Modeling and Simulation
Vol.
12
No.
02
(
2023
), Article ID:
62396
,
11
pages
10.12677/MOS.2023.122092
基于遗传算法的方形件订单组批与排样优化
朱锐,李蒙,秦恩广
上海理工大学机械工程学院,上海
收稿日期:2023年2月3日;录用日期:2023年3月7日;发布日期:2023年3月14日

摘要
由于订单组批和排样优化在个性化定制生产模式中至关重要,基于此,本文以减少原片板材用量为目标,构建了混合整数规划模型。通过编写算法来求解此模型,初始算法采用K-means聚类算法与遗传算法进行混合使用,通过K-means聚类算法将相似的item分类,然后以类别进行随机,建立遗传算法的初始种群,从而提高初始种群的适应度,在算法过程中按照指定规则按照染色体基因顺序放置,计算原片板材用量用以评估染色体适应度。结果如下:平均板材利用率为63%,平均板材使用数量为133块。之后提出贪婪策略优化算法,优化后的结果如下:平均板材利用率为85%,平均板材使用数量为97块。
关键词
订单组批,排样优化,K-Means算法,遗传算法

Optimization of Order Batching and Layout of Square Parts Based on Genetic Algorithm
Rui Zhu, Meng Li, Enguang Qin
School of Mechanical Engineering, University of Shanghai for Science and Technology, Shanghai
Received: Feb. 3rd, 2023; accepted: Mar. 7th, 2023; published: Mar. 14th, 2023

ABSTRACT
Since order grouping and scheduling optimization is crucial in the personalized production model, based on this, this paper constructs a mixed integer programming model with the goal of reducing the amount of original sheet metal used. The initial algorithm uses a mixture of K-means clustering algorithm and genetic algorithm to classify similar items by K-means clustering algorithm and then randomize them by category to establish the initial population of the genetic algorithm, thus improving the fitness of the initial population, and in the process of the algorithm, the chromosome genes are placed in order according to specified rules to calculate the original sheet. The plate usage was used to evaluate the chromosome fitness. The results are as follows: the average plate utilization is 63% and the average number of plates used is 133. After that, the greedy strategy optimization algorithm was proposed, and the optimized results were as follows: the average plate utilization was 85% and the average number of plates used was 97.
Keywords:Order Group Batch, Scheduling Optimization, K-Means Algorithm, Genetic Algorithm

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
提高材料利用率,降低原材料消耗,是企业减少资源和能源浪费,承担环境责任所要解决的关键问题。在实际工程应用领域中,订单组批与排样优化方法广泛的应用于型材、棒材、管材、金属结构材料和建筑材料等的生产过程中。订单组批与排样优化方法对于降低企业生产成本、提高企业经济效益、保护环境具有重要的现实意义。
目前,已有大量文献给出了订单组批与排样优化的求解方法,文献 [1] 考虑板材下料中纤维方向和一刀切等工艺约束,结合实际作业中切割机器的刀缝限制,建立了板材原料利用率最大的矩形件优化排样模型,同时设计了不同切割方式下的规则算法并进行求解,得到不同切割方式下的板材利用率以及矩形件排样图。文献 [2] 根据不同排样问题的复杂程度,建立整数线性规划模型、木板排样优化模型,运用遗传算法,并利用Matlab、C++进行编程求解,得出不同生产条件下板材的最优分割方案和最大利用率。文献 [3] 提取不规则件的几何特征,对零件进行组合操作预处理,使两个或多个不规则零件组合为矩形件或近似矩形件并对其包络矩形,然后利用蚁群学习算法对预处理后的零件进行排样,确定零件排放的最佳位置,不断更新得到最优排样结果。文献 [4] 研究提出了一种基于自组织特征映射模型的皮革材料优化排样智能算法,详细阐述了该算法下的优化排样思路与模型求解算法,并将该模型与算法应用于实际操作中。
已有的订单组批与排样优化方法从不同应用角度建立数学模型,并给出相应的优化算法,但是很少有文献在进行订单组批与排样优化时考虑齐头切,所以本文基于2022年华为杯中国研究生数学建模竞赛B题提供的数据集,针对方形件订单组批与排样的问题,仅考虑齐头切,建立混合整数规划模型,在满足生产订单需求和相关约束条件下,尽可能减少板材用量。
2. 模型假设与符号说明
2.1. 模型假设
1) 排版方式为精确排样;
2) 板材原片仅有一种规格且数量充足;
3) 切割阶段数不超过3,同一个阶段切割方向相同;
4) 直线切割、切割方向垂直于板材一条边,并保证每次直线切割板材可分离成两块(齐头切);
5) 排样方案不用考虑切割的缝隙宽度的影响;
6) 所有订单交货期均相同。
2.2. 符号说明
本文中的符号说明如表1所示。

Table 1. Index of subproblem 1 and its significance
表1. 子问题一的索引及其意义
3. 模型的建立与求解
3.1. 模型的建立
对于本文问题,可以将待切原片的板材尺寸设定为LxW,由于板材原片的数量充分,设定待排样的毛坯有m种,为了简化过程,对于其中相同尺寸但型号不同的部件均视为同一型号。对于某一个型号而言,长、宽以及需求量分别设定为 ,其中i为毛坯型号, , 。
假设确定排样方案 包含了K种排样方式, 表示第j种排样方式,而 为第j种排样方式的使用频率,而每种排样方式中所包含的i型毛坯数量为 , , 符号N表示自然数。子问题一的目标为使用数3量最少的板材原片,确定出一个合理的三阶段排样方案,该问题可以通过如下数学模型表示:
(1)
(2)
3.2. 算法设计
板材排样问题是一个十分经典的非确定性多项式时间可解的判定问题,遗传算法在求解该类问题中具有很强的适用性,遗传算法(GA)与其他智能优化算法相比,它的搜索能力强、鲁棒性好,选用遗传算法做排样方式优化理论上可以得到全局最优解。根据上述优点我们选用了遗传算法作为求解混合整数规划模型的方式,但由于单纯使用遗传算法不仅算法的时间复杂度极高,求解结果也并不理想,所以使用无监督聚类算法K-means算法对初始种群进行聚类,使得初始种群就具有较高的适应度,从而降低算法的时间复杂度,提高算法优化效果。
3.2.1. 使用K-Means算法聚类
K-means算法的基本思想是,先将数据分为K组,再随机选取K个中心,计算每个样本到各个中心之间的距离,把每个样本分配到距离它最近的中心,被分配的样本加上每个中心就代表了一个聚类,每分配一个新样本,就会根据现有的样本重新计算聚类中心,重复这个过程直到满足某个终止条件 [5] 。本文使用K-means算法对部件的长和宽频数进行统计排序,从高到低取前六个频数作为聚类中心,根据种群规模对这六类先进行不放回的抽样得到多条染色体,将染色体组合从而得到了适应度较高的初始种群,从而降低算法的时间复杂度。
3.2.2. 遗传算法的基本步骤
步骤1:设置迭代次数计数器t = 0,同时设置最大进化代数T,随机生成M个体作为初始群体P(0)。
步骤2:初步计算群体P(t)中各个的适应度。
步骤3:将选择算子作用于群体。选择的目的是把优化的个体直接遗传到下一代,或通过配对交叉产生新的个体再遗传到下一代。选择操作是建立在群体中个体的适应度评价基础上的。
步骤4:将交叉算子作用于群体。
步骤5:将变异算子作用于群体,即对群体中的个体串的某些基因座上的基因值进行变动。
步骤6:如果t = T,则以进化过程中所得到的具有最大适应度个体作为最优解输出,终止计算。
其中遗传算法的流程图如图1所示。

Figure 1. Genetic algorithm flow chart
图1. 遗传算法流程图
3.2.3. k均值算法结合遗传算法的具体流程
针对排样优化问题,原片的尺寸为2440 (mm) × 1220 (mm),为了降低算法复杂度,增加初始种群的适应度,可以使用K-means聚类方法,对初始部件进行聚类,对部件的长和宽频数进行统计排序,从高到低取前六个频数作为聚类中心,根据种群规模对这六类先进行不放回的抽样得到多条染色体,将染色体组合从而得到了适应度较高的初始种群。结合遗传算法,初始化种群数量通过K均值方法确定,种群数量值为400,最大迭代次数为400,交叉概率与变异概率分别为0.9和0.2。对于编码过程,采用整数编码的方式来实现染色体,对于所有部件均设置id编号,得到的一个染色体为所有部件数据id的一个排列。不同的排列对应这不同的样板划分,一块原片通过某种染色体顺序进行放置时,如果此块原片放不下其他的部件时,则会自动跳转到下一块原片上进行放置,所以最终得到某个染色体的排序方式则为该问题的最优解。
为了满足齐头切的操作方式,以及切割阶段数不超过3且相同阶段的切割方向相同的要求,原片中部件的放置操作可以设置为,一开始将部件放置原片的左下角,之后的部件如果长度和上一版部件的长度一致,则将其放置在之前部件的上面以形成一个stack,否则之前的部件单独作为一个stack,新部件则需放置在之前部件的右边,同时更新全局高度进行判断。通过这样不断地操作,可以得到多个stack的情况。为了简化操作,当放置部件形成了若干个stack之后,而右边空间不足以放置新的部件时,之前放置形成的stack就会自动形成一个stripe,也会生成新的stripe,之后的部件则可以放置在新stripe上。此时如果原片的剩余宽度不足以满足新stripe的宽度,则可以说明当前原片上的部件已经放置完毕,考虑采用新的原片继续放置。最后以使用的原片数量作为该个体的适应度,数量值越少则说明适应度越高,这样的个体更容易保留 [6] 。
种群的选择策略,可以直接对个体进行排序,保留排名靠前的种群,交叉和变异的操作则通过相应的概率改变染色体的部分排列顺序,通过不断迭代,完成后保留的种群则为适应度较高的种群,可以作为该问题一个较好的可行解。而在遗传算法中计算适应值的策略流程如图2如示。

Figure 2. Flowchart of item placement strategy
图2. item放置策略流程图
3.3. k均值算法结合遗传算法的算例求解
通过MATLAB语言实现对四个数据集的部件进行同一尺寸板材原片排样问题的求解,对于不同数据集的求解结果如表2所示,不同数据集的部分原片放置图见图3~6。
Table 2. Solution results of different data sets under hybrid algorithm
表2. 混合算法下不同数据集的求解结果
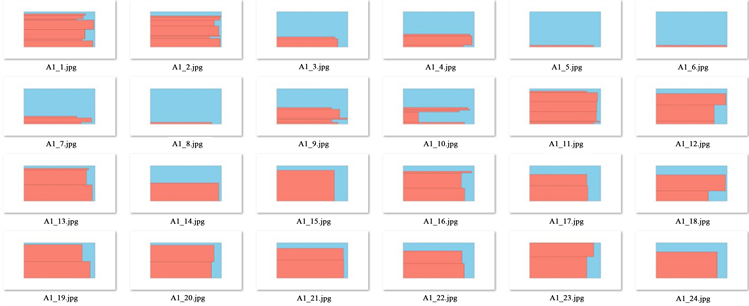
Figure 3. Part of the data A1 original film layout
图3. Data A1原片的部分排样
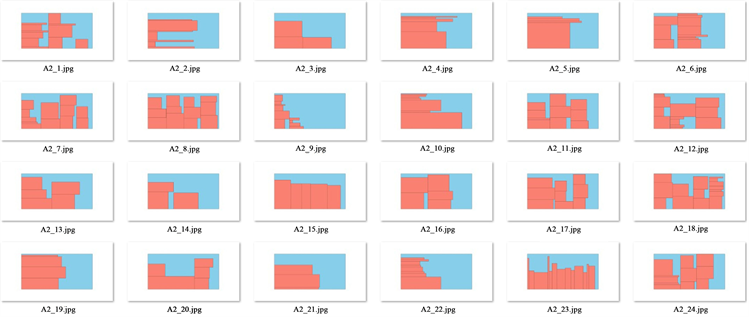
Figure 4. Part of the data A2 original film layout
图4. Data A2原片的部分排样
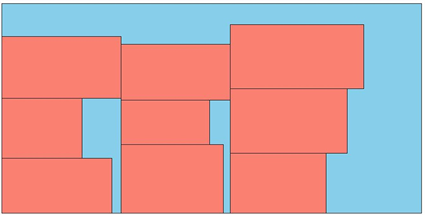
Figure 5. Data A3 of the 121st original film row sample
图5. Data A3的第121张原片排样

Figure 6. Data A3 of the 114th original film row sample
图6. Data A3的第114张原片排样
根据求解结果,我们可以发现四个数据集的材料利用率均在60%至64%之间,材料的利用率还有待提高,根据部分样片图我们可以发现有些样片的材料利用率很高,有些样片的还有很多的空间可以放置材料,不是非常合理,后续再进行改进。
4. 算法的改进求解与评价
4.1. 算法改进
通过K-means聚类算法与遗传算法的混合算法,确实可以得到解,但要得到全局最优解,不仅要消耗极高的算力,还可能陷入局部最优解,通过分析之前的结果,发现如果以item作为基因,以其排列组合作为染色体,使用遗传算法进行暴力求解,以目前计算机算力,几乎不可能得到全局最优解。所以转变思路,对之前的算法进行优化改进,选择以确定规则排布item和stack,然后以排布好的stripe作为最小单元,使用遗传算法进行求解。
由于stack和stripe的组合规则相对比较明确,所以可以采用贪婪策略,通过对所有item遍历,寻求到stripe局部最优解。先找到剩余item中面积最大的item,让它单独成stack,放置在stripe的最左边,固定面积最大的宽度为整个stripe的宽度。同时再考虑原片中的剩余宽度,继续寻找能够放入的较大面积的item,否则将stripe进行输出。这时放入的item需要考虑是否能在该item上放置其他是否等长的部件,符合条件则形成一个stack,否则单独成stack,直至原片上放置不了新的部件。这一步之后,我们得到了一系列的stack,并对其分别编号。之后进行K-means聚类算法将stack进行无监督聚类,然后将聚类后得到的stack组成形成stripe,再将stripe组成可行的排样方式,与之前的算法多了一步额外操作,先剔除无法与其他任何stripe组合的stripe,他们各自占据一个原始板材。然后再对剩余的部分进行组合。剩下的stripe通过遗传算法的操作,对stripe进行一个全排列,初始化种群后再计算个体适应度,通过不断的选择交叉变异得到最终的种群信息。由于stripe数据量相比部件数量较少,因此更容易得到该问题的最优解。设置遗传算法的主要参数,其中种群数量为200,迭代次数为300,交叉概率为0.8,而变异概率为0.1。染色体的长度即为处理后stripe的个数,其中获取stripe的具体流程如图7所示。

Figure 7. Flow chart for exporting stripe
图7. 输出stripe的流程图
4.2. 算法求解
通过改进后的算法,对于四个数据集的部件进行同一尺寸板材原片排样问题的求解,算法内容通过MATLAB语言实现。对于不同数据集的求解结果如表3所示。
Table 3. Solution results for different data sets with improved algorithms
表3. 改进算法下不同数据集的求解结果
通过部件在原片上的排列堆叠,发现有的原片利用率很高,如图8所示,而有的原片上根据规则只是放置了尺寸较大的部件,如图9所示。

Figure 8. The first original film row sample of the improved data A1
图8. 改进后data A1的第1张原片排样
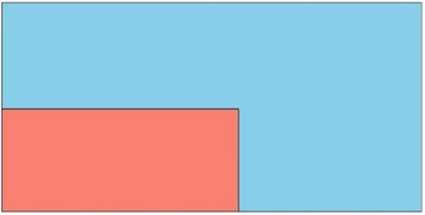
Figure 9. The 117th original film layout of the improved data A1
图9. 改进后data A1的第117张原片排样

Figure 10. Improved data A3 original film part of the row of samples
图10. 改进后data A3原片的部分排样
Figure 11. Improved data A4 original film part of the row of samples
图11. 改进后data A4原片的部分排样
4.3. 算法比较评价
改进后的算法摒弃了使用K-means聚类算法优化初始排样方式,而是使用了限定的规则和贪婪策略先将遗传算法的基因从item变为了stripe。由于stripe的数量远小于item的数量,所以改进算法与原本的算法相比,大大降低了算法复杂度,节省了计算机的算力,也可以在较短时间内得到比较满意的解。
相比于未改进的算法,改进算法的结果有了显著性的提升,如图12,最少板材原片数量从原来的大约130块减少到了100块左右,平均减少了将近26.46%;根据图13,板材利用率则从原来的大约60%提高到了80%以上,平均提升了36.09%,改进效果十分明显。
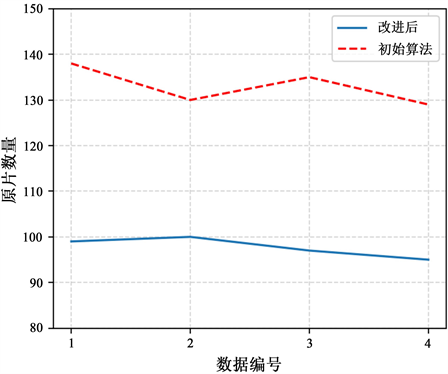
Figure 12. Comparison of the number of original films in each data table before and after improvement
图12. 改进前后各数据表的原片数量对比
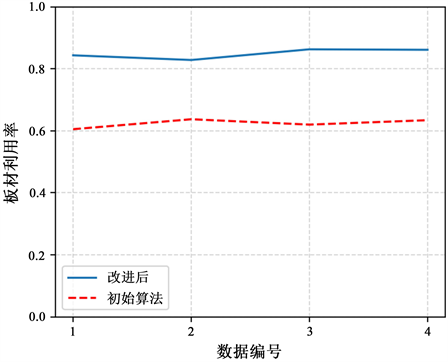
Figure 13. Comparison of plate utilization by data sheet before and after improvement
图13. 改进前后各数据表的板材利用率对比
5. 结论
订单组批与排样优化对企业的个性化定制生产模式至关重要,订单组批能将不同订单组成若干批次,实现订单的批量化生产,排样优化能够合理规划方形件在板材上的布局,以减少下料过程中存在板材浪费。本文针对方形件订单组批与排样优化的问题,以减少原片板材用量为目标,构建了混合整数规划模型,使用K-means聚类方法,对初始部件进行聚类,结合遗传算法对算例进行求解,得出四个数据集的材料利用率在60%至64%之间,最后使用贪婪策略改进算法并且进行求解,得出四个数据集的材料利用率均提高到82%以上,板材得利用率得到了明显提升。本文提出的混合算法能够很好的应用在企业个性化定制生产模式中,对提高板材的利用率有着重要意义。
文章引用
朱 锐,李 蒙,秦恩广. 基于遗传算法的方形件订单组批与排样优化
Optimization of Order Batching and Layout of Square Parts Based on Genetic Algorithm[J]. 建模与仿真, 2023, 12(02): 974-984. https://doi.org/10.12677/MOS.2023.122092
参考文献
- 1. 郭文文, 计明军, 邓文浩. 矩形件优化排样算法研究[J]. 现代制造工程, 2020(6): 86-93.
- 2. 吴雨婷, 张玉. 基于整数规划下木板排样优化问题的研究[J]. 科技风, 2020(17): 111.
- 3. 高勃, 张红艳, 朱明皓. 面向智能制造的不规则零件排样优化算法[J]. 计算机集成制造系统, 2021, 27(6): 1673-1680.
- 4. 于涛. 皮革材料优化排样智能算法设计与算例分析[J]. 中国皮革, 2022, 51(3): 45-47+51.
- 5. 刘倩. “一刀切”约束下的矩形件优化排样算法比较与整合研究[D]: [硕士学位论文]. 天津: 河北工业大学, 2012.
- 6. 陈秋莲. 二维剪切下料问题的三阶段排样方案优化算法研究[D]: [博士学位论文]. 广州: 华南理工大学, 2016.