Modeling and Simulation
Vol.
12
No.
02
(
2023
), Article ID:
62545
,
14
pages
10.12677/MOS.2023.122101
玻璃文物化学成分体系的统计分析
周冒伟,黄佳怡,孙雪婷,刘芳
南京理工大学,数学与统计学院,江苏 南京
收稿日期:2023年2月4日;录用日期:2023年3月9日;发布日期:2023年3月16日

摘要
玻璃的起源历史悠久,作为中西方早期贸易、文化交流的宝贵物证之一,玻璃极大地丰富了人类的物质文化。分析玻璃文物类型和化学成分之间的关系,对玻璃制作工艺、来源等的研究具有非常重要的科学指导意义。本文对我国古代玻璃的化学成分进行了研究,首先使用线性回归分析和相关性分析确立了玻璃文物表面的风化化学成分,得到玻璃文物表面风化与类型的关系;然后使用K-means算法对玻璃文物进行亚类划分;最后综合均值法和偏最小二乘回归模型预测玻璃文物风化前化学成分含量,并基于决策树法鉴别未知玻璃文物所属的类型。本文对于古代玻璃文物的成分分析与类别鉴定具有一定的指导价值。
关键词
玻璃文物,成分体系,聚类分析,决策树法,热力图

Statistical Analysis of the Chemical Composition System of Ancient Glass
Maowei Zhou, Jiayi Huang, Xueting Sun, Fang Liu
School of Mathematics and Statistics, Nanjing University of Science and Technology, Nanjing Jiangsu
Received: Feb. 4th, 2023; accepted: Mar. 9th, 2023; published: Mar. 16th, 2023

ABSTRACT
Glass has a long history of origin. As one of the precious material evidence of the early trade and cultural exchanges between China and the West, glass has greatly enriched the material culture of human beings. The analysis of the relationship between the type and chemical composition of glass cultural relics is of great scientific guiding significance to the research of glass production technology and source. This paper studies the ancient Chinese glass. Firstly, we use the linear regression analysis and the correlation analysis to establish the weathering chemical composition of the glass artifact surface and obtain the relationship between surface weathering and type of glass cultural relics. Then, we use the K-means algorithm to subclassify the glass artifacts. Finally, we combine the mean method and partial least squares regression model to predict the pre-weathering chemical content of glass relics, and identify the type of unknown glass relics based on the decision tree method. This paper has certain guiding value for the composition analysis and category identification of ancient glass cultural relics.
Keywords:Glass Relics, Composition System, Cluster Analysis, Decision-Making Tree, Heat Map

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
古代玻璃的起源历史悠久,作为中西方早期贸易、文化交流的宝贵物证之一,玻璃极大地丰富了人类的物质文化,同时,大量的古代玻璃制品存留至今。玻璃的主要原料是石英砂,化学成分为二氧化硅。纯石英砂的熔点较高,为了降低熔化温度,需要添加助熔剂。根据所添加助熔剂的不同,可以将我国早期的玻璃体系大致分为铅钡玻璃和高钾玻璃,又可以根据文物表面有无风化,继续划分为有风化铅钡玻璃、无风化铅钡玻璃、有风化高钾玻璃和无风化高钾玻璃。分析玻璃文物类型和化学成分之间的关系,对玻璃制作工艺、来源等的研究具有非常重要的科学指导意义,同时有利于为古代中西方物质文化交流提供科学依据。
公元前4000年,美索不达米亚和埃及地区就开始生产玻璃的雏形——费昂斯 [1] ,中国古代的玻璃体系较之晚了近2000年,玻璃制品在本土地区经历了从舶来品到自主生产的过程,但无论美索不达米亚、埃及还是中国,早期的玻璃制品皆以珠饰为主 [2] 。因此探究我国古代玻璃文物的化学成分体系和种类划分,是研究玻璃技术发展、来源的必经之路,在此基础上深入分析,也有利于探讨古代中西方之间的文化演进、贸易交流、人群迁徙等。
化学成分分析是研究古代玻璃制品成分体系不可或缺的重要一环。国内外对古代玻璃文物制品的研究,主要是围绕玻璃发展史和化学技术层面对玻璃文物进行化学成分检测展开的 [3] 。而对于数学统计层面,预测玻璃文物风化前后的类型和化学成分的文献较少。因此本文希望能够建立合适的数学模型,对玻璃文物风化前后的类型和化学成分进行预测。
我国出土的玻璃文物众多,对古代玻璃的发展史和化学成分检测的研究一直是重点问题。沈从文结合史料记载和对出土文物的考察提出“中国古代玻璃制作技术从颗粒装饰品逐渐转化成小件玻璃制品,至晚在战国晚期完成” [4] 。安佳瑶对玻璃的整体发展史进行概述,将中国古代玻璃进行阶段性分析 [1] 。干福熹带领团队从化学技术的层面对玻璃文物进行了大量检测技术的研究,主要采用PIXE和EDXRF的方法,证明了古代最早的高钾玻璃和铅钡玻璃产自中国,提出了中国玻璃“自创说”理论 [5] [6] [7] [8] [9] 。成倩等人利用微损的激光剥离技术对文物进行化学成分检测,对文物的损害很小 [10] 。随着科技的不断发展,化学成分分析向着快速、准确、无损的方向发展。
为了在数学统计层面建立更精准的模型对玻璃文物进行化学成分分析和类型鉴别,本文对高教社杯数学建模C题中提供的实验数据进行建模,使用SPSS、Python,通过回归分析、相关性分析、K-means算法和决策树等,确立了玻璃文物表面的风化化学成分,得到玻璃文物表面风化与类型的关系,预测风化前的化学成分含量;同时对高钾、铅钡玻璃进行亚类划分,进而鉴别未知玻璃文物所属的类型。
2. 成分体系
本章给出我国古代玻璃文物风化与化学成分之间的相关性分析,并对高钾、铅钡玻璃进行亚类划分。
我们收集到一批古代玻璃文物的相关数据在表单2中,进行数据预处理:1) 表单中空白处表示未检测到该化学成分,将其用0填充;2) 将成分比例累加之和不在85%~105%的数据删除;3) 将表单剔除异常值后的化学成分数据进行归一化处理,使其累加和为100%;4) 将“文物采样点”分开成“文物编号”和“采样点”,并对表单1和2进行合并。部分结果见如下图1:
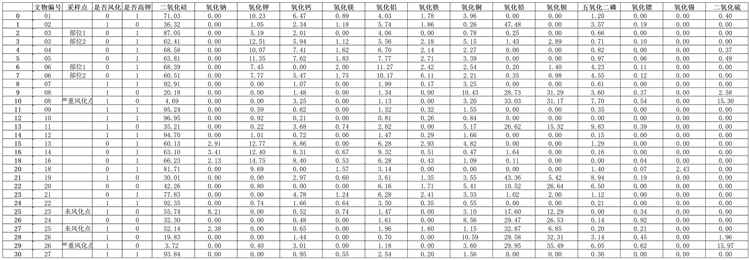
Figure 1. Part of the preprocessed experimental data
图1. 部分预处理后的实验数据
2.1. 相关性分析
要分析玻璃表面有无风化化学成分,采用多元线性回归分析与相关性分析相结合的方式。根据处理后的数据,以14个化学成分作为输入,是否风化作为输出,建立多元线性回归模型,计算14个指标的权重,规定大于某一阈值的为风化化学成分;同时进行相关性分析,验证我们所得结果的合理性。
2.1.1. 确定回归系数
令输入变量 分别表示十四种化学成分的百分含量,输出变量y表示是否风化。y = 1表示风化;y = 0表示没有风化。
建立多元线性回归分析模型:
其中, (m = 14)都是与 无关的未知参数, 称为回归系数。
得到独立观测数据:
其中, 为y的观察值, 分别为 的观察值,i = 1~n (n > m)。
记
可得
其中, 为n阶单位矩阵(n为数据的样本数)。
利用Python,将处理后的数据代入模型,进行模型的求解。根据以上模型建立过程,我们得到这14个化学成分对风化程度的权重及影响见如下表1:

Table 1. Regression coefficients of the multiple linear regression model
表1. 多元线性回归模型的回归系数
由表1,设置阈值为0.1,取绝对值大于0.1的化学元素即氧化钾(K2O),氧化钙(CaO),氧化铁(Fe2O3),氧化铅(PbO),五氧化二磷(P2O5),氧化锡(SnO2),并认为这些化学成分对风化程度的影响相对较大,其余可以近似忽略。
2.1.2. 基于Pearson相关系数的风化相关性热力图
在实际情况下,化学成分对风化程度的影响很难是完全线性的,且各成分之间必然存在互相影响的情况,因此我们在多元线性回归分析的基础上,进行了相关性分析来更全面地分析化学成分对风化程度的影响。
假设有两组数据 和 (n = 15)。X和Y代表是否风化和14种化学成分。当表面风化时取1,没有发生风化时取0。
样本均值为:
样本协方差:
样本Pearson相关系数 [11] :
其中, , 为样本标准差,公式如下:
采用SPSS绘制出各化学成分的Pearson相关系数,见如下图2:
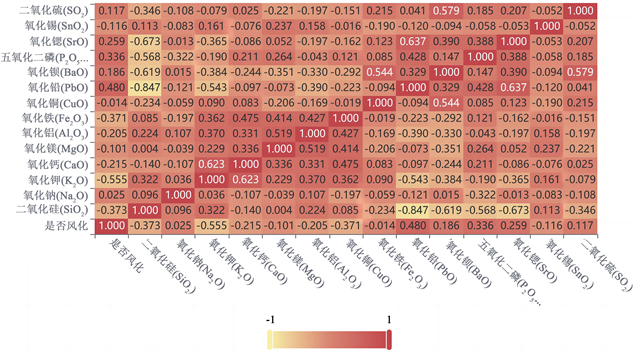
Figure 2. Heat map of chemical composition and weathering correlation
图2. 化学成分与风化相关性热力图
由图2,我们取阈值为0.2,满足风化系数大于0.2的有8种化学成分,结果见如下表2:
Table 2. Pearson Chemical composition with a correlation coefficient greater than 0.2
表2. Pearson相关系数大于0.2的化学成分
2.1.3. 总结
综合考虑,取两种的交集作为对风化程度有较大影响的化学成分:氧化钾(K2O),氧化钙(CaO),氧化铁(Fe2O3),氧化铅(PbO),五氧化二磷(P2O5)。
最后,我们对五个风化化学成分和“类型是否为高钾玻璃”作风化相关性热力图,结果见如下图3:
由图3,可以发现:
1) 高钾玻璃风化程度与氧化钾、氧化钙、氧化铁含量关系成正相关,而铅钡玻璃的风化程度与氧化铅,五氧化二磷关系成正相关。
2) 在风化情况下,玻璃文物是高钾玻璃还是铅钡玻璃与氧化钾和氧化铅的含量有关。
3) 髙钾玻璃是否风化与氧化钾的占比含量相关性较强;铅钡玻璃是否风化与氧化铅的占比含量相关性较强。
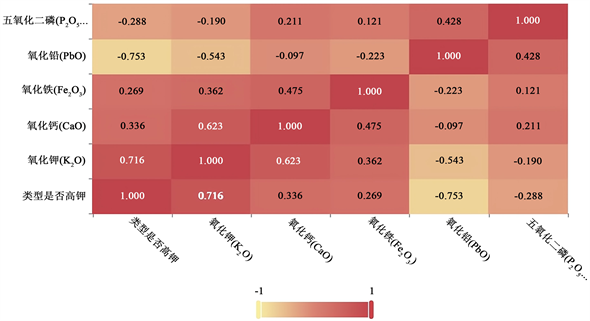
Figure 3. Heat map of weathering chemical composition correlation
图3. 风化化学成分相关性热力图
2.2. 亚类划分
2.2.1. 确定分类中心
为了对高钾玻璃和铅钡玻璃进行更加细类的划分,我们可以采用聚类分析法。聚类分析是一种无监督学习,用于对未知类别的样本进行划分将它们按照一定的规则划分成若干个类簇,把相似(相关的)的样本聚在同一个类簇中,把不相似的样本分为不同类簇,从而分析样本之间内在的性质以及相互之间的联系规律。
K-means算法是基于划分的聚类算法,计算样本点与簇质心的距离,与簇质心相近的样本点划分为同一类簇。两个样本距离越远,则相似度越低。
基本流程:
1) 设定k值,表示需要将数据分成k个簇,从样本点中随机选择k个点作为初始簇中心。
2) 分别计算每个样本点到各个初始簇中心的距离,将每个样本点划分到距离它最近的中心点。
3) 用各簇中所有样本的质心(即为均值,向量的各个维度分别取平均)代替原有的中心点。
4) 重复步骤2和3,直到中心点不变或达到预定迭代次数时,算法终止。
迭代计算就是一个优化目标的过程,这是机器学习算法必不可少的一步,这里优化的是各个数据点到中心点的距离,距离越小越好。
根据预处理后的数据,利用python,我们可以得到高钾和铅钡玻璃分类的中心见如下表3:
Table 3. High potassium glass and lead barium glass classification center
表3. 高钾玻璃和铅钡玻璃分类的中心
由表3确定的类中心,利用实验数据验证,对比结果发现,67组数据中心正确判断了58组数据,正确率达86.6%。故根据上表和化学成分的占比含量,可以对高钾玻璃和铅钡玻璃进行较为准确的分类。
2.2.2. 对高钾、铅钡玻璃进行亚类划分
在2.2.1的基础上,我们先设定k = 3,使用python运行程序,得到玻璃亚类中心见如下表4、表5:
Table 4. High-potassium glass subclass center table
表4. 高钾玻璃亚类中心表
Table 5. Lead barium glass subclass center table
表5. 铅钡玻璃亚类中心表
2.2.3. 合理性和敏感性分析
我们可以采用计算误差平方和SSE、轮廓系数、CH指标来评估聚类分析的好坏,本文采用轮廓系数。
公式如下:
其中, 表示化学成分的内聚度,计算公式如下:
其中j表示与样本i在同一亚类内的其他样本点,distance表示i与j的距离。 越小说明该类越紧密。 计算公式与 相类似。
当 时,类内距离小于类间距离,聚类更紧凑,S的值趋近于1。轮廓系数S的取值范围为[−1, 1],轮廓系数越大,聚类效果越好 [12] 。
我们分别令k = 1,2,3,4,5,计算得到了各个情形下的轮廓系数,见如下图4:

Figure 4. Plot of the contour coefficient versus k
图4. 轮廓系数与k的关系图
由图4可知:
1) 髙钾玻璃的聚类效果要始终优于铅钡玻璃,分类结果更加合理;
2) 当k < 3时,轮廓系数随着k的增大而明显增大,当k > 3时,增大速度放缓且趋近于一定值,K-means聚类分析效果变化不大,分类结果已经较为良好,故k取3具有一定的合理性;
3) K-means聚类分析模型对k的取值的敏感度较大,故选择一个合适的k对聚类分析十分重要。
保持k = 3,改变化学成分个数,分析对聚类效果的影响。化学成分分别取14种,8种(二氧化硅,氧化钾,氧化钙,氧化铝,氧化铁,氧化铅,五氧化二磷,氧化锶),5种(氧化钾,氧化钙,氧化铁,氧化铅,五氧化二磷),结果见如下图5:
由图5可知:
1) 化学成分个数越多,聚类效果越好。
2) 利用第一问求得的与风化相关性较强的化学成分,基本能够对高钾玻璃和铅钡玻璃进行分类。
3) 三种情况下,高钾玻璃的聚类效果都要优于铅钡玻璃。
4) 轮廓系数随化学成分个数的变化幅度较大,故聚类分析对化学成分个数的敏感度较大。
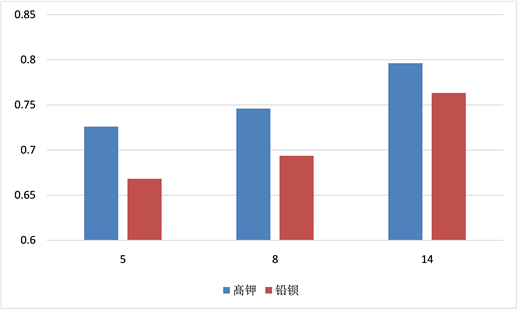
Figure 5. Diagaph of contour coefficient and number of chemical compositions
图5. 轮廓系数与化学成分个数的关系图
3. 模型建立
本章综合均值法和偏最小二乘回归模型预测玻璃文物风化前化学成分含量,并基于决策树法鉴别未知玻璃文物所属的类型。
3.1. 预测玻璃文物风化前化学成分含量
3.1.1. 均值法预测风化前化学成分含量
设不同类型的玻璃文物风化前的化学成分为 ,具体表示第i次校验的第j个化学成分。
那么,
其中,m表示m种化学成分。
同理,设不同类型的玻璃文物风化后的化学成分为 ,具体表示第 次校验的第 个化学成分。
那么,
易得知,风化过程的各化学成分的变化率
根据以上公式对实验数据进行处理,分别得到高钾玻璃和铅钡玻璃风化前后各个化学成分的均值以及变化率,结果见如下表6。
由表6我们对给定风化后数据的部分进行还原,使用公式
即可得到不同类型的玻璃文物风化前的化学成分含量。
Table 6. Mean value and rate of change of each chemical composition before and after weathering
表6. 风化前后各化学成分的均值及变化率
3.1.2. 偏最小二乘回归分析模型预测风化前化学成分含量
本文我们建立偏最小二乘回归分析模型预测风化前化学成分含量 [13] :
设风化后14种化学成分含量为 ,风化前14种化学成分含量为 。自变量的观测数据矩阵记为 ,因变量的观测数据矩阵记为 。n为训练集的样本个数。
1) 数据标准化。将各指标值 转化为标准化指标值 ,有
其中: ; ,即 , 为第j个自变量 的样本均值和样本标准差。
对应地,称
为标准化指标变量。
类似的,将 转化为标准化指标值 ,有
其中 ; ,即 , 为第j个因变量 的样本均值和样本标准差。
对应地,称
为标准化指标变量。
利用corrcoef函数求得28个变量之间的相关系数矩阵。进而分别提出标准化后自变量组 和因变量组 的数据。
求两个成分对时标准化指标变量与成分变量之间的回归方程。求得自变量组 与因变量组 之间的回归方程。最后将标准化变量 、 (j = 1, 2)分别还原为原始变量 、 ,得到回归方程。
3.1.3. 模型的求解
根据求得的风化前后各化学成分的均值及变化率,可以分析得到高钾、铅钡玻璃的分类规律有如下几点:
1) 对于高钾玻璃,风化后只有二氧化硅的含量大幅上升,其他化学成分含量都显著降低,大部分化学成分含量可以忽略不计。
2) 对于铅钡玻璃,风化后氧化钠、氧化钙、氧化镁、氧化铝、氧化铜、氧化铅、五氧化二磷、氧化锶、二氧化硫占比含量变多,其余变低。
通过Matlab,求得偏最小二乘回归分析部分回归系数直方图,见如下图6、图7:
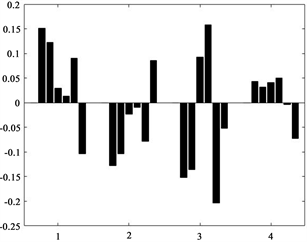
Figure 6. Histogram of partial least squares regression
图6. 偏最小二乘回归部分回归系数直方图

Figure 7. Fitting results of the regression equation
图7. 回归方程的拟合结果
由图6、图7可知,利用得到的回归方程去检验均值法预测出来的风化前化学成分含量的结果,拟合优度R2 = 0.8143,拟合效果较高,说明均值法所得结果较为合理。能够根据风化点的检测数据,预测风化前14种化学成分的含量。
3.2. 鉴别未知玻璃文物所属类型
3.2.1. 决策树法鉴别未知玻璃文物的类型
决策树是通过对训练样本进行归纳学习生成决策树或决策规则,然后使用决策树或决策规则对新数据进行分类的一种数学方法。决策树是一个树型结构,它由一个根结点、一系列内部结点及叶结点组成,每一结点只有一个父结点和两个或多个子结点,结点间通过分支相连。决策树的每个内部结点对应一个非类别属性或属性的集合(也称为测试属性),每条边对应该属性的每个可能值。决策树的叶结点对应一个类别属性值,不同的叶结点可以对应相同的类别属性值 [14] 。
决策树的生成通常采用自顶向下的递归方式,在构造过程中,采用信息增益度量。信息增益最大表明了数据集中在分类过程中能够最大化减少不确定性,因此具有更好的分类效果。信息熵(H)以及信息增益(G)可定义如下:
其中p表示随机变量的概率,A表示特征,D表示数据集, 表示经验熵, 表示条件熵, 表示特征A在数据集D的条件下的经验条件熵。
3.2.2. 模型求解
利用SPSS,将预处理后的数据,以化学成分和玻璃文物表面是否风化作为输入,类型作为模型的输出,训练决策树模型。最后将实验数据附件表单3 [15] 中未知玻璃类别的化学成分和表面风化作为输入,预测最终结果见如下表7:
Table 7. Identification results of glass relics by decision tree method
表7. 决策树法对玻璃文物的鉴别结果
3.2.3. 准确性和灵敏性分析
利用SPSS,分别训练逻辑回归、向量机、随机森林模型,并与决策树法所预测结果相比较。结果见如下表8:
Table 8. Identification results of glass artifacts by the four models
表8. 四种模型对玻璃文物的鉴别结果
由图可知,四种模型对实验数据附件表单3 [15] 中未知玻璃文物所属类型的鉴别结果完全一致。
在前面求得高钾玻璃和铅钡玻璃类中心的基础上,求未知玻璃的化学成分与类中心的欧氏距离,比较他们匹配程度的差异性,进而进行灵敏度分析。
设玻璃文物的化学成分为 ,高钾玻璃化学成分的类中心为 ,铅钡玻璃化学成分的类中心为 。
则要求欧式距离之和尽量的小,即
。
代入Matlab计算结果见如下表9:
Table 9. Sensitivity analysis of the classification results
表9. 分类结果的灵敏度分析
由表9可知:
1) 欧氏距离分析得到的结果与逻辑回归、决策树、向量机、随机森林相一致。
2) 鉴别未知玻璃文物属性对二氧化硅、氧化钾、氧化铅的敏感性较大,对其他化学成分的敏感性较小。
4. 结论
本文对所给的实验数据进行数据预处理,分析并建立数学模型,研究了玻璃文物表面有无风化化学成分含量的统计规律和不同类别玻璃文物样品化学成分之间的关联关系,并根据风化点检测数据预测玻璃文物风化前的化学成分含量,鉴别给定的玻璃文物的类别。
首先,我们将多元线性回归分析和相关性分析相结合,探讨了玻璃文物化学成分和表面风化之间的统计关系,发现对风化程度有较大影响的化学成分有五种:氧化钾(K2O),氧化钙(CaO),氧化铁(Fe2O3),氧化铅(PbO),五氧化二磷(P2O5)。
然后,基于玻璃文物风化与化学成分存在相关性的结论,采用K-means聚类分析算法确定类中心,并对高钾玻璃和铅钡玻璃进行更加细致的亚类划分。
最后,基于不同类别玻璃文物样品化学成分之间的关联关系,将均值法和偏最小二乘回归分析模型相结合,建立了玻璃文物化学成分预测模型,根据风化点的检测数据,预测了风化前14种化学成分的含量。并基于决策树法建立了玻璃类型鉴别模型,利用欧式距离分析发现,所建立的鉴别模型准确率较高。本文对于古代玻璃文物的成分分析与类别鉴定具有一定的指导价值。
文章引用
周冒伟,黄佳怡,孙雪婷,刘 芳. 玻璃文物化学成分体系的统计分析
Statistical Analysis of the Chemical Composition System of Ancient Glass[J]. 建模与仿真, 2023, 12(02): 1069-1082. https://doi.org/10.12677/MOS.2023.122101
参考文献
- 1. 安佳瑶. 玻璃史话[M]. 北京: 社会科学文献出版社, 2011: 7-11.
- 2. 赵志强. 新疆巴里坤石人子沟遗址群出土玻璃珠的成分体系与制作工艺研究[D]: [硕士学位论文]. 西安: 西北大学, 2016.
- 3. 刘淑娜. 中国古代北方游牧民族玻璃器研究[D]: [硕士学位论文]. 呼和浩特: 内蒙古师范大学, 2022.
- 4. 沈从文. 玻璃史话[M]. 沈阳: 万卷出版公司, 2005: 1-5.
- 5. 干福熹. 中国古代玻璃技术的发展[M]. 上海: 上海科学技术出版社, 2005.
- 6. 干福熹. 中国古代玻璃的起源和发展[J]. 自然杂志, 2006(4): 192.
- 7. 干福熹, 赵虹霞, 李青会, 李玲, 承焕生. 湖北省出土战国玻璃制品的科技分析与研究[J]. 江汉考古, 2010(2): 108-116.
- 8. 干福熹, 黄振发, 肖炳荣. 我国古代玻璃的起源问题[J]. 硅酸盐学报, 1978(Z1): 99-104.
- 9. 干福熹, 承焕生, 李青会. 中国古代玻璃的起源——中国最早的古代玻璃研究[J]. 中国科学(E辑: 技术科学), 2007(3): 382-391.
- 10. 成倩, 王博, 郭金龙, 崔剑锋. 丝绸之路且末古国墓地出土玻璃器成分特点研究[J]. 玻璃与搪瓷, 2012, 40(2): 21-29.
- 11. 张宇镭, 党琰, 贺平安. 利用Pearson相关系数定量分析生物亲缘关系[J]. 计算机工程与应用, 2005(33): 83-86.
- 12. 朱连江, 马炳先, 赵学泉. 基于轮廓系数的聚类有效性分析[J]. 计算机应用, 2010, 30(S2): 139-141.
- 13. 司守奎, 孙玺菁. 数学建模算法与应用[M]. 第3版. 北京: 国防工业出版社, 2021: 358-364.
- 14. 夏慧维. 基于决策树集成和宽度森林的网络流量分析与预测研究[D]: [硕士学位论文]. 南京: 南京邮电大学, 2020.
- 15. 中国工业与应用数学学会. 2022高教社杯全国大学生数学建模竞赛赛题[EB/OL]. http://www.mcm.edu.cn/html_cn/node/5267fe3e6a512bec793d71f2b2061497.html, 2022-09-15.