Hans Journal of Data Mining
Vol.
10
No.
01
(
2020
), Article ID:
33873
,
8
pages
10.12677/HJDM.2020.101004
Clustering Of Passenger Picked-Up Areas and Analysis of Hot Spots Based on Taxi Business Data
Hongyang Wang
School of Information Technology & Management, University of International Business and Economics, Beijing
Received: Dec. 21st, 2019; accepted: Jan. 1st, 2020; published: Jan. 8th, 2020

ABSTRACT
To optimize the taxi space resource dispatch, a clustering model using OPTICS algorithm is proposed for the clustering of taxi passenger carrying area under the condition of intensive road and small difference in data density. By comparing with the results of the traditional DBSCAN algorithm in experiment, it is found that the OPTICS algorithm can effectively eliminate the interference of parameter setting on the experimental results. It helps to the problem of traditional algorithm DBSCAN applied to such situation, and enhances the efficiency of taxi dispatch. This research has practical guiding effect on improving the load factor of taxi and reducing the time of idle load.
Keywords:Taxi, Passenger Picked-Up Areas, OPTICS

基于出租车运营数据的载客区域聚类及热点特征分析
王弘扬
对外经济贸易大学信息学院,北京
收稿日期:2019年12月21日;录用日期:2020年1月1日;发布日期:2020年1月8日

摘 要
为优化出租车空间资源调度,针对路网密集、数据密度差异较小条件下的城市出租车载客区域聚类问题,本文提出了一种采用OPTICS算法的聚类模型。通过实验与传统DBSCAN算法下的聚类结果进行对比,发现OPTICS算法更能有效地避免参数设置对实验结果的影响,解决传统DBSCAN算法在此类应用中聚类划分模糊的问题,达到出租车资源调度精细化的效果,对提升出租车载客率、降低空载时间具有现实指导作用。
关键词 :出租车,载客区域,OPTICS

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
出租车市场供求不平衡问题是导致出租车司机收入、满意度下降的直接原因,间接导致司机调度距离过长,乘客超时等待取消订单等问题,直接制约出租车市场的发展,而出租车市场的供需不平衡问题往往具有短期、局部区域性等特点,如何更好地实现资源调度、满足出行需求是学术界和业界一直在探索的问题。
在互联网环境下,依托数据挖掘和大数据技术的发展,此类问题有着天然的应用场景和解决优势。郑林江等人 [1] 提出一种基于网格密度的聚类算法,将轨迹点投影在按网格划分的空间区域上,并根据轨迹点网格密度设定阈值,确认热点区域网格单元。Rami Ibrahim [2] 在研究中发现与随机交换聚类算法的聚类结果在均方误差和聚类质量上要优于基于层次密度的空间聚类算法。桂智明 [3] 基于MapReduce方法将出租车行驶轨迹中的轨迹点进行聚类并匹配路网得到其行驶轨迹,减少了轨迹中无意义簇的生成,实现了更具优势的轨迹聚类。姬波 [4] 基于信息论来研究出租车的空载密集区域,从而达到提高载客率的效果。毕硕本 [5] 使用Ripley’K函数检验出租车上下客事件的空间聚集关系,分析出租车运营的周期性变化特征及时空分布规律,发现出租车运营具有明显的早晚高峰期,且工作日和非工作日也有较大差别。曲昭伟 [6] 提出轨迹线密度方法,并实际运用于成都市春熙路商圈,根据当地路网密度值划分路段热点,识别热点位置,并依据实际的出行数据对该方法进行实证分析,发现该方法对出行需求量高的路段区域具有更明显的识别效果。Tang [7] 将DBSCAN应用于哈尔滨市不同区域的出租车上下客区域聚类,通过从DPS数据中提取的行程距离、时间、载客状态和非载客状态下的平均移动速度等影响因素来研究乘客的移动行为,并应用观测到的城市中心区OD矩阵建立了基于熵极大化方法的交通分布模型。
互联网条件下,出租车市场大量的运营数据有力地驱动本问题的解决。出租车需求在时间、空间上具有一定的相似性,而随着时间的推移,出租车需求在空间上不断地转移,形成一定潮汐效应的同时又有着实时差异。
为了探究城市出租车需求在时间上的精细变化,减少司机等待、空车时间,提升资源调度效率,本文将基于DBSCAN算法和OPTICS算法对出租车载客热点区域进行聚类划分并对比两种方法的聚类结果差异,证明OPTICS算法在应对簇间轮廓模糊的数据集时能更有效地划分簇结果,为具有不同路网类型的城市出租车载客热点预测提供新的参考。
2. 数据预处理
实验数据采自纽约市2009年~2015年间的100万条出租车运营数据,每一条数据包含一次出租车行程单的7个属性,包括乘客上车时间、上下车经纬度、乘客人数、费用等信息。
首先删除包含缺失值或明显异常值的数据;由于纽约城临海,行程起终点GPS定位信息落于海中的数据量要大于内陆城市,本文选择将起终点地点落于水域的数据删除,得到978,643条数据。
经过初步的数据清洗,噪音数据有效减少,即便仍存在的小部分起终点距离过大的数据难以区别是否真实有效,因其数据量不足一百条,不足以对实验产生明确影响。对时间数据进行变量分类转换,区分月份、星期几、第几小时等离散化变量。
新增行程起终点距离属性列,起终点距离为:
其中:
3. 聚类建模
3.1. DBSCAN算法介绍
DBSCAN算法 [8] 是最为知名的基于密度的聚类算法,尤其广泛应用于空间密度聚类领域。
概念:
假设具有样本集 。
邻域:对于任一点
,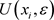 称为
的邻域,邻域内所有的点与
的距离都不大于
, 在
邻域内的点的集合为
。
称为
的邻域,邻域内所有的点与
的距离都不大于
, 在
邻域内的点的集合为
。
:定义使得核心点成立的 邻域内最低点数。
核心点:如果一个给定点 在其 邻域内至少有 个样本点,那么就称该给定点 为核心点。
密度直达:对于核心点 ,如果存在样本点 满足 和 间的距离不大于 ,那么称 密度直达 。
密度可达:对于一系列样本点
,如果存在如下关系:
密度直达
,那么 密度可达
。
密度可达
。
密度相连:在给定 及 条件下,存在样本点 同时可由另一样本点 密度可达,则称样本点 密度相连。
DBSCAN算法核心思想可以解释为:对于样本集合中任意一个样本点 ,根据 及 条件判断该样本点是否为核心点,若点 是核心点,则依照密度直达的方式寻找其 邻域内所有样本点集合
,再判断 内所有点是否为核心点,重复该步骤
寻找所有由 出发密度相连的点构成一个簇,直至样本集D中所有的点都落入某个簇集合或非簇集合。
DBSCAN作为一种基于空间密度地聚类算法,发现一个密度区域后以密度可达的方式拓展簇的范围,其聚簇轮廓往往是极不规则的,DBSCAN在面对非凸集数据的时候体现了出色的聚类能力及抗噪能力。
3.2. OPTICS算法介绍
OPTICS算法 [9] 是一种基于DBSCAN的改进算法。由于DBSCAN在面对未知数据分布情形下对 邻域及Pmin值过于敏感,不同的参数选择对于其聚类结果产生较大的影响,也容易影响其聚类质量,在面对不断变化的密度空间数据时缺乏可控性。针对以上缺点,学者对其提出了改进型算法OPTICS。
概念:
在DBSCAN相关概念的基础上,OPTICS算法引入了两个新的定义。
核心距离:样本 ,对于给定 和 ,如果 内存在至少 个样本点,那么 内
与 距离相近的第 个点与x之间的距离就是x的核心距离。 为样本x在其 邻域内距离x第
近的点,其数学表达式如下:
可达距离:样本 ,对于给定 和 , 之间的可达距离为:
直接密度可达:对于样本 ,若x为核心点, ,则称x到y直接密度可达。
计算过程:
1) 输入数据样本集合 ,设置参数 和 。
2) 初始化序列A和B。
3) 判断集合 中是否存在未处理样本点,是则转入步骤4,否则算法结束。
4) 选择一个 中未处理的核心点,将该核心点放入A序列,并将该核心点的直接密度可达点按可达距离升序排序放入B序列。
5) 判断B序列是否为空,是则转入步骤3,否则转入步骤6。
6) 选择B序列第一个点,将该点放入A序列,若该点为未处理核心点则将该点直接密度可达点放入B序列,并将B序列重新排序,否则转入步骤5。
7) 重复步骤3。
8) 算法结束。
4. 评价标准
Davies-Boulding指数(DBI)
DBI指数戴维森堡丁指数 [10],是一种针对聚类结果的无监督评价指标,由Davies, D.L.,Bouldin, D.W.提出。该方法首先定义了一个变量 :
式中 代表第i个簇中的数据点个数, 代表簇i中的第j个数据点, 为簇i的簇核心,p值用于调整距离计算方法;变量 衡量的是簇内样本点与簇核心的距离均值。
其次,DBI指数定义了变量 :
表示第i个簇的簇核心的第k个属性值,也就是说, 衡量的是第i个簇和第j个簇的簇核心间距。
随后,DBI指数定义了变量 :
用于衡量第i个簇和第j个簇之间的相似度。
则为第i个簇与其他簇的相似度的最大值:
最终得到DBI指数:
可见,DBI指数非常良好地解释了聚类结果的离散程度,当同一簇内样本点离散程度较低而样本集合内各个簇核心间距较大时,DBI指数较小,聚类结果簇集划分效果较明显。
5. 实验
实验环境:Windows10 x86操作系统,Python为3.6版本,scikit-learn为0.21.3版本。
对本数据集打车起终点距离进行统计,统计结果如图1所示。
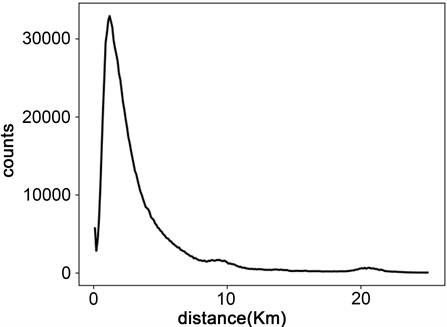
Figure 1. Distance frequency chart of the taxi journey
图1. 打车起终点距离频数分布
数据表明,本数据集打车起终点距离均值为3.32千米,标准差为3.73千米,50%的行程起终点距离在1.25千米至3.92千米之间,图1横轴位于10千米和20千米处各有一个较为明显的突起,通过后续聚类结果发现原因为该城市航空公共交通基础设施客流聚集。可以看出,打车需求以中短程需求为主。
考虑到随时间推移城市交通设施结构的变化对数据的影响,本文选择2013、2014年周一至周五9:00~10:00期间产生的行程数据作为模型输入。
5.1. DBSCAN算法实验
使用DBSCAN对其空间位置进行聚类,通过网格搜索的方式确定一个较为合理的聚类结果,选择在 邻域取值100米, 取值14条件下,其空间聚类结果如图2所示,灰色点为非簇样本,粉色点为所有样本数低于100的簇样本。
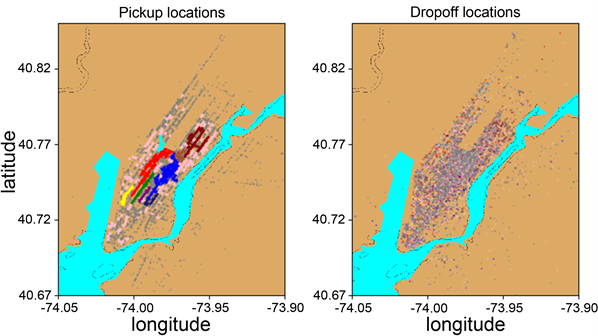
Figure 2. Result of DBSCAN clustering experiment
图2. DBSCAN算法空间聚类结果
5.2. OPTICS算法实验
使用OPTICS对同一数据进行聚类,同样使用网格搜索的方式寻找局部较优参数,设置 为5,max_eps为0.05千米,空间聚类结果如图3所示,灰色点为非簇样本,共有9个样本数大于100的彩色簇集。

Figure 3. Result of OPTICS clustering experiment
图3. DBSCAN算法空间聚类结果
5.3. 实验结果统计与分析
两种方法得出的主要簇样本统计结果如表1~2所示。

Table 1. Statistics of the main clusters under DBSCAN
表1. DBSCAN聚类结果主要簇的样本点统计
Table 2. Statistics of the main clusters under OPTICS
表2. OPTICS聚类结果主要簇的样本点统计
Table 3. Comparison of clustering results under DBSCAN and OPTICS
表3. DBSCAN和OPTICS算法下聚类结果对比
根据实验结果的统计数据可知,OPTICS算法下的实验结果具有更低的DBI指数,这表明各簇内样本点的离散程度低而簇间核心间距较大,具有明显的聚簇划分效果。本方法相较于常用的DBSCAN方法更利于出租车载客区域空间密度的划分,便于运营人员明确核心区域中心,将空载率高的区域车辆向高载客频率区域调度,减少出租车空载时间和乘客等待时间。
6. 结论
由于纽约市出租车载客区域更为密集,且簇间轮廓较为模糊,特定城市的载客热点聚类应当因地制宜采用不同的方法,本文在前人研究的基础上,分别采用DBSCAN和OPTICS两种算法对纽约市出租车载客区域进行了聚类划分,多次调参取得实验结果差异如表3所示,DBI差异明显,可见OPTICS算法在面对簇间轮廓模糊的数据集时可以很大程度上避免 邻域及 值设置所带来的实验干扰,聚类效果强于DBSCAN。
本研究有助于解决不同城市路网条件下出租车的资源调度问题,对大数据精细化运营有重要的现实意义。
文章引用
王弘扬. 基于出租车运营数据的载客区域聚类及热点特征分析
Clustering Of Passenger Picked-Up Areas and Analysis of Hot Spots Based on Taxi Business Data[J]. 数据挖掘, 2020, 10(01): 39-46. https://doi.org/10.12677/HJDM.2020.101004
参考文献
- 1. 郑林江, 赵欣, 蒋朝辉, 邓建国, 夏冬, 刘卫宁. 基于出租车轨迹数据的城市热点出行区域挖掘[J]. 计算机应用与软件, 2018, 35(1): 1-8.
- 2. Ibrahim, R. and Omair Shafiq, M. (2019) Detecting Taxi Movements Using Random Swap Clustering and Sequential Pattern Mining. Journal of Big Data, 6, 1-26.
https://doi.org/10.1186/s40537-019-0203-6 - 3. 桂智明, 向宇, 李玉鉴. 基于出租车轨迹的并行城市热点区域发现[J]. 华中科技大学学报(自然科学版), 2012(S1): 187-190.
- 4. 姬波, 叶阳东, 肖煜. 基于信息瓶颈方法的出租车空载聚集区聚类算法[J]. 小型微型计算机系统, 2013, 34(9): 2139-2143.
- 5. 毕硕本, 万蕾, 杨树亮, 闫业超, Nkunzimana Athanase. 基于GPS数据的南京出租车上下客时间特征及热点时空分布[J]. 中国科技论文, 2018, 13(9): 1023-1028.
- 6. 曲昭伟, 王鑫, 宋现敏, 夏英集, 袁咪莉. 基于出租车GPS大数据的城市热点出行路段识别方法[J]. 交通运输系统工程与信息, 2019, 19(2): 238-246.
- 7. Tang, J.J., Liu, F., Wang, Y.H., et al. (2015) Un-covering Urban Human Mobility from Large Scale Taxi GPS Data. Physica A: Statistical Mechanics and its Applications, 438, 140-153.
https://doi.org/10.1016/j.physa.2015.06.032 - 8. Ester, M., Kriegel, H.P., Sander, J., et al. (1996) A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. International Conference on Knowledge Discovery & Data Mining, Portland, 2-4 August 1996, 226-231.
- 9. Ankerst, M., Breunig, M., Kriegel, H.P. and Sandler, J. (1999) OPTICS: Ordering Points to Identify the Clustering Structure. Proceedings of the Interna-tional Conference on Management of Data (SIGMOD’99), Philadelphia, 1-3 June 1999, 49-60.
https://doi.org/10.1145/304182.304187 - 10. Davies, D.L. and Bouldin, D.W. (1979) A Cluster Separation Meas-ure. IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-1, 224-227.
https://doi.org/10.1109/TPAMI.1979.4766909