上海理工大学,理学院,上海
收稿日期:2023年12月20日;录用日期:2023年12月29日;发布日期:2024年1月31日

摘要
本文研究了强化学习方法在线性二次控制问题(LQR)中的应用。在LQR问题的研究中,常见的方法通过求解代数黎卡提方程得到最优控制,并不直接优化控制增益。本文在策略梯度算法的基础上引入资格迹方法,直接优化控制增益矩阵。考虑已知和未知参数两种情况下,资格迹方法的收敛。在有限时域和高斯噪声的条件下,分别给出了已知和未知参数两种情况下算法的全局收敛保证。参数未知时,利用零阶优化定理近似梯度项,这可以将问题扩展至代价函数非凸的情况。数值模拟结果显示资格迹方法与梯度下降算法相比更快收敛,方差更小。
关键词
线性二次最优控制,梯度下降,资格迹

Eligibility Trace Method for Stochastic Linear Quadratic Control
Yanan Zhu
College of Science, University of Shanghai for Science and Technology, Shanghai
Received: Dec. 20th, 2023; accepted: Dec. 29th, 2023; published: Jan. 31st, 2024

ABSTRACT
This paper studies the application of reinforcement learning method to linear quadratic regulator (LQR) problem. For the study of LQR problem, the usual method is to obtain the optimal control by solving the algebraic Riccati equation, but not to optimize the control gain directly. This paper optimizes the control gain directly, proposes the eligibility trace method on the basis of gradient descent algorithm, and produces global convergence guarantee in the case of known and unknown parameters, in the setting of finite time horizon and Gaussian noise. When the parameters are unknown, the zero-order optimization theorem is used to approximate the gradient term, which can extend the problem to cases where the cost function is not convex. Numerical simulation results show that the eligibility trace method has faster convergence and smaller variance than gradient descent algorithm.
Keywords:Linear Quadratic Optimal Control, Gradient Descent, Eligibility Traces

Copyright © 2024 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
线性二次型控制(LQR)问题是最优控制理论中最基本的问题之一,系统下一时刻的状态由当前状态和控制决定,代价是关于状态和控制的二次函数 [1] 。问题的目标是找到最优的系统控制,使得代价函数达到最小值。在系统参数完全已知的情况下,LQR问题已经有广泛的研究,最优控制存在解析表达式 [2] ,被广泛应用在不同领域中。在实际应用中,获取系统所有参数时不现实的,当系统参数未知时,产生许多不确定性,无法直接求解得到最优控制,这促进了对学习方法的探索。
近年来使用强化学习和数据驱动方法解决不确定动力系统问题取得重要进展,强化学习方法成为解决此类不确定问题的有效手段。强化学习(RL) [3] 是交互式的学习方法,通过与环境交互积累经验(采样),以最大化数值收益信号为导向,不断从经验中学习,最终得到最优策略(控制)。在已有的研究中,利用RL方法解决参数未知的LQR问题,有基于模型的方法 [4] [5] [6] 和无模型的方法 [7] [8] [9] 两种。基于模型的RL方法利用经验数据估计系统模型参数,将参数估计值视为真实值进而通过解析表达式求解最优控制 [10] [11] ;无模型的RL方法直接与系统环境交互,利用经验数据直接学习最优控制而不估计参数 [12] [13] 。LQR问题的最优控制是状态的线性函数,在学习方法的框架下,相当于优化矩阵形式的参数。自然的想法是在参数空间中使用梯度下降算法,将控制参数化,即RL中的策略梯度算法。这种方法基于代价函数对控制参数的梯度,对参数进行优化。有模型的RL方法在模型结构已知时具有更好的表现,无模型方法则更少依赖于模型假设,具有更好的泛化性能 [14] 。
RL方法在实践中效果突出,但理论理解较少,相比之下,控制理论已经有较为成熟的研究成果,具有可证明的保证。系统参数已知时,控制优化过程中需要的梯度项有明确的表达式,易于计算;参数未知时,用经验数据对梯度项进行近似,现有的梯度近似有零阶近似、二阶近似以及样条逼近等方法。Dhruv Malik等人给出了零阶近似方法在线性控制问题中的收敛保证 [15] 。Maryam Fazel等人研究了初始状态有噪声干扰的情况下,不同梯度优化方的全局收敛性 [16] 。Ben Hambly等人在有限时域和随机状态转移的设置下为零阶近似方法提供了全局收敛保证 [17] 。Mesbahi A等人将结果推广至连续时间的LQR问题 [18] [19] 。
LQR问题描述
有限时域T下的随机离散时间LQR问题,系统方程为:
(1)
其中,
和
分别是系统在t时刻的状态向量和控制向量,
从分布
中随机抽样,
是独立同分布的零均值系统噪声序列,与
独立。
和
是系统转移矩阵。系统(1)对应的代价函数为:
(2)
其中,
是对称正定矩阵,
是正定矩阵,
是控制序列。
离散时间LQR问题的目标是在可行控制空间
中找到使代价函数值最小的最优控制,在系统参数已知时,有限时域的离散时间LQR问题的最优控制有显式解,当
可控时,根据最优控制理论 [20] ,t时刻的最优控制为当前状态的线性函数:
(3)
其中,
是t时刻的最优控制,
是以下代数黎卡提方程的解:
(4)
黎卡提方程的求解通常令
,通过递推式(6)进行迭代求解,直到满足精度要求。此时,代价函数达到最小值
.
上述通过求解代数黎卡提方程进而得到最优控制的方法有以下缺点:1) 并不直接优化控制增益
,也不直接优化代价函数;2) 在求解黎卡提方程时涉及高维矩阵的求逆运算,消耗的计算量在系统维度高时过大;3) 当系统参数
未知时,这种方法并不适用。
本文研究有限时域下的离散时间随机线性二次控制(DLQR)问题,在策略梯度方法中引入资格迹方法,不求解代数黎卡提方程,直接优化控制增益。资格迹方法是强化学习的基本方法之一,在优化中引入与控制参数向量同维度的资格迹向量,衡量系统控制参数每个分量的重要性,在学习过程中影响参数向量的更新 [3] 。这种方法不仅适用于分幕式的情况,也适用于持续性问题。在实际效果方面,资格迹方法比策略梯度算法更快收敛,且方差更小,数值模拟结果证明了这一结论。
2. 理论
本文考虑折现的随机DLQR问题:
(5)
其中
是折现因子,单步的代价
,
。控制增益遵循以下法则优化:
(6)
其中,
是迭代次数,
是步长参数,
是衰减参数,
是第n次迭代时的控制序列,
是与之对应的资格迹序列。
引理2.1 在策略参数的第n次迭代中,定义状态向量的协方差矩阵为:
,
(7)
则与
对应的资格迹由以下表达式给出:
(8)
其中,
。
证明:根据资格迹的定义,
(9)
随机DLQR问题(5)中,代价函数可拆分为初始状态项与噪声项:
(10)
上式对
求偏导,
(11)
其中,
证毕。
对衰减参数
的不同设置,是衡量历史信息对下一步决策的重要程度,当
时,不考虑历史信息,当
时,则认为历史信息与当前信息同样重要。资格迹方法考虑了当前的损失函数和历史策略梯度的关系,而梯度下降算法只考虑梯度更新的平滑度。资格迹方法能够减少参数更新过程中忽略影响较大的历史动量而造成的错误决策次数。
2.1. 参数已知的资格迹方法
本节讨论系统参数
完全已知时的资格迹方法 [3] 。资格迹方法结合了蒙特卡洛方法和时序差分方法。算法的核心是定义一个维度与策略参数相同的短时记忆向量
,衡量策略参数分量的重要性。随着迭代次数的增加,和参与更新的控制参数分量对应的资格迹分量逐渐衰减,直到这一分量再次参与更新。本文用资格迹代替参数更新中的梯度项,增强了算法的泛化性能。
在分析算法收敛性之前,首先研究不同控制序列下产生的代价函数的差异以及状态协方差矩阵间的差异上界,定义
为矩阵S的谱范数。
引理2.2 [17] 假设
与
产生的代价函数均有界,
,
,
,
分别是由
,
生成的序列,令
,则代价差可表示为:
(12)
其中,
是下述方程的解:
(13)
引理2.3 令
,
,
与
是任意策略,系统状态向量的协方差满足下面的关系:
(14)
证明详见附录。
上面的分析为收敛保证奠定了基础,证明算法的收敛性之前,引理2.4的论证了控制序列经过一次迭代后对代价函数值的影响。
引理2.4 设
是最优至序列,
由
经一次迭代得到,当
其中,
则
(15)
证明详见附录。
经过以上分析,下面给出参数已知时,资格迹算法在DLQR问题中的全局收敛性保证。
定理2.4 (收敛性定理)假设
有界,步长
满足引理2.4的约束,对
,当迭代次数N满足下述条件:
代价函数值收敛至最优值,即:
(16)
证明:令 ,根据引理2.4的结论,
,根据引理2.4的结论,
假设经
次迭代后,
,此时
,根据Cauchy-Schwarz不等式,
最后一个不等式成立基于下面的结果:
结合引理2.3的分析,引理2.3中的结论仍然成立,即:
(17)
将
次的结果进行累积,
对
,当
时,
。证毕。
2.2. 参数未知的资格迹方法
当系统参数θ未知时,式(13)中对梯度项的表达无效,在控制增益的更新中,性能指标的资格迹无法以解析式精确表达,只能对模型进行仿真得到训练数据。本文使用零阶优化方法 [6] 近似资格迹,无无需估计系统参数,直接利用目标函数的值优化控制增益。并且零阶优化方法对目标函数的凸性没有要求,直接用函数值估计函数梯度,这大大降低了算法的复杂度。本节首先分析零阶优化方法在随机最优化问题上的拓展 [11] [18] ,在DLQR问题中,参数未知时,在每一步的控制上加入随机噪声进行采样来估计代价函数值。目标函数可表示为
(18)
这里利用带噪声的代价函数值构造梯度的近似无偏估计。令
,设
是
上的均匀分布。任意给一个度量
,以及
与
独立,则零阶优化方法对
的梯度估计为:
(19)
随着r越来越小,近似值越来越精确 [11] ,但r过小可能导致估计值有较大的方差。表1给出了算法的框架。

Table 1. Eligibility track-gradient algorithm for DLQR problem
表1. DLQR的资格迹–梯度算法
引理2.5 对给定的
以及从
中随机抽取的随机向量
,I为采样幕数,
是折扣系数,资格迹的经验近似为:
(20)
其中,
引理2.6 假设任意不同控制
与
的分量满足:
(21)
则存在
,
使得,
,
证明详见附录。
引理2.7 对
,当
时,资格迹的经验近似满足:
,
证明详见附录。
定理2.8 (收敛性定理)假设
有界,步长
满足引理2.3的约束,对
,当迭代次数N满足
代价函数值收敛至最优值,即:
(22)
证明:令
,根据引理2.4,有
(23)
令
,当样本数足够多时,只要
时,
(24)
因为
首先讨论右式第一项,根据引理2.6,当
,若
成立,则有
因为
,所以只需证明
(25)
根据引理2.7,上式成立。综上所述
(26)
基于以上结论,与定理2.4相同的证明保证了收敛性。
3. 数值模拟
当状态维度d = 2时,设定系统参数为
折现因子
,比较资格迹方法与梯度下降算法的收敛情况。在折扣系数
的条件下,设定指数衰减的步长参数,分别令时域T = 20,迭代次数N = 40;时域T = 50,迭代次数N = 70,代价函数的收敛情况见见图1和图2:
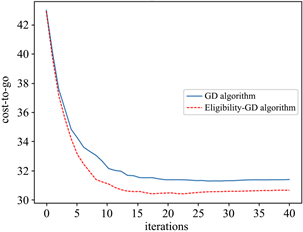
Figure 1. The convergence of C(K) when d = 2, T = 20
图1. d = 2,T = 20,代价函数的收敛情况
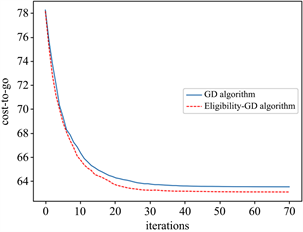
Figure 2. The convergence of C(K) when d = 2, T = 50
图2. d = 2,T = 50,代价函数的收敛情况
图1和图2的结果说明,资格迹算法比梯度下降算法具有更快的收敛速度。资格迹方法中折扣系数的取值对最终结果有显著影响,图3展示了T = 50,N = 70时不同的折扣系数对算法性能的影响:

Figure 3. The convergence of C(K) with different λ
图3. 不同λ,代价函数的收敛情况
在本节设定的系统参数下,图3的结果显示,折扣系数
时,资格迹算法表现优于策略梯度算法,当
后,结果出现不收敛的情况,随λ的增大,结果偏离越大。λ是过去梯度信息的权重,说明在这一数值范例中,过去梯度信息对问题求解只能提供少量信息。
当状态维度d = 4时,设定系统参数为
设定T = 50,N = 100,其余参数与二维系统相同,代价函数收敛情况如图4所示:

Figure 4. The convergence of C(K) when d = 4, T = 50
图4. d = 4,T = 50,代价函数的收敛情况
上述数值结果说明资格迹方法的收敛效果优于传统的资格梯度方法,并且在算法初期方差更小。
4. 结论
本文研究了无模型强化学习方法在有限时域离散LQR问题中的应用,不同于通过解代数黎卡提方程得到最优控制的方法,本文直接优化控制增益,在梯度下降算法的基础上引入资格迹方法,并给出在参数已知和参数未知两种情况下算法的收敛保证。在初始代价函数有界的条件下,算法可以扩展至无限时域。数值模拟验证了算法的收敛性,展示了不同参数设置对结果的影响。另一个方向是基于有模型的强化学习方法,在更少样本量的基础上,进一步达到更好的收敛结果。
致谢
感谢张老师在论文写作过程中给出的指导和建议。
文章引用
朱亚楠. 随机线性二次控制的资格迹方法
Eligibility Trace Method for Stochastic Linear Quadratic Control[J]. 理论数学, 2024, 14(01): 416-432. https://doi.org/10.12677/PM.2024.141041
参考文献
- 1. Birge, J. and Louveaux, F. (2011) Introduction to Stochastic Programming. Springer Science & Business Media, Heidelberg. https://doi.org/10.1007/978-1-4614-0237-4
- 2. Kučera, V. (1992) Optimal Control: Linear Quadratic Methods: Brian D. O. Anderson and John B. Moore. Automatica, 28, 1068-1069. https://doi.org/10.1016/0005-1098(92)90166-D
- 3. Sutton, R.S. and Barto, A.G. (2018) Reinforcement Learning: An Introduction. 2nd ed., the MIT Press, Cambridge.
- 4. Basei, M., Guo, X., Hu, A. and Zhang, Y. (2020) Logarithmic Regret for Episodic Continuous-Time Linear-Quadratic Reinforcement Learning over a Finite-Time Horizon. Computation Theory eJournal. https://doi.org/10.2139/ssrn.3848428
- 5. Dean, S., Mania, H., Matni, N., Recht, B. and Tu, S. (2017) On the Sample Com-plexity of the Linear Quadratic Regulator. Foundations of Computational Mathematics, 20, 633-679. https://doi.org/10.1007/s10208-019-09426-y
- 6. Ren, Z., Zhong, A. and Li, N. (2021) LQR with Tracking: A Zeroth-Order Approach and Its Global Convergence. 2021 American Control Conference (ACC), New Orleans, LA, 25-28 May 2021, 2562-2568. https://doi.org/10.23919/ACC50511.2021.9483417
- 7. Bertsekas, D.P. (2011) Approximate Policy Iteration: A Survey and Some New Methods. Journal of Control Theory and Applications, 9, 310-335. https://doi.org/10.1007/s11768-011-1005-3
- 8. Mania, H., Guy, A. and Recht, B. (2018) Simple Random Search Provides a Competitive Approach to Reinforcement Learning. arXiv preprint arXiv:1803.07055
- 9. Abbasi-Yadkori, Y., Lazic, N. and Szepesvari, C. (2019) Model-Free Linear Quadratic Control via Reduction to Expert Prediction. The 22nd International Conference on Artificial Intelligence and Statistics, Naha, 16-18 April 2019, 3108-3117.
- 10. Mahdi, I. and Braga-Neto, U.M. (2018) Finite-Horizon lqr Controller for Partially-Observed Boolean Dynamical Systems. Automatica, 95, 172-179. https://doi.org/10.1016/j.automatica.2018.05.028
- 11. Zhang, H. and Li, N. (2022) Data-Driven Policy Iteration Algorithm for Continuous-Time Stochastic Linear-Quadratic Optimal Control Problems. Asian Journal of Control, 26, 481-489. https://doi.org/10.1002/asjc.3223
- 12. Farjadnasab, M. and Babazadeh, M. (2022) Model-Free LQR Design by Q-Function Learning. Automatica, 137, Article ID: 110060. https://doi.org/10.1016/j.automatica.2021.110060
- 13. Yaghmaie, F.A., Gustafsson, F.K. and Ljung, L. (2023) Linear Quadratic Control Using Model-Free Reinforcement Learning. IEEE Transactions on Automatic Control, 68, 737-752. https://doi.org/10.1109/TAC.2022.3145632
- 14. Tu, S. and Recht, B. (2019) The Gap between Model-Based and Model-Free Methods on the Linear Quadratic Regulator: An Asymptotic Viewpoint. Conference on Learning Theory, USA, 9 December 2019, 3036-3083.
- 15. Malik, D., Pananjady, A., Bhatia, K., Khamaru, K., Bartlett, P.L. and Wainwright, M.J. (2018) Derivative-Free Methods for Policy Optimization: Guarantees for Linear Quadratic Systems. Journal of Machine Learning Research, 21, 1-21.
- 16. Fazel, M., Ge, R. Kakade, S.M. and Mesbahi, M. (2018) Global Convergence of Policy Gradient Methods for the Linear Quadratic Regulator. International Conference on Machine Learning, Stockholm, 10-15 July 2018, 1467-1476.
- 17. Hambly, B.M., Xu, R. and Yang, H. (2021) Policy Gradient Methods for the Noisy Linear Quadratic Regulator over a Finite Horizon. SIAM Journal on Control and Optimization, 59, 3359-3391. https://doi.org/10.1137/20M1382386
- 18. Shamir, O. (2017) An Optimal Algorithm for Bandit and Zero-Order Convex Optimization with Two-Point Feedback. The Journal of Machine Learning Research, 18, 1703-1713.
- 19. Bu, J., Mesbahi, A. and Mesbahi, M. (2020) Policy Gradient-Based Algorithms for Continuous-Time Linear Quadratic Control. arXiv: 2006.09178.
- 20. Bertsekas, D.P. (1995) Dynamic Programming and Optimal Control. 3rd Edition, Athena Scientific, Nashua, NH.
附录
引理2.3证明:
在对
进行分析前,定义以下线性算子以方便证明。令
,
同理可得,
综上所述,
引理2.6证明:
令
首先看右边第一项,
根据引理2.3证明中的定义,

第二项,

第三项,

其中,
根据假设
,倒数第二个不等式成立,综上所述,
下面证明梯度项,
引理2.7证明过程
定义
则
因为
,根据霍夫丁不等式,对
,
因为
所以,
。
又
,
所以,
,
根据引理2.9,当
时,
所以,
综上所述,
。根据资格迹与梯度的关系,
因为
,由
的任意性可知结论成立。






 ,根据引理2.4的结论,
,根据引理2.4的结论,





