Computer Science and Application
Vol.08 No.08(2018), Article ID:26463,11
pages
10.12677/CSA.2018.88129
Research and Analysis of Digital City Based on Web Crawler
Jiawang Rao1,2, Yanyan Yang3, Ronghua Ma2*, Chenchang Du4
1Jiangsu Provience Surveying & Mapping Engineering Institute, Nanjing Jiangsu
2Nanjing Institute of Geography and Limnology Chinese Academy of Sciences, Nanjing Jiangsu
3Nanjing Jinling High School, Longhu Campus, Nanjing Jiangsu
4Qingdao Urban Planning & Design Research Institute, Qingdao Shandong

Received: Jul. 27th, 2018; accepted: Aug. 8th, 2018; published: Aug. 16th, 2018

ABSTRACT
Aiming at the shortage of the research on digital city, especially in collecting a large number of research literature on the basis of overall study on digital city which were lacked, stable and efficient crawler was designed based on the R language and the Selenium framework. Research papers of digital city before May 2018 collected on the National Knowledge Infrastructure (CNKI) were obtained through the web crawler, then the literature of database and the model of automatic word segmentation in terms of digital city were built. By analyzing the chronological research of digital city, the spatial distribution characteristics, and research focus in the research literature, the development of digital city research, the present situation, development trend and research hotspot were revealed. Results showed that the web crawler had designed in this article performing feasibility and effectiveness on collection digital city research literature.
Keywords:Digital City, Web Crawler, Text Mining, R Language
基于网络爬虫的数字城市研究与分析
饶加旺1,2,杨颜颜3,马荣华2*,杜臣昌4
1江苏省测绘工程院,江苏 南京
2中国科学院南京地理与湖泊研究所,江苏 南京
3金陵中学龙湖分校,江苏 南京
4青岛市城市规划设计研究院,山东 青岛

收稿日期:2018年7月27日;录用日期:2018年8月8日;发布日期:2018年8月16日

摘 要
针对数字城市研究手段不足,尤其在收集大量研究文献的基础上对数字城市进行整体研究上的欠缺,本文基于R语言和Selenium框架设计了稳定、高效的爬虫程序,获取了中国知网2018年5月前收录的数字城市为主题的研究文献,并建立了数字城市文献数据库和数字城市自动分词模型。通过分析数字城市研究的时序性、空间分布特征和研究热点,揭示了数字城市研究的发展历程、现状、发展趋势和研究热点。结果表明本文设计的网络爬虫程序在数字城市研究文献的收集方面具有可行性和有效性。
关键词 :数字城市,网络爬虫,文本挖掘,R语言

Copyright © 2018 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
数字城市源自“数字地球”的概念,是把城市的地理信息和其他与城市相关的信息结合并存储在计算机网络中,让城市和城市外空间连接在一起的虚拟空间 [1] 。目前数字城市的建设在全国多个省份、城市中展开,行业应用深入城市的各个领域。关于数字城市的研究,近年来虽然不乏技术和理论等方面的研究,但从获取大量的数字城市研究文献的角度对数字城市研究的发展历程、现状、发展趋势、研究热点的研究目前还没有。
网络爬虫是依据程序,模拟访问网页、自动化提取网页信息的脚本,是快速获取网页信息的一种方式 [2] 。网络爬虫按照类型主要分为通用型爬虫、面向主题爬虫、分布式爬虫三种 [3] ,相比较而言面向主题爬虫应用广泛,形式较为灵活,可针对特定的网页数据进行设计高效的爬虫程序。
本文采用面向主题的网络爬虫方法,以中国知网(National Knowledge Infrastructure, CNKI) 2018年5月前收录的以数字城市为主题的文献为研究对象,基于R语言和Selenium网络框架设计出网络爬虫程序。该程序对中国知网的网页进行分析,获取网页请求参数,模拟浏览器请求和响应服务器,最终获取了数字城市研究文献信息,将获取到的数据同步保存到本地,构建数字城市文献数据库(包括:编号、题名、作者、来源、发表时间、数据库、被引、下载次数、作者单位、摘要、关键词、资助基金共12个字段)。并以数字城市文献数据库为数据基础,基于文本挖掘技术构建了数字城市自动分词模型,通过分析数字城市研究的时序性、空间分布特征和研究热点,揭示了数字城市研究的发展历程、现状、发展趋势和热点。
2. 数字城市文献信息
在中国知网(http://www.cnki.net/)搜索框中输入“数字城市”,结果以表格形式展示数字城市文献的基本信息包括题名、作者、来源、发表时间、数据库、被引、下载(如图1红色框标记所示);每条文献都有具体的URL地址,以网页页面的形式展示文献的详细信息,包括作者单位、关键词、摘要、资助基金等信息(如图2所示红色框标记所示)。

Figure 1. Basic information of the digital city literature
图1. 数字城市文献的基本信息

Figure 2. Detail information of the digital city literature
图2. 数字城市文献的详细信息
根据上面的网页信息,本文设计了数字城市文献信息表,共12个字段,以题名为主键,考虑到不同的文献的摘要、基金、关键词不一定全部包含,在设计时将摘要、基金、关键词字段设置可为空(见表1);同时,为确保数据正常入库,将题名、作者、作者单位、来源、数据库、关键词设置为长度可变化的字符类型。MySQL是目前较为流行的关系型数据库管理系统,具有数据交互速度快、体积小、开源和免费的特点而应用广泛 [4] ,因此本文选用MySQL作为数字城市文献信息表的存储载体。
3. 爬虫程序的设计与实现
结合数字城市文献信息情况,本文选用了面向主题的爬虫方法,基于R语言,结合Selenium网络框架设计了网络爬虫程序。Selenium是一个支持跨操作系统、支持多种浏览器的用于Web应用程序测试的开源式框架,具有测试系统、测试框架和测试脚本等多种功能 [2] 。本文使用Selenium网络框架,在于测试爬虫程序,模拟浏览器请求服务器,达到不直接使用浏览器实现数据抓取的目的。网络爬虫程序分为数据抓取、数据处理、数据入库三个模块,最终将抓取的文献信息存储到MySQL数据库中,形成数字城市文献数据库,如图3所示。
3.1. 数据抓取
数据抓取是整个爬虫程序的关键,也是构建数字城市文献数据库的关键。数据抓取分为两个部分:1) 在中国知网中输入“数字城市”查询关键词,获取网页请求的Cookie等信息,以GET方式向服务器发送请求,服务器接受到请求后,返回响应报头信息,客户端根据响应信息和返回的数据判断服务器是否正常响应,判断返回的数据是否为空,如果为空则继续响应,如果不为空则获取了文献的概要信息(包括题名、作者、来源、发表时间、数据库、被引、下载和所有文献URL信息);从文献概要信息中提取文献信息集I (包括题名、作者、来源、发表时间、数据库、被引、下载)和文献URL信息。2) 将URL信息进行数据重构与格式化处理,使用Selenium网络框架模拟请求服务器,遍历每个文献的URL,判断服务器响应是否响应、数据内容是否为空,如果不为空则获取了文献信息集II (包括题名、摘要、关键词、资助基金、作者单位),如果为空,则得到文献信息III集(与文献信息集II包含的字段内容相同,不同的

Table 1. Information of digital city literature
表1. 数字城市文献信息表

Figure 3. Flowchart of web crawler
图3. 爬虫程序流程图
是文献信息集III中除题名、作者单位外其余内容全部或部分为空值)。
程序运行过程中要注意的问题有:第一,文献抓取的过程中,为保证爬虫程序的稳定性,以及避免直接请求服务器带来的异常和服务器禁止固定的IP频繁访问,使用Selenium网络框架,模拟请求服务器。
第二,针对文献包含的摘要、关键词、资助基金的个数不同,为便于数据入库和后期的数据处理,采用如下策略:
1) 当返回的摘要信息为空时,表明该文献无摘要,将摘要信息赋予空值;
2) 当无资助基金信息返回时,将资助基金赋予空值;
3) 当返回的关键词信息为空时,此时将关键词赋予空值。
第三,当遇到服务器无响应,即连续请求超过3次时(程序抓取不到数据),强制程序自动休眠一段时间再重启数据抓取,避免客户端硬件和软件多余的资源消耗。
第四,为提升数据的抓取效率,在获取文献的概要信息时,只解析文献列表所在的表格,而不对整个页面进行解析。
3.2. 数据处理
抓取模块结束后,进行数据处理,主要分为两个步骤。
1) 考虑到抓取文献信息的字段不同,为了便于数据的处理与入库,抓取的文献信息集I、II、III的均设置为List格式(List是R语言常用的数据结构,常用于存储长度和属性不同的数据)。由于文献信息集II~III的字段一致内容,先合并两者;根据题名一一对应的原则,使用循环与递归的方法,将文献信息集I与合并后的II和III进行重组,并将结果保存到新建的List列表中,此时的文献信息包括编号、题名、作者、作者单位、来源、发表时间、数据库、被引次数、下载次数、摘要、资助基金和关键词共12个属性。
2) 根据文献的标题与内容,通过人工判别的方法去除广告、征文等无关信息,最终抓取到9661条文献。
3.3. 数据入库
把处理好的文献数据按照文献信息表,批量存储到本地MySQL数据中,形成数字城市文献数据库,作为本文文本挖掘、数据的分析与可视化的基础。
4. 自动分词模型的构建与实现
题名是论文内容和研究方向的总结和概括,通过挖掘题名获取高频词汇信息,能够反映研究领域的热点问题和发展动向 [5] 。中文分词是文本挖掘的基础,是本文高频词汇提取的关键,分词方法主要有基于字典、词库匹配,词频度统计和知识理解三种 [6] [7] ,Jieba分词是目前主流的中文分词方法,该方法基于Trie树结构的算法和前缀词典,首先对文本进行词图扫描,生成句子中所有可能词组的有向无回路图(Directed Acyclic Graph, DAG);同时将规则和统计结合、采用了动态规划查找最大概率路径,识别出语料文档中所有可能构成词的最大切分组合;对于未登录的词汇,采用隐马尔可夫模型(HMM)来预测分词,从而实现中文分词 [8] ,目前Jieba分词支持多种开发语言,具有使用方便、分词精度高等优点。国内有学者在改进Jieba分词算法 [9] 和语料库的优化 [10] 上做了大量的研究与实践,但在构建数字城市的自动分词模型和语料文档方面还没有研究,而实际使用Jieba分词会存在如下问题。
1) 隐马尔可夫模型对专有名词和新词的识别度较低,如“数字城市”、“大数据”等存在严重的误分情况;
2) Jieba分词的前缀词典更新速度慢,无法满足分词所需的各类专业词汇。
语料文档和词典直接关系分词的效率和准确度。提取数字城市文献数据库Title字段信息,通过去除特殊符号、信息的整合等处理,构建了约15.6万字的数字城市原始语料文档。依据原始语料文档中既包括了测绘科学、地理信息系统、计算机等领域的专业名词,又包括了诸如“实现”、“原理”等常用的普通名词,“的”、“和”、“在”等无实际意义的词和省市县(区)街道等地名信息,增加词典的种类和数量不仅会导致分词效率降低,往往还会出现部分词汇错分的情况。为此,本文对语料文档和词典入手,使用Jieba分词方法,构建了数字城市语料文档的自动分词模型,提取了高频词汇,流程如图4所示。
1) 从语料文档入手,建立基础语料文档、停用词语料文档、专业语料文档和地名地址语料文档。
①基础语料文档:来源于人民日报1998年标注语料库、微软研究院标注语料库;
②停用词语料文档:从人民日报1998年标注语料库提取形成;
③专业语料文档:文献的关键词是研究方向专业术语的重要来源,提取数字城市文献数据库的Keyword信息,按照分词词典的格式要求,对关键词进行单一化处理形成;
④地名地址语料文档:来源于中国地名录 [11] 、民政部全国行政区划查询平台 [12] 的行政区划信息(省市县乡镇)四级地名信息。
2) 语料文档预处理:基于面向词向量的文档对比算法 [13] ,对基础语料文档、专业语料文档和地名地址语料文档进行对比分析,找出相同的词汇和不同的词汇,通过整合最终得到既包括基础语料文档,又包括专业语料文档和地名地址语料文档的“新词典”,在分词过程中省去了重复检索不同语料库中包含相同词汇的时间;
3) 基于Jieba分词方法,结合停用词、新词典,编写R语言代码实现对数字城市原始语料文档的分词;
4) 通过人工判读的方法对分词结果进行评测,结果表明本文构建的自动分词模型在分词速度和准确度上,比未处理语料库和词典的分词方法分别提高了4.5%和6.3%;
5) 最后在统计分析的基础上,在分词结果中提取了高频词汇。
5. 结果与分析
5.1. 数字城市研究的时序性分布
研究数字城市文献的时序性分布在于分析数字城市的发展历程、现状和发展趋势,探究其随时间分布的主要决定因素。提取数字城市文献数据库中的Publish Data (文献发表时间),通过信息的整合,得到了数字城市研究文献的时间分布(如图5所示)。数字城市相关的研究文献最早出现在1983年,是关于城市数字移动通信的报道 [14] ,到1999年之前,中国知网收录的关于数字城市的文章很少,每年均不足10篇;1999年~2011年呈增长状态,特别是2006年~2011年期间呈现快速增长(由2006年的450篇增加到2011年的895篇,年均增加89篇);2011年以后数字城市研究论文发表数量呈现逐年下降的趋势。
究其原因:数字城市的建设是一项涉及技术、资金、数据、管理理念等多方面的综合工程 [15] ,1999年之前相关的技术、理念、数据等还比较薄弱,数字城市相关的研究较少,1999年首届国际“数字地球”大会在北京召开后,与“数字地球”相关的概念如“数字中国”、“数字省”、“数字城市”等名词不断涌现 [16] ,数字城市相关论文的发表呈增加状态;2006年国家测绘地理信息局启动了数字城市建设工作,数字城市建设相关的各类技术标准、规范、运行维护机制不断出台,在国家和各省市的大力推广下,数字城市的研究热度呈现高速上升;2011年出现下降的趋势,主要原因有:1) 数字城市建设周期较长、
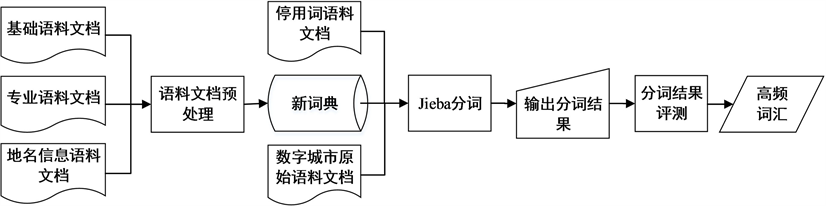
Figure 4. Flowchart of automatic segment model
图4. 自动分词建模流程图

Figure 5. Time distribution of the literature of digital city
图5. 数字城市研究文献的时间分布
相关理论研究和建设技术已成熟;2) 2012~2013年193城市先后被确认为国家级智慧城市试点城市,工作重心转向智慧城市的研究与建设;3) 全国270多地级市开展的数字城市建设全部完成,市县级数字城市建设工作的收尾 [15] 。截止2018年4月底,中国知网收录的数字城市相关文献为61篇,预计2018全年收录的数字城市相关的研究文献将低于2017年的444篇。
5.2. 数字城市研究的空间分布
数字城市研究的空间分布特征从研究机构和资助基金两个方面论述。
提取文献数据库Author Unit (作者单位)字段,当文献的作者只有一个单位时,记录一次;有两个或多个单位时,按照每个单位出现一次记录,形成机构单位信息,便于分析,提取了发表论文数量在40篇及以上的机构单位信息,如表2所示。排名前20的发文机构中,全部为高校和研究机构,是数字城市高产发文机构,是数字城市研究的前沿,其中武汉大学以179篇排名第一,该校测绘遥感信息工程国家重点实验室成功解决构建数字城市的关键技术:三维模型快速构建、海量数据动态装载和多类型空间数据有效组织和管理等;华中科技大学建设的水电能源综合研究仿真中心,进行数字城市和数字流域相关研究,解决了数字城市建设中诸多问题,以85篇文章排名第二。学位论文的数量作为衡量高校专业实力水平的指标,提取文献数据库中Database (数据库)信息,把标记有“博士”、“硕士”的文献合并为“学位论文”,根据表2的机构单位名称得到了相应的学位论文数量。从学位论文数量占高校整体论文数量的比例分析,电子科技大学、西安科技大学、吉林大学、昆明理工大学的比例分别为88%、80%、77%、70%,表明这些高校更注重数字城市方向的专业化培养。
提取数字城市文献数据库的Funding (资助基金)信息,统计基金名称出现的次数,并按照降序排列,选取了前20个基金资助的文献数进行分析,见表3,其中国家自然科学基金、“863计划”、“973计划”、国家科技支撑计划等国家级基金资助为349篇,显示国家层面对数字城市研究的重视程度;省级基金方面,江苏省以16篇位居第一位,位于数字城市研究的前沿,湖南、山东、北京、广西分列第二至第五位,如表3所示,这与市县级数字城市在各省普遍开展建设有关。
5.3. 数字城市研究的热点
词汇云图(Word Cloud)是基于词汇频率的布局算法 [17] ,最早由美国Rich Gordon教授提出,用文字
Table 2. Research institutions published more than 20 articles
表2. 发表文献超过20篇的机构分布表
Table 3. Information of fund
表3. 资助基金分布情况
的体积表征词频大小,不同的词汇标记不同的颜色,通过颜色和大小直观的反映词汇的重要性差异,对于体量大、覆盖范围广的信息有过滤不必要的信息,凸现有用信息的作用,被越来越多的用于热点分析 [18] 。利用R语言Word Cloud 2 [19] 功能包对提取的高频词汇(Top 50 (频次大于等于137))进行可视化分析,得到数字城市的可视化词汇云,如图6所示。“城市”、“数字城市”、“数字”、“建设”、“研究”位列高频词汇前五位,表明数字城市的建设与研究离不开“城市”这个主体;高频词汇中同时出现了“数字城管”、“城市规划”、“测绘”、“地理信息系统”、“平台”、“三维”、“地理空间框架”、“数据”、“模型”等数字城市应用领域和建设内容以及“基于”、“设计”、“探讨”、“浅谈”、“打造”、“实践”等研究方法和技术手段。数字城市的研究热点主要涵盖了研究主体、应用领域、建设内容,研究方法和技术手段。
6. 结论
本文以中国知网收录的数字城市为主题的文献为研究对象,基于R语言和Selenium网络框架,设计了网络爬虫程序,高效地获取了中国知网2018年5月前收录数字城市研究文献,建立了数字城市文献数据库和自动分词模型,分析了数字城市的时序性、空间分布特征和研究热点,结论如下:

Figure 6. Word cloud of digital city
图6. 数字城市可视化词汇云
1) 数字城市研究文献发表的数量与相关重大会议和国家政策关联紧密,文献发表数量于2011年达到最大,之后呈逐年下降的趋势,预测2018年数字城市研究文献的数量将低于2017年的444篇;
2) 国家级和省级基金资助中,国家级基金更多地应用在数字城市的研究中,高校和研究机构是数字城市研究的前沿和论文发表的高产机构,其中武汉大学、华中科技大学和电子科技大学等机构表现突出;
3) 数字城市的研究热点主要涵盖了研究主体、应用领域、建设内容,研究方法和技术手段。
结果表明本文设计的网络爬虫程序解决了文献信息获取难的问题,在揭示数字城市研究的发展历程、现状、发展趋势和研究热点方面不仅具有可靠性,而且丰富了数据收集方法,节省了数据收集的时间。在今后的研究中,主要工作将集中在挖掘数字城市文献数据库的空间属性,如提取地名信息,用于分析全国范围内数字城市研究的空间差异性以及主要原因,为政府决策提供辅助性支持。
基金项目
国家自然科学基金: (41771366);山东省住房城乡建设科技计划项目: (2018-R1-16)。
文章引用
饶加旺,杨颜颜,马荣华,杜臣昌. 基于网络爬虫的数字城市研究与分析
Research and Analysis of Digital City Based on Web Crawler[J]. 计算机科学与应用, 2018, 08(08): 1172-1182. https://doi.org/10.12677/CSA.2018.88129
参考文献
- 1. 李德仁, 邵振峰, 杨小敏. 从数字城市到智慧城市的理论与实践[J]. 地理空间信息, 2011, 9(6): 1-5.
- 2. Munzert, S., Rubba, C., Meißner, P., et al. (2015) Automated Data Collection with R: A Practical Guide to Web Scraping and Text Mining. John Wiley & Sons, Hoboken.
- 3. Khurana, D. and Kumar, S. (2012) Web Crawler: A Review. International Journal of Computer Science & Management Studies, 12, 31-36.
- 4. Widenius, M. (2002) Mysql Reference Manual. O’Reilly & Associates, Inc., Sebastopol, California.
- 5. 雷晓庆, 刘晓雁. 论文关键词特征的统计分析[J]. 图书情报工作, 1998, 32(5): 19-20.
- 6. 奉国和, 郑伟. 国内中文自动分词技术研究综述[J]. 图书情报工作, 2011, 54(2): 41-45.
- 7. 于重重, 操镭, 尹蔚彬, 等. 吕苏语口语标注语料的自动分词方法研究[J]. 计算机应用研究, 2017, 34(5): 1325-1328.
- 8. Sun, J.Y. jieba中文分词[EB/OL]. https://github.com/fxsjy/jieba, 2016-04-20.
- 9. 王瑞雷, 栾静, 潘晓花, 等. 一种改进的中文分词正向最大匹配算法[J]. 计算机应用与软件, 2011, 28(3): 195-197.
- 10. 赵知纬, 钱龙华, 周国栋, 等. 一个面向信息抽取的中文跨文本指代语料库[J]. 中文信息学报, 2015, 29(1): 57-66.
- 11. 国家测绘局地名研究所. 中国地名录[M]. 北京: 中国地图出版社, 1997.
- 12. 民政部全国行政区划查询平台[EB/OL]. http://xzqh.mca.gov.cn/map
- 13. Collobert, R. and Weston, J. (2008) A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. International Conference on Machine Learning, Helsinki, 5-9 July 2008, 160-167. https://doi.org/10.1145/1390156.1390177
- 14. 仵克让. 适用于城市数字移动通信的最佳码速[J]. 通信学报, 1983(4): 87-92.
- 15. 方维慰. 中国建设数字城市的难点与对策[J]. 软科学, 2004, 18(3): 71-73.
- 16. 李景宜, 石长伟, 傅志军, 等. 首届“数字地球”国际会议在北京召开[J]. 地球信息科学学报, 2000, 2(1): 5-5.
- 17. Kwartler, T. (2017) Text Mining in Practice with R. John Wiley & Sons, Ltd., Chichester, UK. https://doi.org/10.1002/9781119282105
- 18. Halvey, M.J. and Keane, M.T. (2007) An Assessment of Tag Presentation Techniques. International Conference on World Wide Web (WWW 2007), Banff, Alberta, Canada, 8-12 May 2007, 1313-1314. https://doi.org/10.1145/1242572.1242826
- 19. Lang, D. and Chien, G. (2018) WordCloud2[EB/OL]. https://CRAN.R-project.org/package=wordcloud2