Advances in Applied Mathematics
Vol.
12
No.
02
(
2023
), Article ID:
61179
,
11
pages
10.12677/AAM.2023.122053
多级融合的倒置金字塔注意力U-Net在车牌检测中的研究
姚 瑶
上海工程技术大学电子电气工程学院,上海
收稿日期:2023年1月8日;录用日期:2023年1月28日;发布日期:2023年2月9日

摘要
准确测试出车牌位置是车牌识别系统(LPRS)的关键步骤,为了提高车牌检测的性能,本文提出多级融合的倒置金字塔注意力U-net (AUMFIF)。先将原始图像送入改进网络,其次通过原始图像的卷积运算生成多个级别的特征图,通过多层拼接和卷积来检测更多含有丰富的空间信息的特征图。然后以分层的形式,将这些特征图与倒置特征金字塔网络逐层进行融合连接,所得到的特征图不仅有丰富的空间信息还具有饱满的语义信息。最后,将注意力机制用于保留重要区域的信息,并且抑制无关背景区域,便可得出车牌位置的分割图像。为了验证所提出方法的有效性,本文在AOLP车牌数据集上进行了一系列实验。实验结果表明,该方法能够有效地提高车牌位置检测的性能。
关键词
注意力U-Net,多级融合,倒置金字塔特征网络,车牌检测

Research on Multi-Fusion Inverted Pyramid with Attention U-Net in License Plate Detection
Yao Yao
School of Electronic and Electrical Engineering, Shanghai University of Engineering Science, Shanghai
Received: Jan. 8th, 2023; accepted: Jan. 28th, 2023; published: Feb. 9th, 2023

ABSTRACT
Accurate detection of license plate position is a key step of License Plate Recognition System (LPRS). In order to improve the performance of license plate detection, this paper proposed multi-fusion inverted pyramid feature attention U-net (AUMFIF). Firstly, the original image is sent to the improved network, and then the convolution of the original image is used to generate feature maps at multiple levels. More feature maps with rich spatial information can be detected through multi-layer splicing and convolution. Then, in a hierarchical form, these feature maps are fused and connected with the inverted feature pyramid network layer by layer. The resulting feature maps not only have rich spatial information, but also have full semantic information. Finally, the attention mechanism is used to retain the information of important regions, and suppress irrelevant background regions, then the segmented image of license plate position can be obtained. In order to verify the effectiveness of the proposed method, a series of experiments are carried out on AOLP dataset. The experimental results show that this method can effectively improve the performance of license plate position detection.
Keywords:AU-Net, Multi-Fusion, Inverted Pyramid Feature Network, License Plate Detection

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
随着科学技术推动社会的快速发展,车辆的使用极大地改善了交通问题。车牌检测 [1] 在交通管理自动化领域越来越重要。车牌检测广泛应用于电子收费站、停车场车辆自动出入管理等各个领域。典型的车牌识别系统主要由以下两部分组成:车牌检测和车牌字符识别。车牌检测受到天气、光线和其他因素的影响很大。如果没有很好地检测到车牌位置,则无法有效执行后续步骤。然而,在恶劣的工作条件下,现有的检测方法无法准确检测车牌的位置。注意力U-net (AU-net) [2] 通常应用于医学图像分割。它专注于对特定任务有用的显著特征,并抑制输入图像中的不相关区域。受AU-net的启发,本文提出多级融合的倒置金字塔注意力U-net (AUMFIF)。
本文的其余部分安排如下,在第2节中,本文回顾总结了车牌检测的相关背景内容;其次,我们在第3节中描述AUMFIF的网络框架;在第4节中,展示出详细的车牌检测实验以及与其他方法的对比结果;最后,本文在第5节进行总结说明。
2. 研究背景
2.1. 传统的车牌检测方法
本车牌检测旨在从图像或视频中清晰准确地定位车牌,其与识别结果有着一系列相关影响。传统的车牌检测相关工作主要依赖于特征。根据特征的不同,传统方法可大致分为四类:基于颜色的方法、基于边缘的方法、基于字符的方法以及基于纹理的方法。
基于颜色的方法是对车牌的特殊颜色(如蓝色和黄色)与背景内容的不同所进行的观察。Azad等人 [3] 提出了一种基于颜色的方法,将RGB图像转换为HSI空间来用于车牌检测。Deb等人 [4] 使用HSI颜色模型来识别车牌的候选区域。Chang等人 [5] 提出了一种由不同颜色组成的字符边缘来定位台湾车牌的方法,然而,这些基于颜色的方法通常无法在不均匀照明的图像中有效地执行。
基于边缘的方法是基于车牌的边缘信息。牌照的形状通常是具有特殊纵横比的矩形,并且车牌的边缘密度高于图像中的其他区域,因此研究人员广泛使用边缘信息来定位车牌。Chen等人 [6] 对prewitt算术算子进行了改进,使用水平和垂直投影的方法来定位边缘位置的上端与下端。Zhang等人 [7] 采用sobel算术算子来提取垂直的车牌边缘。当使用基于边缘的方法时,通常需要预先确定车牌区域的大小。尽管这类方法通常计算速度很快,但由于图像中有太多不确定的边缘线,所以该方法不能用于倾斜车牌。
由于车牌由一串字符组成,字符结构特征非常明显,因此许多研究人员在车牌检测任务中使用了基于字符的方法加以研究。Lin等人 [8] 提出了一种由两个阶段组成的算法,他们首先使用一张有意义的地图来分割车牌上的字符串。在第二阶段,他们采用滑动窗口方法来计算这些显著的图像特征,就可以用于提取候选字符的最大稳定极值区域(MSER)。Wang等人 [9] 提出了一种基于超像素分割和分层聚类的新字符候选提取方法。Hao等人 [10] 则提出基于MSER的车牌区域提取方法。同时,他们对这些区域都进行了分类,并根据提取区域的SIFT特征来确定最终的定位车牌。总得来说,基于字符的方法是比较可靠的,并且还能有高召回率的回报,但这些方法的性能好坏也取决于图像中所存在的复杂环境条件以及图像内部的干扰因素。
基于纹理的方法也可用于检测车牌,因为车牌区域通常具有非常规的像素纹理分布。在这种情况下,Deb等人 [11] 使用了基于滑动同心窗口(SCW)的技术来定位候选区域。然后,他们的团队使用HIS颜色模型来识别这些区域。与基于边缘的方法和基于颜色的方法相比,基于纹理的方法通常采用更具辨别性的特征,但基于纹理的算法具有较高的计算复杂性。
2.2. 基于深度学习的车牌检测方法
传统的车牌检测方法通常基于人为制作的图像特征,这些人为制作的图像能够在特定的应用场景中取得良好的效果,但这些效果是与功能设计者的经验息息相关的。除此之外,这些传统的方法在复杂环境中并没有展示出良好的适应性。因此,带有深度学习的语义分割技术为实现车牌检测目标提供了一种新的方向。
深度学习的方法能够有效地解决计算机视觉的许多问题。对于目标检测和分割任务,基于深度学习的方法表现的非常好,因此越来越多的研究人员开始设计基于深度学习有效的车牌检测算法。在过去的十年里,基于深度学习的卷积神经网络(Convolutional Neural Network, CNN)方法取得了巨大的进展,因此,全卷积网络(Full Convolutional Network, FCN) [12] 、U-net [13] 以及Enet [14] 相继被用于车牌检测和识别任务。因为实验有着针对鲁棒性的高要求,所以需要一些基于卷积神经网络的方法 [15] [16] 来提取图像特征,而不是像传统方法那样通过人为制作来获得图像特征。Xie等人 [17] 改进了一个基于CNN的框架,名为MD-YOLO网络,用于定位多方向车牌。他们使用了一种基于旋转角度预测的新方法和一种实用的评估策略来解决复杂场景中的车牌问题。但是当检测的目标较小时,该方法表现效果并不理想。Xiang等人 [18] 提出了一种改进的全卷积网络来用于中国的车牌检测,他们的方法在不同的应用场景中取得了不错的结果。Li等人 [19] 使用基于滑动窗口的方法,通过卷积神经网络来检测车牌上字母的候选位置。
3. 研究方法
3.1. 传统的注意力U型网络
U-net的主要特征是类似于U形和跳跃连接的结构。AU-net是U-net模型的改进,AU-net具有获取上下文语义信息的收缩路径,其对应的是精确定位特征的扩展路径。在收缩路径的特征层与扩展路径的相应特征层进行连接之前,通过注意力模块来调整收缩路径的输出特性。
3.2. 多级融合模块
简单的连接操作会导致有意义的信息丢失,经过每一级处理的图像特征仍然存在着丰富的纹理和位置信息,因此有必要对其进行改进以解决这一问题。为了提取更多有效特征,我们在跳转连接中加入了多层拼接和卷积运算,即多级融合。在注意力U-net的跳跃连接路径之前加入多层拼接和卷积运算,能够较好地解决这些问题,并将更多的特征正确地组合到深度特征图中。多级融合模块如图1所示。

Figure 1. Multi-fusion module
图1. 多级融合模块
3.3. 注意力模块
注意力模块如图2所示。x是由每层网络所生成的最后一个特征图,而g是由网络的下一层的特征图所生成的门信号。为了保证通道大小相同且图像的大小不变,将x和g分别进行1 × 1 × 1卷积计算,随后将具有相同通道数的x和g进行拼接和累加,再通过Relu激活函数进行处理,处理完成后将拼接图进行1 × 1 × 1卷积计算和Sigmoid函数来获得由0到1组成的特征图。将特征图与跳跃连接的输入x相乘计算来获得最终的分类图像。其中注意力系数α能和在目标区域内获得较大值,在背景区域获得较小值,这对于提高图像分割的准确性十分有效。

Figure 2. Attention module
图2. 注意力模块
3.4. 多级融合的倒置金字塔注意力U-Net
原始FPN (Feature Pyramid Network)特征金字塔网络使用Resnet作为主网络,而本文所使用的主网络是多级融合网络模块,AUMFIF网络模型左半边是由自上而下的多级融合网络模块,自底向上的倒置特征金字塔网络以及横向融合模块这三个部分组成。AUMFIF如图3所示。倒置特征金字塔网络中联系这三个部分的横向融合结构图如图4所示。

Figure 3. Multi-fusion inverted pyramid attention U-net (AUMFIF)
图3. 多级融合的倒置金字塔注意力U-net (AUMFIF)
观察多级融合的倒置金字塔注意力U-net的结构图,整个检测流程可以描述为:首先,将原始输入图像送入改进网络。其次通过原始图像的卷积运算生成多个级别的特征图。在特征连接之前,由多层拼接和卷积来检测含有丰富空间信息的特征图。然后以分层的形式,将这些特征图与倒置特征金字塔网络逐层进行融合连接,所得到的特征图不仅有丰富的空间信息还具有饱满的语义信息。最后,将注意力机制用于保留重要区域的信息,并且抑制无关背景区域,便可得出车牌位置的分割图像。

Figure 4. Horizontal fusion structure
图4. 横向融合结构
横向连接倒置特征金字塔特征网络的路径能够增强深层特征。横向连接的特征图与经过倒置特征金字塔所提取的特征图都具有大小相同的尺寸,它们通过元素相加,将上采样映射与对应的映射进行合并。再通过迭代计算,生成最终的特征图。最后,本文为了消除上采样的混叠效应便在每个合并的特征图上都分别添加了一层跳跃连接进行3 × 3 × 3卷积计算,这些步骤相继完成后,就能够将具有丰富的空间信息且具有饱满的语义信息特征送入注意力机制模块。
3.5. 交叉熵损失函数
原在训练阶段,本文使用交叉熵损失函数来评估预测值与真实值之间的误差。交叉熵损失函数如公式(1)所示。
(1)
预测值和 值之间的差异越明显,损失值就呈非线性增加。使用交叉熵损失函数的优点是,该模型可以使预测输出值更接近真实值 。
4. 实验分析
4.1. 实验环境
本实验的硬件环境为Intel(R) Core(TM) i9-9900 CPU @ 3.60GHz处理器,内存为40 GB,GPU使用的


 (a) AOLP-AC
(a) AOLP-AC


 (b) AOLP-LE
(b) AOLP-LE


 (c) AOLP-RP
(c) AOLP-RP
Figure 5. License plate image samples in different environments
图5. 不同环境下的车牌图像样本
是NVIDIA GeForce RTX 3080进行加速,内存为10 GB;软件环境使用的是Windows10的64位操作系统,算法编程语言使用的是python3.7,深度学习框架为Pytorch 1.8.1版本。
4.2. 数据集介绍
为了更好地验证本文所提的改进网络在复杂背景、非均匀照明条件和恶劣天气下的车牌检测的性能,本文使用AOLP车牌数据集 [20] 进行测试验证。AOLP数据集包括水平角度在内的不同角度板块,还涉及复杂环境背景下的城市交通板块,它是一个被广泛使用的开源车牌检测数据集。该数据集由2049张车牌图像组成,被分为三个子数据集:AC数据集(681张)、LE数据集(757张)和RP数据集(611张)。图5显示了三种不同环境下的车牌图像样本。在AC数据集中,几乎所有样本都是水平方向的车牌图像,这些图像是在限速通过交叉路口时采集的。LE数据集的样本来自城市交通车辆,包括复杂道路背景中行人、路灯和路标的干扰因素。RP数据集的样本是在倾斜角度所采集的。
在本实验中,AOLP数据集的样本被随机分为训练集(85%)和测试集(15%)。为了确保训练集和测试集的三个子数据集分布的一致性,子数据集的数据按相同比例随机划分,以确保训练集的三个子数据集和测试集中的数据分布大致相同。
4.3. 评估标准
在本文中,使用平均IOU、准确度、召回率、准确度和F-score来评估实验结果,这些评价标准被广泛应用于图像分割。
1) 平均IOU
平均IOU (mean intersection over union, M-IOU)是一种基于类别计算的评估方法,不仅用于语义分割,还可以作为目标检测指标。首先计算每个类别的欠条,然后累加平均值并得到最终评估。如公式(2)所示:
(2)
TP、FN、FP、TN是构成混淆矩阵的4个基础元素:TP是真正例(True Positive)、FP是假正例(False Positive)、FN是假反例(False Negative)、TN是真反例(True Negative)。
2) 准确度Accuracy
准确度是指正确预测样本数量与预测样本总数的比率。公式(3)如下所示:
(3)
3) 召回率Recall
召回率指的是正确预测的样本数量与真实样本总数的比率。公式(4)如下所示:
(4)
4) 精度Precision
精度是指正确预测的样本数与预测样本数之比。公式(5)如下所示:
(5)
5) F-score
F-score是由准确率和召回率组合而成的评估指标,相当于这两个值的调和平均值。召回率和准确率的任何数值变化都会导致F分数的变化,其表达式如公式(6)所示:
(6)
4.4. 实验与结果分析
在对比实验中,由于其他方法以IOU作为车牌检测的标准并将IOU设置为固定值。例如,当IOU为0.5时,对于检测车牌区域的模型,IOU大于区域和真值区域的百分之五十时,其为正样本,否则为负样本。然而,本节提出的方法而是直接根据平均IOU值进行分类。实验结果表明,车牌检测可以在不设置指定IOU的情况下仍然能够实现良好的分割性能。图6是本文方法AUMFIF在三个不同子数据集中的平均IOU和准确性的可视化柱状图。
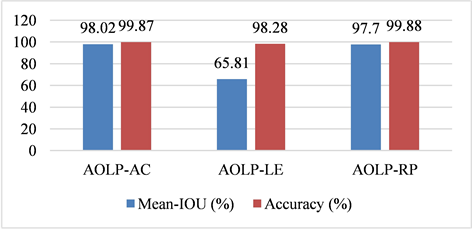
Figure 6. Visual histogram of mean-IOU and accuracy of AUMFIF in different sub datasets
图6. AUMFIF在三个不同子数据集中的平均IOU和准确性的可视化柱状
AC数据集只含有水平角度的车牌图像,其中103张图像用作测试集,578张图像用作训练集。如表1所示,所提出的方法AUMFIF在AC数据集上的精度为99.76%,召回率为98.69%,F-score为99.00%。所提的方法AUMFIF都高于其他方法。图7显示了在AOLP-AC数据集中方法AUMFIF的检测结果分类图。

Table 1. Comparison results of AUMFIF with other methods in AOLP-AC
表1. AUMFIF在AOLP-AC中与其他方法的比较结果
LE数据集是有具有复杂道路背景的车牌图像,其中复杂道路背景是包括城市道路中的行人、路灯以及路标,该数据集中有114幅图像将用于测试,643幅图像则用于训练。如表2所示,所提出的方法AUMFIF在LE数据集上的精度为96.36%,召回率为92.14%,F-score为78.39%。结果表示该方法能够达到有效分割车牌的功能,但比不及Li等人 [19] 图8是AOLP-LE数据集中方法AUMFIF的检测结果分类图。


 原图 真值 AUMFIF分割图
原图 真值 AUMFIF分割图
Figure 7. Method AUMFIF segmentation graph in AOLP-AC dataset
图7. 方法AUMFIF在AOLP-AC数据集中的分割图
Table 2. Comparison results of AUMFIF with other methods in AOLP-LE
表2. AUMFIF在AOLP-LE中与其他方法的比较结果


 原图 真值 AUMFIF分割图
原图 真值 AUMFIF分割图
Figure 8. Method AUMFIF segmentation graph in AOLP-LE dataset
图8. 方法AUMFIF在AOLP-LE数据集中的分割图
RP数据集包含不同角度的倾斜车牌图像。92幅图像用于测试,519幅图像用于训练。如表3所示,我们的方法在RP数据集上的精度、召回率和F-score分别为99.75%、99.27%和98.77%。图9显示了AOLP-RP数据集中方法AUMFIF的检测结果分类图。
Table 3. Comparison results of AUMFIF with other methods in AOLP-RP
表3. AUMFIF在AOLP-RP中与其他方法的比较结果


 原图 真值 AUMFIF分割图
原图 真值 AUMFIF分割图
Figure 9. Method AUMFIF segmentation graph in AOLP-RP dataset
图9. 方法AUMFIF在AOLP-RP数据集中的分割图
5. 总结
多级融合的倒置金字塔注意力U-net (AUMFIF)是基于注意力AU-net的改进。本文将所提出的方法应用于车牌检测领域。在多级融合与多尺度的倒置金字塔FPN的结合下,通过注意力模块获取深层特征,AUMFIF架构可以获得更多丰富的语义特征最终得到图像的语义分割图。实验结果表明,该方法能够有效地提高复杂环境下车牌检测的性能。
文章引用
姚 瑶. 多级融合的倒置金字塔注意力U-Net在车牌检测中的研究
Research on Multi-Fusion Inverted Pyramid with Attention U-Net in License Plate Detection[J]. 应用数学进展, 2023, 12(02): 494-504. https://doi.org/10.12677/AAM.2023.122053
参考文献
- 1. Chowdhury, D., Mandal, S., Das, D., et al. (2019) An Adaptive Technique for Computer Vision Based Vehicles License Plate Detection System. International Conference on Opto-Electronics and Applied Optics, Kolkata, 18-20 March 2019, 1-6. https://doi.org/10.1109/OPTRONIX.2019.8862406
- 2. Oktay, O., Schlemper, J., Folgoc, L.L., et al. (2018) Attention U-Net: Learning Where to Look for the Pancreas. https://arxiv.org/abs/1804.03999
- 3. Azad, R., Davami, F. and Azad, B. (2013) A Novel and Robust Method for Automatic License Plate Recognition System Based on Pattern Recognition. Advances in Computer Science: An Interna-tional Journal, 2, 64-70.
- 4. Deb, K. and Jo, K.H. (2008) HSI Color Based Vehicle License Plate Detection. Interna-tional Conference on Control, Automation and Systems, Seoul, 14-17 October 2008, 687-691. https://doi.org/10.1109/ICCAS.2008.4694589
- 5. Chang, S.L., Chen, L.S., Chung, Y.C., et al. (2004) Automatic License Plate Recognition. IEEE Transactions on Intelligent Transportation Systems, 5, 42-53. https://doi.org/10.1109/TITS.2004.825086
- 6. Chen, R. and Luo, Y.J. (2012) An Improved License Plate Loca-tion Method Based on Edge Detection. Physics Procedia, 24, 1350-1356. https://doi.org/10.1016/j.phpro.2012.02.201
- 7. Zheng, D., Zhao, Y. and Wang, J. (2005) An Efficient Method of License Plate Location. Pattern Recognition Letters, 26, 2431-2438. https://doi.org/10.1016/j.patrec.2005.04.014
- 8. Lin, K., Tang, H. and Huang, T.S. (2010) Robust License Plate Detection Using Image Saliency. IEEE International Conference on Image Processing, Hong Kong, 26-29 September 2010, 3945-3948. https://doi.org/10.1109/ICIP.2010.5649878
- 9. Wang, C., Yin, F. and Liu, C. (2017) Scene Text Detection with Novel Superpixel Based Character Candidate Extraction. International Conference on Document Analysis and Recogni-tion, Kyoto, 9-15 November 2017, 929-934. https://doi.org/10.1109/ICDAR.2017.156
- 10. Hao, W.L. and Tay, Y.H. (2010) Detection of License Plate Char-acters in Natural Scene with MSER and SIFT Unigram Classifier. IEEE Conference on Sustainable Utilization and De-velopment in Engineering and Technology, Kuala Lumpur, 20-21 November 2010, 95-98.
- 11. Deb, K., Chae, H.U. and Jo, K.H. (2009) Vehicle License Plate Detection Method Based on Sliding Concentric Windows and Histogram. Journal of Computers, 4, 771-777. https://doi.org/10.4304/jcp.4.8.771-777
- 12. Kirillov, A., Girshick, R., He, K. and Dol-lár, P. (2019) Panoptic Feature Pyramid Networks. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recog-nition (CVPR), Long Beach, 15-20 June 2019, 6392-6401. https://doi.org/10.1109/CVPR.2019.00656
- 13. Ronneberger, O., Fischer, P. and Brox, T. (2015) U-Net: Con-volutional Networks for Biomedical Image Segmentation. 18th International Conference, Munich, 5-9 October 2015, 234-241. https://doi.org/10.1007/978-3-319-24574-4_28
- 14. Paszke, A., Chaurasia, A., Kim, S., et al. (2016) ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation.
- 15. Wang, Q., Gao, J.Y. and Yuan, Y. (2018) Embedding Structured Contour and Location Prior in Siamesed Fully Convolutional Networks for Road De-tection. IEEE Transactions on Intelligent Transportation Systems, 19, 219-224. https://doi.org/10.1109/TITS.2017.2749964
- 16. Wang, Q., Gao, J.Y. and Yuan, Y. (2018) A Joint Convolutional Neural Networks and Context Transfer for Street Scenes Labeling. IEEE Transactions on Intelligent Transportation Systems, 19, 1457-1470. https://doi.org/10.1109/TITS.2017.2726546
- 17. Xie, L.L., Ahmad, T., Jin, L.W., et al. (2018) A New CNN-Based Method for Multi-Directional Car License Plate Detection. IEEE Transactions on Intelligent Transportation Systems, 19, 507-517. https://doi.org/10.1109/TITS.2017.2784093
- 18. Xiang, H., Zhao, Y., Yuan, Y., et al. (2018) Lightweight Fully Convolutional Network for License Plate Detection. Optik—International Journal for Light and Electron Optics, 178, 1185-1194. https://doi.org/10.1016/j.ijleo.2018.10.098
- 19. Li, H. and Shen, C.H. (2018) Reading Car License Plates Using Deep Convolutional Neural Networks and LSTMs. Image & Vision Computing, 72, 14-23.
- 20. Selmi, Z., Halima, B.H. and Alimi, A.M. (2017) Deep Learning System for Automatic License Plate Detection and Recognition. International Conference on Document Analysis and Recognition, Kyoto, 9-15 November 2017, 1132-1138. https://doi.org/10.1109/ICDAR.2017.187
- 21. Hsu, G.S., Chen, J.C. and Chung, Y.Z. (2013) Applica-tion-Oriented License Plate Recognition. IEEE Transactions on Vehicular Technology, 62, 552-561. https://doi.org/10.1109/TVT.2012.2226218