爬取一页数据,输出一行提示:Page i Done!
3.2. 特征提取及数据展示
3.2.1. 特征提取
1) 本文采集了链家网页上与二手房相关的六个html_nodes的信息,分别命名为position_name、totalprice、unitprice、houseinfo、tag以及attention。采集的少量结果如下表1所示:

Table 1. Display of second-hand house information collection results
表1. 二手房信息采集结果展示
position_name是指二手房屋所在的小区名称,如图2所示,每个小区名称之后都会附有小区所在的区域,本次数据采集的区域范围定在杭州九堡,因此该后缀统一,可用gsub()函数以空格代替后缀进行处理,也能用strsplit()函数以“-”对字符串进行划分,并保留前一组字符。前一种方法更简便,两种方法的具体代码如下:
• position_name<-gsub(-九堡, position_name)
• position_name1<-strsplit(position_name, split = -, fixed = T)
position_name2<-unlist(position_name1)
position_name3<-matrix(position_name2, ncol = 2, byrow = TRUE)
position_name4<-position_name3[,1]
position_name5<-gsub( , , position_name4)
totalprice是指二手房屋的总价,以万为单位,如图所示,该数据不需要进行清洗处理。
unitprice是指二手房屋的单价,以元/平米为单位,如图所示,对该数据的清洗需要剔除“单价”和“元/平米”,同样也是使用gsub()函数。
houseinfo是指二手房屋结构信息,包括几室几厅、总面积、朝向、装修、楼层、建筑结构,共五个信息。信息之间以“|”进行分隔,使用strsplit()函数对字符进行分割,并整理成每行六列的矩阵形式。
tag是指二手房屋的标签,涉及到不动产权的时间,放初产权证明满两年和满五年所交的税额不同。部分二手房没有贴上产权证证明的时间,则被归为未满两年,在对分类数据进行赋值时需要用到。
attention是指该套二手房屋关注的人数及发布时间。这两类信息间以“/”分割,处理方式与上述houseinfo一致,以strsplit()函数进行分割。
首次数据清洗后的结果如下表2所示:
Table 2. Data display after the first cleaning
表2. 首次清洗后数据展示
2) 数据清洗好后,需要将部分分类数据进行编码,便于后续预测分析。本文主要对装修、建筑结构以及房本时间三个特征进行赋值,具体如下表3所示:
Table 3. Description of classification feature assignment
表3. 分类特征赋值说明
特征赋值后的部分数据展示如下表4:
Table 4. Data display for prediction and analysis after feature assignment
表4. 特征赋值后用于预测分析的数据展示
3.2.2. Shiny数据展示
Shiny是R语言的一个基于Web框架的可视化应用,可以对接数据源,生成图表和配置仪表盘。Shiny的结构包括两部分,一部分是ui端,用于构建整个应用的布局,可以添加控件,设置布局方式的排列等等。另一部分是server端,用于构建控件与图形的关系,在服务器端展示数据。执行结果以网页形式打开,其框架代码如下所示:
ui <- fluidPage(
titlePanel(XXXXX) )
server <- function(input, output) {
print(str(diamonds))}
shinyApp(ui = ui, server = server)
本文借助Shiny平台,将采集到的1500条二手房屋数据以列表形式进行展示,同时具备关键词搜索功能。如下图2所示:
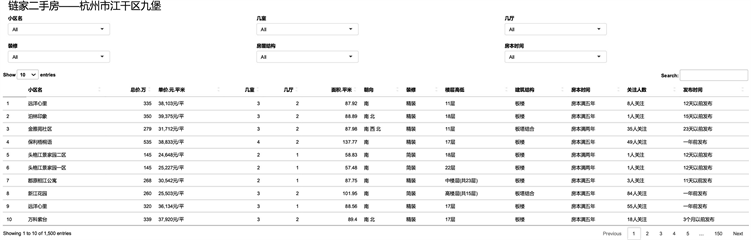
Figure 2. Shiny platform data display
图2. Shiny平台数据展示
可视化交互展示页面的标题是:链家二手房——杭州市江干区九堡。整体上分为上下两部分,上部分为六个控件,用于筛选,下部分为table输出,用于展示数据。另外,该页面还有Search控件,输入关键词能对信息进行选择性输出。
以下举个例子,设置条件:小区名保利梧桐语,4室2厅,精装,板楼。如下图3所示,输出该小区符合条件的在售二手房为3套。

Figure 3. Display of condition filter results
图3. 条件筛选结果展示
当在Search中输入“丽江公寓”进行搜索时,如下图4所示,共输出61条包含“丽江公寓”的二手房信息。

Figure 4. Display of conditional search results
图4. 条件搜索结果展示
3.3. XGBoost模型分类预测
3.3.1. 数据预处理
本文用于分类预测的变量特征为七个,分别是room_num、living_num、room_square、decoration、construction_type、taxfree以及attention。而其中分类的类指的是房屋单价的高低类别,2月杭州江干区的房屋均价为34,381元/平米,将高于均价的房屋归为高价格类,记为1,低于该均价的房屋归为低价格类记为0。
运行下方代码,对数据集进行缺失值查找,输出结果显示,从链家采集的数据不含有缺失值。
missing_data = data.frame(lapply(infodata,function(x) sum(is.na(x))))
随机选取75%的样本作为训练集,剩下25%的样本作为测试集,因此,训练集中含有1125个样本信息,测试集中含有375个样本信息。
3.3.2. 分类预测
划分好训练集和测试集之后,进行建模。这里设置xgboost()函数的部分参数如下:max_depth = 6,eta = 5,nround = 25,objective = “binary:logistic”,其余参数均为默认值。
测试集的分类结果如下表5所示:
Table 5. Classification results
表5. 分类结果
从测试集的分类结果大致可以发现,实际上,此次分类较为理想。而判断分类结果好坏的指标是AUC的值以及ROC曲线。因此得到AUC取值为0.734,效果理想。ROC曲线如下图5所示:

Figure 5. ROC curve
图5. ROC曲线
上图5中已显示AUC的取值为0.734,高于0.7,说明分类预测的有效果。
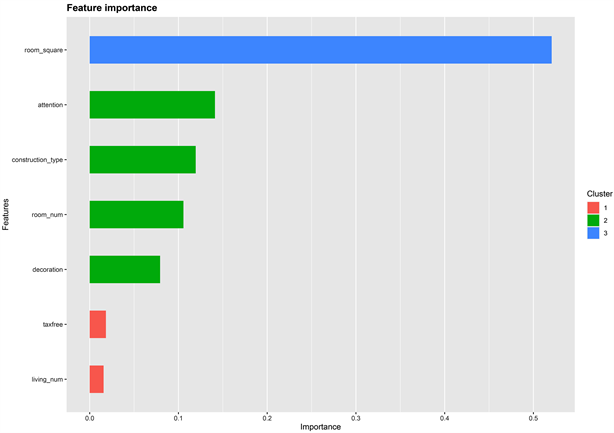
Figure 6. Characteristics importance ranking
图6. 特征重要性排序
根据特征的重要性程度打分其中房屋面积(room_square),可以分辨出对于模型来说哪些特征比较重要,可以基于这些特征完善特征选择的工作。图6所示的结果中可知:在此次预测中,房屋面积(room_square)是最靠前的特征,并且其重要性远远高于其他特征。与其对应的,重要性较低的特征为客厅和餐厅数量(living_room)和房本时间(taxfree),即涉及到房产交易税费的特征。
4. 结论与不足
本文主要运用了机器学习中的网络爬虫技术和XGBoost算法,对从链家网站采集到的二手房数据进行清洗、建模并预测分类。在不进行参数调整等情况下,模型的分类效果较为理想。在本文选取的众多特征指标中,房屋面积是影响本文分类的重要因素。
结合本次实验的过程和结果,对本文的局限性提出以下几点思考:
第一,缺乏与其他分类预测技术的对比。理论上,XGBoost算法能在Kaggle竞赛中风靡,主要是由于其预测精度高。而在本次实验中,缺乏这类对比,无法突出XGBoost算法的优越性。
第二,网络爬虫爬取的特征太少,最终参与分类模型的特征不足十个,并且众多影响房屋价格的因素并未列入,例如地理区位因素。后续实验在改进中,可考虑加入房屋的经纬度,将空间要素考虑在内,会更有参考价值。
第三,本次实验最终没有对模型参数进行调整,没有进一步调整得到关于该数据集的最优的分类结果。主要是时间有限,后续需要进一步完善。
文章引用
王 美,朱珊艳,陈鹏蕾,武业文. XGBoost算法在二手房价格预测中的应用
The Application of XGBoost Algorithm in Second-Hand House Price Prediction[J]. 运筹与模糊学, 2023, 13(02): 734-744. https://doi.org/10.12677/ORF.2023.132075
参考文献
- 1. 龚洪亮. 基于XGBoost算法的武汉市二手房价格预测模型的实证研究[D]: [硕士学位论文]. 武汉: 华中师范大学, 2018.
- 2. 刘锋, 张星, 张光锋. 重庆市房价变系数回归模型的建模与分析[J]. 重庆理工大学学报(自然科学), 2014, 28(4): 150-154.
- 3. 魏云云, 张引娣, 陈晨. 基于灰色关联分析的BP神经网络对西安房价的预测分析[J]. 榆林学院学报, 2015, 25(4): 47-51. https://doi.org/10.16752/j.cnki.jylu.2015.04.036
- 4. 山新们. XGBoost——从算法原理到近似计算[EB/OL]. https://zhuanlan.zhihu.com/p/94848125, 2020-09-20.
- 5. 汤家正. 基于数据挖掘和XGBoost算法的量化多因子对冲模型研究[D]: [硕士学位论文]. 济南: 山东大学, 2020.
NOTES
*通讯作者。