Computer Science and Application
Vol.
11
No.
04
(
2021
), Article ID:
41985
,
9
pages
10.12677/CSA.2021.114117
基于潜在特征空间的低秩表示算法
周翊航
广东工业大学计算机学院,广东 广州

收稿日期:2021年3月28日;录用日期:2021年4月21日;发布日期:2021年4月28日

摘要
现有的大多低秩表示算法都是直接使用原始数据矩阵作为特征字典,然而原始数据中的冗余特征和噪声信息很可能会导致算法效果不佳。针对这种情况,本文提出一种基于潜在特征空间的低秩表示算法,通过正交字典来学习原始数据的潜在表示,然后利用潜在表示作为字典进行低秩表示学习,从而避免原始数据中的不利影响。
关键词
潜在特征,正交字典,低秩表示
Low-Rank Representation Algorithm Based on Latent Feature Space
Yihang Zhou
School of Computers, Guangdong University of Technology, Guangzhou Guangdong

Received: Mar. 28th, 2021; accepted: Apr. 21st, 2021; published: Apr. 28th, 2021

ABSTRACT
Most of the existing low-rank representation algorithms directly use the original data matrix as the feature dictionary, but the redundant features and noise information in the original data may cause the algorithm to perform poorly. In response to this situation, a low-rank representation algorithm based on the latent feature space is proposed. The latent representation of the original data is learned through an orthogonal dictionary, and then the latent representation is used as a dictionary for low-rank representation learning, so as to avoid the adverse effects of the original data.
Keywords:Latent Features, Orthogonal Dictionary, Low-Rank Representation

Copyright © 2021 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
随着社会经济的发展和科学技术的进步,人们获取信息的手段和渠道被大为拓宽。但是当我们在使用的特定数据时,往往会由于缺乏先验知识或者成本过高而难以进行人工标注。在这种数据没有标签的情况下,很自然地,我们会借助计算机来辅助完成一些任务。在机器学习中,这种根据类别未知的训练数据集来解决模式识别中的各种问题,称之为无监督学习。
“大数据”的迅猛发展推动了高维数据的处理需求,同时其也成为了无监督学习领域的研究热点之一。高维数据含有丰富的信息,对样本的描述更加充分,理论上这类高维数据应有助于机器学习到更好的模型。然而,高维的数据同样带来了算法复杂性的提升,不仅需要大量的空间来存储这些数据,而且还需要花费大量的时间来进行模型的训练,严重制约了算法的应用,特别是对于如视频跟踪等实时性要求比较严格的应用场景。此外,高维的数据尽管信息量丰富,但是却含有大量的冗余特征,甚至部分数据由于不规范的采集方式或恶劣的采集环境会出现大量的噪声或低分辨率等现象,给数据分析和模型学习带来了极大的挑战。如果直接对这样的大数据进行分析,不仅效率低下,而且由于冗余特征和噪声数据的存在难以学习到一个鲁棒的机器模型。为解决这一问题,人们在数据分析前对数据进行降维,提取出少量最有价值的紧凑信息进行分析,不仅节约了存储空间和处理时间,而且可以学习到鲁棒的模型。子空间学习作为一种经典的降维方法,由于其简单高效的特点而被广泛地研究使用。其主要含义是指通过寻找合适的投影,实现高维特征向低维子空间的映射,使得在降低维度的同时减少信息损耗。
近年来涌现了许多高效的子空间学习方法。其中低秩表示方法由于较低的计算复杂度和其出色的性能,而广受研究和关注。但是大多数低秩表示方法都是直接将原始数据作为特征字典来进行学习的,这样的实验结果很大程度上会受到原始数据中错误信息的影响。于是我们为了解决这个问题,提出基于潜在特征空间的低秩表示方法。
2. 算法提出
2.1. 相关算法
给定原始数据的特征矩阵 ,其中列向量 表示一个样本。则低秩表示算法(Low-Rank Representation,LRR) [1] 的模型可以用如下目标函数表示:
(1)
其中, 为表示系数矩阵,E为重构误差。 表示 范数,其可以引导矩阵列稀疏。LRR算法将原始特征矩阵作为字典,通过对原始特征矩阵进行重构,来学习一个具有低秩约束的表示系数矩阵。这样Z通常可以揭示样本点之间的相似性关系,从而用来做无监督的聚类分析。
2.2. 算法引入
在一般情况下,LRR算法可以取得不错的聚类效果。然而在实际应用中,受到各种环境和人为等各种因素的影响,我们所得到的数据往往包含冗余特征和噪声信息。所以直接将原始特征矩阵作为字典,学习得到的表示系数矩阵通常会受到其中的不利因素的影响。为此,我们提出潜在特征空间学习方法,来减少这种负面影响:
(2)
其中 为正交字典, 为转换矩阵, 为重构误差。通过这种方式,我们可以利用原始数据重构,学习转换矩阵H,进而获得原始特征的潜在表示 。这样可以使得潜在特征在显式地保留原始数据的主要信息同时还能过滤噪声信息 。
进一步,我们结合低秩表示方法,并将 作为特征字典,可以得到基于潜在特征空间的低秩表示方法(Low-Rank Representation Algorithm Based on Latent Feature Space, LRRLFS),其目标函数为:
(3)
其中 作为正则化项,一方面可以使得学习得到的潜在特征表示更为紧凑,另一方面可以在一定程度上防止模型过拟合。
2.3. 算法优化
显然目标函数(3)并不是一个凸优化问题。但是我们可以采用交替直接最小化(Alternating Direction Minimization, ADM) [2] 技巧来对其进行优化。首先,引入辅助变量J和K来分别代替Z和 。那么目标函数表达式变为如下形式:
(4)
接着,我们将上式(4)转化为增强拉格朗日问题(Augmented Lagrange Multiplier, ALM):
(5)
其中 的定义为 。A表示拉格朗日乘数, 为惩罚因子。我们可以将上式(5)分解为多个子问题,并通过固定其他变量来更新单个变量。这样多次迭代之后,便能得到模型的近似解。具体子问题如下:
1) P步骤:固定其他变量,更新P。
(6)
定理1对于最小化问题 ,其最优解为 ,其中U和V分别表示对 进行奇异值分解(Singular Value Decomposition,SVD)分解后的左右奇异矩阵。
根据定理1 [3],我们将式(6)转化为类似的形式:
(7)
然后通过SVD得到 ,利用U和 来更新P:
(8)
2) H步骤:固定其他变量,更新H。
(9)
我们将上式(9)对H求偏导并设为零,便可以得到其最小化问题的解:
(10)
3) Z步骤:固定其他变量,更新Z。
(11)
我们将上式(11)对Z求偏导并设为零。便可以得到其最小化问题的解:
(12)
4) E步骤:固定其他变量,更新E。
(13)
(14)
引理1 给定B,则 的最优解 的第i列可以表示为:
(15)
根据引理1,我们可以依次更新 和 。
5) J步骤:固定其他变量,更新J。
(16)
我们可以利用奇异值阈值算法(Singular Value Thresholding, SVT) [4] 算法计算最优解 :
(17)
其中 表示SVT算法的收缩算子。
6) K步骤:固定其他变量,更新K。
(18)
我们将上式(18)对K求偏导并设为零,便可以得到其最小化问题的解:
(19)
7) 更新拉格朗日乘子:所有乘子均采用梯度下降法更新。
(20)
总上所述,我们可以得到LRRLFS算法如下:
3. 实验分析
3.1. 数据集及其预处理
在聚类实验中使用的4个数据集介绍及其预处理方式如下:
Yale B数据集 [5] 由2414张,38个类别的人脸图片组成。每一个类别大约包含63张不同光照条件下的正面人脸图片。超过一大半的图片都受到了不同程度的反射和阴影的损坏。我们将这些图片转换成灰度图片,然后下采样为32 × 32 像素的形式。最后将其转化为1024维的列向量并堆叠成特征矩阵。
PIE数据集 [6] 包含41,368张,68个类别的人脸图片组成。每张图片拍摄于不同的情况之下,其中包括4种不同表情,13种不同姿势,43种不同的光照条件。我们将这些图片转换成灰度图片,然后下采样为32 × 32 像素的形式。最后将其转化为1024维的列向量并堆叠成特征矩阵。
AR数据集 [7] 包含超过4000张,126个类别的人脸彩色图片。这些图片都是正面姿势拍摄,但是有不同的面部表情,光照条件和遮挡物(围巾和墨镜)。我们将这些图片转换成灰度图片,然后下采样为40 × 50像素的形式。最后将其转化为2000维的列向量并堆叠成特征矩阵。
COIL20数据集 [8] 包括1440张20个类别的图片。其中每个类别一共有72张拍摄角度相差5度的32 × 32像素的灰度图片。我们将其转化为1024维的列向量并堆叠成特征矩阵。
对于数量为c的不同聚类簇设定下,我们直接选取前c个类作为数据子集,并重复实验30次取平均作为最终结果。部分数据集图片示例如图1所示。
 (a) Yale B数据集
(a) Yale B数据集
 (b) PIE数据集
(b) PIE数据集
 (c) AR数据集
(c) AR数据集
 (d) COIL20数据集
(d) COIL20数据集
Figure 1. Image examples of different data sets
图1. 不同数据集的部分图片示例
3.2. 对比实验
我们采用Accuracy (ACC) [9] 度量来衡量实验结果的有效性。给定 ,令 和 分别表示对应的真实标签和预测标签。ACC的定义为:
(21)
其中,n表示样本数。当且仅当 时, 时。否则 。 为置换映射函数,其可以将每个的预测标签 映射到对应的数据集标签中。一般采用Kuh-Munkres Agorithm [10] 来寻找最佳的置换映射函数。
对比实验结果如表1~4所示。从中不难发现,LRRLFS算法相较于现有的基于低秩表示的算法有着更高效的聚类准确性。这是因为LRRLFS算法通过潜在特征表示,过滤了原始数据中的冗余特征和噪声信息。然后以其作为低秩表示学习的特征字典,获得具有清晰聚类结构的表示系数矩阵。

Table 1. ACC of different methods on Yale B data set
表1. Yale B数据机上不同算法的ACC
Table 2. ACC of different methods on PIE data set
表2. PIE数据集上不同算法的ACC
Table 3. ACC of different methods on AR data set
表3. AR数据集上不同算法的ACC
Table 4. ACC of different methods on COIL20 data set
表4. COIL20数据集上不同算法的ACC
3.3. 重构误差分析
为了进一步直观地展示LRRLFS方法在过滤冗余特征和噪声信息时的有效性,我们选取部分Yale B数据集的图片进行可视化处理。结果如图2所示。我们可以发现,潜在特征表示保留了大部分原始图片信息,而大多数的阴影噪声得到了过滤。
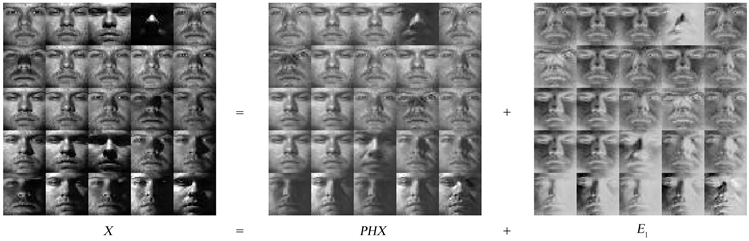
Figure 2. Reconstruction error on the Yale B data set
图2. Yale B数据集上的重构误差
4. 结论与展望
针对现有低秩表示方法的直接使用原始数据作为特征字典所带来的问题,我们提出了基于潜在特征空间的低秩表示方法。其在一定程度上避免原始数据中冗余特征和噪声信息对学习表示系数矩阵的不利影响,从而提升聚类性能。在未来工作中,我们会考虑将本方法扩展到多视图聚类领域。
文章引用
周翊航. 基于潜在特征空间的低秩表示算法
Low-Rank Representation Algorithm Based on Latent Feature Space[J]. 计算机科学与应用, 2021, 11(04): 1140-1148. https://doi.org/10.12677/CSA.2021.114117
参考文献
- 1. Liu, G., Lin, Z., Yan, S., Sun, J., Yu, Y. and Ma, Y. (2013) Robust Recovery of Subspace Structures by Low-Rank Representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35, 171-184. https://doi.org/10.1109/TPAMI.2012.88
- 2. Lin, Z., Chen, M. and Ma, Y. (2010) The Augmented Lagrange Mul-tiplier Method for Exact Recovery of Corrupted Low-Rank Matrices. Mathematical Programming, 9, arXiv:1009.5055.
- 3. Wahba, G. (1965) A Least Squares Estimate of Satellite Attitude. Siam Review, 7, 409-409. https://doi.org/10.1137/1007077
- 4. Cai, J.F., Candès, E.J. and Shen, Z.W. (2010) A Singular Value Threshold-ing Algorithm for Matrix Completion. SIAM Journal on Optimization, 20, 1956-1982. https://doi.org/10.1137/080738970
- 5. Georghiades, A.S., Belhumeur, P.N. and Kriegman, D.J. (2001) From Few to Many: Illumination Cone Models for Face Recognition under Variable Lighting and Pose. IEEE Transactions on Pattern Analysis and Machine Intelligence, 23, 643-660. https://doi.org/10.1109/34.927464
- 6. Sim, T., Baker, S. and Bsat, M. (2003) The CMU Pose, Illumination, and Expression Database. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25, 1615-1618. https://doi.org/10.1109/TPAMI.2003.1251154
- 7. Martínez, A. and Benavente, R. (1998) The AR Face Database. Technical Report. Computer Vision Center, Number 24, Bellatera. http://www.cat.uab.cat/Public/Publications/1998/MaB1998
- 8. Nene, S.A., Nayar, S.K. and Murase, H. (1996) Co-lumbia Object Image Library (Coil-20). Technical Report CUCS-005-96, February 1996.
- 9. He, X., Cai, D. and Han, J. (2005) Document Clustering Using Locality Preserving Indexing. IEEE Transactions on Knowledge and Data Engi-neering, 17, 1624-1637. https://doi.org/10.1109/TKDE.2005.198
- 10. Wessel, W. (1988) Lovász, L.; Plummer, M. D., Matching Theory. Budapest, Akadémiai Kiadó 1986. XXXIII, 544 S., Ft 680,—. ISBN 9630541688. Journal of Ap-plied Mathematics and Mechanics, 68, 146-146. https://onlinelibrary.wiley.com/https://doi.org/10.1002/zamm.19880680310