Statistics and Application
Vol.05 No.04(2016), Article ID:19251,9
pages
10.12677/SA.2016.54037
Bayes AR(p) Analysis of Container Throughput Based on the Gibbs Sampling
Shanwei Zhu
School of Economics & Management, Shanghai Maritime University, Shanghai

Received: Nov. 26th, 2016; accepted: Dec. 9th, 2016; published: Dec. 15th, 2016
Copyright © 2016 by author and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
AR(p) model is widely used for time series forecasts; however, it’s difficult for traditional static model to deal with emergencies, which lead to estimation bias. In view of the influences of emergencies for model estimation, we carry out Bayesian analysis of the model by aid of the Gibbs sampling. According to likelihood function’s statistical structure of the time series samples, the prior distribution is obtained. After getting the posterior empirical distribution of parameters, the specific sampling strategy is proposed. Under the minimum mean square error estimation criterion, the simulation experiments show that the estimates are close to the true value. The analysis for the data of Shanghai port’s container throughput from 1982 to 2015 indicates that by aid of the Bayesian analysis, the estimation bias from emergencies can be overcome so that the model prediction is more accurate.
Keywords:AR(p) Model, Bayes Analysis, Gibbs Sampling, Throughout Capacity

基于Gibbs抽样的集装箱吞吐量 Bayes AR(p)分析
朱善维
上海海事大学经济管理学院,上海

收稿日期:2016年11月26日;录用日期:2016年12月9日;发布日期:2016年12月15日

摘 要
AR(p)模型广泛应用于时序预测,然而传统静态模型难以处理突发事件以致模型估计偏差。鉴于突发事件对模型估计的影响,采用Gibbs抽样方法对模型进行Bayes分析,根据时序样本似然函数的统计结构构造出模型各参数的先验分布。在导出模型参数后验条件分布后给出具体抽样策略。在最小均方误差估计准则下对中小样本的模拟显示,参数估计值与真值接近。对上海港1982~2015年集装箱吞吐量数据的分析表明:借助Bayes分析,可以克服由于突发事件导致的模型估计偏差,使模型预测更加准确。
关键词 :AR模型,Bayes分析,Gibbs抽样,吞吐量

1. 引言
世界经济的发展与港口业休戚相关,世界各主要港口间的竞争如今正逐步转向以集装箱吞吐量为核心的港口综合能力的竞争。可见,对港口集装箱吞吐量的预测不可或缺,其在制定港口发展方向,经营策略,投资规模,泊位选址上都发挥着重要作用。
对于集装箱吞吐量的预测,田歆等 [1] 基于TEI@I方法,提出香港集装箱吞吐量预测研究框架,利用季节ARIMA及VAR等计量模型,不规则时间的量化方法以及径向基神经网络技术,建立了集装箱吞吐量的综合集成预测模型。杨金花等 [2] 基于灰色预测模型GM(1,1)预测了上海港样本期外3年的集装箱吞吐量。余思勤等 [3] 采用带外生变量的非线性自回归神经网络模型对上海港集装箱吞吐量进行预测,发现训练后的网络误差较小,预测效果较好。已有预测模型多是传统静态模型,面对诸如2009年美国金融危机,全球贸易不景气,港口集装箱吞吐量锐减之类的突发事件就会导致模型预测偏差。鉴于此,本文提出Bayes AR(p)模型,运用Bayes方法对时间序列进行预测分析,此不仅利用了模型信息和样本信息,也结合了模型中总体分布的未知参数信息。这样就能处理传统静态模型难以克服的缺陷,易于适应外部变化。
运用Bayes方法对时间序列模型进行分析时会遇到对高维概率分布积分的问题。Gibbs抽样是解决高维积分的迭代Monte Carlo方法,解决了复杂表达式难以高维积分的问题,应用十分广泛。本文利用Bayes方法对AR(p)模型进行分析,得到模型参数后验条件分布后,给出Gibbs抽样的具体策略。通过Gibbs抽样得到一系列模拟值构成Markov链,且链的平稳分布收敛于待估参数的后验条件分布,即可以将模拟值看作后验分布的独立样本对参数估计值进行推断。
2. 模型建立
对于随机变量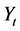 ,其满足的AR(p)模型为
,其满足的AR(p)模型为
 (1)
(1)
其中,误差项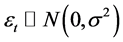 ,且
,且 相互独立;
相互独立;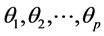 为模型的自回归系数;
为模型的自回归系数;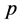 为模型的阶数;记
为模型的阶数;记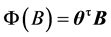 ,其中,
,其中, ,
,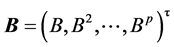 ,
,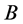 为延迟算子。则(1)式可记为
为延迟算子。则(1)式可记为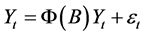 。若AR(p)模型是平稳的,则必多项式
。若AR(p)模型是平稳的,则必多项式 的根在单位圆之内。本文假定所分析的AR(p)模型均是平稳过程。对于未处理的时间序列数据,通过单位根检验来判定是否平稳,对非平稳的时间序列可通过差分化为平稳时间序列。
的根在单位圆之内。本文假定所分析的AR(p)模型均是平稳过程。对于未处理的时间序列数据,通过单位根检验来判定是否平稳,对非平稳的时间序列可通过差分化为平稳时间序列。
若已知 对于给定时间序列
对于给定时间序列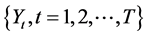 ,则
,则

记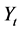 的条件概率密度为
的条件概率密度为 。对初始值
。对初始值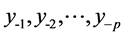 ,样本
,样本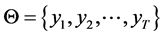 的条件似然函数为
的条件似然函数为
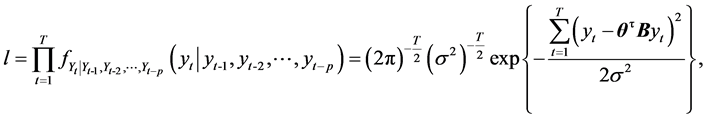 (2)
(2)
其对数似然函数为
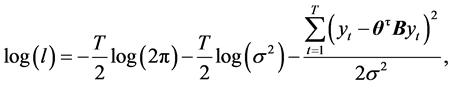
在进行Bayes分析时,由于参数的先验信息比较难确定,而不当先验信息会对估计结果产生错误影响。根据似然函数(2)式的结构,自回归系数 的先验分布选为无信息先验,记
的先验分布选为无信息先验,记 ,误差项
,误差项 的方差
的方差 的先验分布选为倒Gamma分布(参见文 [4] )。其为
的先验分布选为倒Gamma分布(参见文 [4] )。其为 的共轭先验分布。记
的共轭先验分布。记
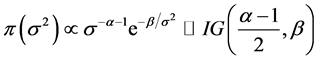
其中 是先验分布参数。根据Bayes公式可知,参数
是先验分布参数。根据Bayes公式可知,参数 和
和 的后验条件分布为
的后验条件分布为
 (3)
(3)
为了避免对参数的高维概率密度函数作积分的复杂问题,我们利用马尔科夫链蒙特卡罗(Markov Chain Monte Carlo, MCMC)算法。
MCMC的基本思想是:对于给定样本集 ,为得到参数向量
,为得到参数向量 的后验分布
的后验分布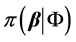 的样本,建立一个平稳分布为
的样本,建立一个平稳分布为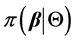 的Markov链
的Markov链 ,对于任意时刻
,对于任意时刻 ,下一状态
,下一状态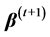 来自分布
来自分布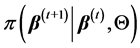 的抽样,即其只和当前时刻
的抽样,即其只和当前时刻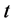 的状态有关,与历史状态
的状态有关,与历史状态 无关。在这些迭代样本的基础上就可以对参数做统计推断,如下式计算后验均值
无关。在这些迭代样本的基础上就可以对参数做统计推断,如下式计算后验均值
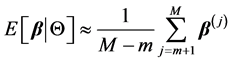
其中,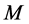 为链的迭代状态数,
为链的迭代状态数,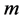 为链的截断状态数。在MCMC算法中,为构造状态转移概率使已知后验分布
为链的截断状态数。在MCMC算法中,为构造状态转移概率使已知后验分布 为平稳分布,常采用的构造方法有Gibbs抽样法,Metropolis-Hastings算法等。本文便是采用Gibbs抽样的MCMC算法。
为平稳分布,常采用的构造方法有Gibbs抽样法,Metropolis-Hastings算法等。本文便是采用Gibbs抽样的MCMC算法。
考虑到联合后验分布(3)式的特点,如文 [5] ,在给定 的条件下,可选取建议分布是
的条件下,可选取建议分布是 元正态分布的Metropolis-Hastings算法对自回归系数
元正态分布的Metropolis-Hastings算法对自回归系数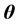 进行后验抽样。为确定建议分布的参数,参考 [6] 中定理给出如下引理。
进行后验抽样。为确定建议分布的参数,参考 [6] 中定理给出如下引理。
引理:对于样本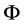 ,模型的
,模型的 维参数向量
维参数向量 的极大似然估计量为
的极大似然估计量为 ,
,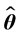 满足:
满足: ,其中
,其中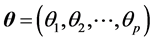 ,
, ,
, 为
为 阶Fisher信息阵,有
阶Fisher信息阵,有
 ,
,
其中,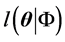 为样本
为样本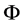 下
下 的似然函数。则根据引理,Metropolis-Hastings算法的建议分布的协差阵取为
的似然函数。则根据引理,Metropolis-Hastings算法的建议分布的协差阵取为
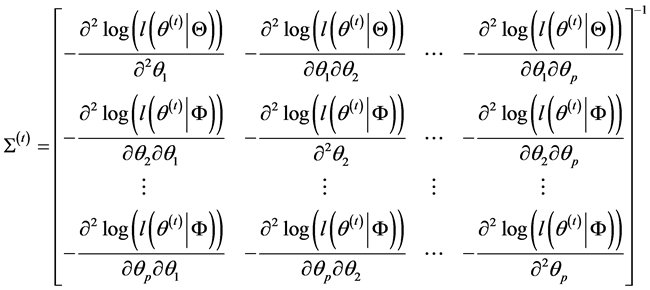
于是,回归系数 的抽样方法的具体步骤见算法1。
的抽样方法的具体步骤见算法1。
算法1:步1:抽取 ;
;
步2:抽取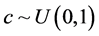 ;
;
步3:若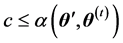 ,则
,则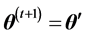 ,否则
,否则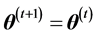 ,其中
,其中
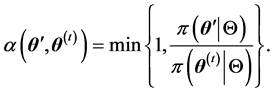
对在参数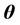 给定下,参数
给定下,参数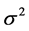 的后验分布核为
的后验分布核为

也就是

其中, 表示自由度为
表示自由度为 的
的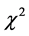 分布。则参数
分布。则参数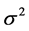 的后验分布核是标准分布,可直接抽样。
的后验分布核是标准分布,可直接抽样。
于是Gibbs抽样方法的具体迭代步骤如下:给定迭代初始值 ,依次取
,依次取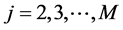 ,那么第j轮迭代的实现步骤如下:
,那么第j轮迭代的实现步骤如下:
步1:从分布 里产生
里产生 ,
,
步2:从分布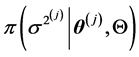 里产生
里产生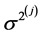 。
。
3. 模拟实验
为了考察Gibbs抽样方法的效果,本节进行模拟实验,为不失一般性,取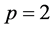 ,则模拟的AR(p)模型如下
,则模拟的AR(p)模型如下

其中, ,记
,记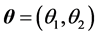 。令参数的真值
。令参数的真值 ,
, ,超参数
,超参数 ,取
,取 的初始值
的初始值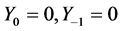 。分别取时间跨度为50, 100, 200三种情况进行模拟比较,模拟迭代10,000次,并舍弃轨道的前5000次迭代,各参数的后验估计值和后验标准差如表1,其中括号内为后验标准差。
。分别取时间跨度为50, 100, 200三种情况进行模拟比较,模拟迭代10,000次,并舍弃轨道的前5000次迭代,各参数的后验估计值和后验标准差如表1,其中括号内为后验标准差。
由表1可见,当样本量较小时就已经接近真实值,且随着样本时间跨度的增加,参数的估计标准差逐渐缩小。
4. 实证分析
自2010年来,上海港集装箱吞吐量一直居世界第一,对其集装箱吞吐量的预测对我国经济的发展至关重要。本文选取1982~2015年的上海港集装箱吞吐量数据(如表2),数据来源于上海市统计年鉴 [7] 。
绘出历年吞吐量的散点图如图1。
由图可见,数据呈现指数上升的趋势,2009年由于世界金融危机上海港集装箱吞吐量锐减,可视为突发事件。因此可对数据做对数处理,处理结果如图2。

Table 1. The estimation of parameters posterior mean
表1. 参数后验均值估计结果
Table 2. Shanghai port’s container throughput from 1982 to 2015
表2. 1982~2015年上海港集装箱吞吐量
经对数处理后,吞吐量随时间的变化有明显的线性趋势。所以对变换后的数据进行时间序列分析。
利用R软件tseries包中的adf.test()函数对变换后的吞吐量做单位根检验,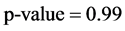 ,说明不能拒绝存在单位根的假设。对变换后的数据做两阶差分后对应的
,说明不能拒绝存在单位根的假设。对变换后的数据做两阶差分后对应的 ,说明差分后的序列平稳,
,说明差分后的序列平稳,

Figure 1. Shanghai port’s container throughput from 1982 to 2015
图1. 1982~2015年集装箱吞吐量

Figure 2. Shanghai port’s logarithmic container throughput from 1982 to 2015
图2. 1982~2015 年集装箱对数吞吐量
且序列的ACF,PACF图如下。
由图3可知,ACF拖尾,PACF两步截尾。可以采用Bayes AR(2)模型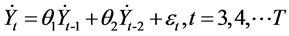


Figure 3. ACF (up), PACF (down) of logarithmic container throughput’s second order difference
图3. 对数吞吐量二阶差分的ACF(上)、PACF(下)
对数据进行拟合,利用上文的Gibbs抽样方法对模型参数进行估计,且先验参数与模拟实验部分一致,Gibbs抽样模拟轨道长10,000,绘出参数的后2000次迭代过程(见图4)。
可见参数迭代平稳,并抛弃轨道的前5000个点,计算参数的后验均值与标准差见表3。其中括号内数字代表参数后验标准差。
则模型的估计结果为
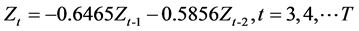
其中,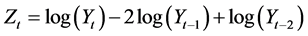 ,于是我们可得未来三年的集装箱吞吐量为3782.107TEU,
,于是我们可得未来三年的集装箱吞吐量为3782.107TEU,


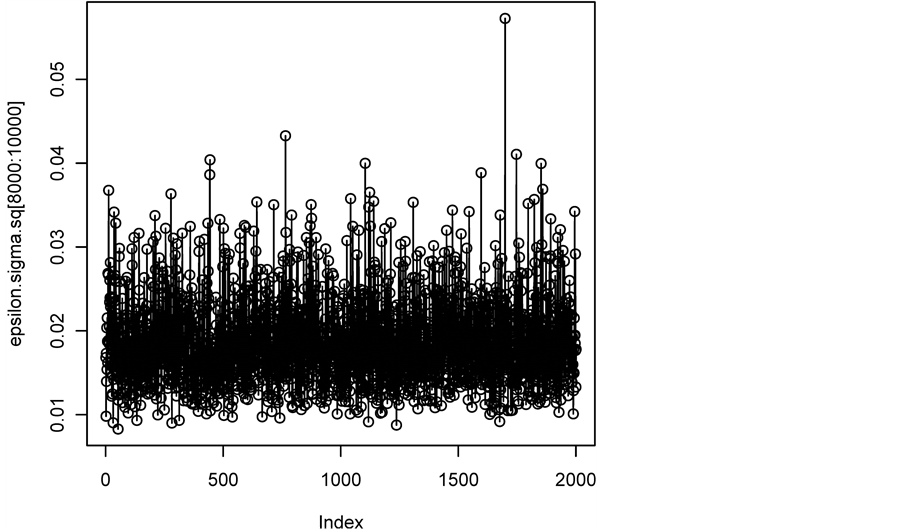
Figure 4. The last 2000 iterations procedure of the parameter
图4. 参数后2000次迭代过程
Table 3. The estimation of parameters posterior mean
表3. 参数后验均值结果
3947.072TEU,4098.362TEU。
由于贝叶斯参数估计方法充分利用了样本的信息和模型信息,估计方法更加灵活,对诸如金融危机之类的突发性事件有着较好的应变能力,也能克服传统估计方法中因为样本不足或者质量不佳导致结果误差较大的缺陷。用贝叶斯估计未知参数的方法得到的模型更适合预测,更能反映现实问题。
文章引用
朱善维. 基于Gibbs抽样的集装箱吞吐量Bayes AR(p)分析
Bayes AR(p) Analysis of Container Throughput Based on the Gibbs Sampling[J]. 统计学与应用, 2016, 05(04): 350-358. http://dx.doi.org/10.12677/SA.2016.54037
参考文献 (References)
- 1. 田歆, 曹志刚, 骆家伟, 等. 基于TEI@I方法论的香港集装箱吞吐量预测方法[J]. 运筹与管理, 2009, 18(4): 82- 89.
- 2. 杨金花, 杨艺. 基于灰色模型的上海港集装箱吞吐量预测[J]. 上海海事大学学报, 2014, 35(2): 28-32.
- 3. 余思勤, 范莹莹. 基于NARX神经网络的港口集装箱吞吐量预测[J]. 上海海事大学学报, 2015, 36(4): 1-5.
- 4. Fernandez, C., Osiewalski, J. and Steel, M. (1997) On the Use of Panel Data in Stochastic Frontier Models with Improper Priors. Journal of Econometrics, 79, 169-193. https://doi.org/10.1016/S0304-4076(97)88050-5
- 5. Altaleb, A. and Chauveau, D. (2002) Bayesian Analysis of the Logit Model and Comparison of Two Metropolis- Hastings Strategies. Computational Statistics and Data Analysis, 39, 137-152. https://doi.org/10.1016/S0167-9473(01)00055-X
- 6. 茆诗松, 王静龙, 濮晓龙. 高等数理统计[M]. 第2版. 北京: 高等教育出版社, 2006: 120-121.
- 7. 上海统计网[Z/OL]. http://www.stats-sh.gov.cn/