Journal of Image and Signal Processing
Vol.
11
No.
03
(
2022
), Article ID:
53888
,
12
pages
10.12677/JISP.2022.113013
基于MSRCR-拉普拉斯金字塔方法的低照度 图像增强
刘申澳,韩永华
浙江理工大学信息科学与工程学院,浙江 杭州
收稿日期:2022年6月29日;录用日期:2022年7月10日;发布日期:2022年7月21日

摘要
针对传统Retinex图像增强算法存在的纹理细节保留差、过度增强和色调突变等不足,文中提出了一种基于MSRCR (带色彩恢复的多尺度Retinex算法)的拉普拉斯金字塔方法,用于弱光图像增强。该方法由三个重要部分组成:照度颜色校正、反射成分细节增强和线性加权融合。首先,将伽马校正后的照度加回反射中,实现色彩增强。然后,通过拉普拉斯金字塔处理反射分量来实现细节增强。最后,细节增强的图像和颜色校正的图像通过加权融合重构出增强后的输出图像。主观与客观的性能评估表明,相较于对比算法,文中所提出的方法可以更加有效地增强暗区图像的细节和全局对比度,使得输出图像具备更好的视觉效果。因此,该方法是一种有效的弱光图像增强方法,并具有一定的工程应用价值。
关键词
低照度,图像增强,Retinex,拉普拉斯金字塔,三边滤波

Low Illumination Image Enhancement Based on MSRCR-Laplace Pyramid Method
Shen’ao Liu, Yonghua Han
School of Information Science and Engineering, Zhejiang Sci-Tech University, Hangzhou Zhejiang
Received: Jun. 29th, 2022; accepted: Jul. 10th, 2022; published: Jul. 21st, 2022

ABSTRACT
To address the shortcomings of traditional Retinex image enhancement algorithms such as poor texture detail retention, over-enhancement and tonal mutation, a Laplace pyramid method based on MSRCR (Multiscale Retinex algorithm with color recovery) is proposed in the paper for low light image enhancement. The method consists of three important parts: illumination color correction, reflection component detail enhancement, and linear weighted fusion. First, the gamma-corrected illumination is added back into the reflection to achieve color enhancement. Then, the detail enhancement is achieved by processing the reflection components through Laplace pyramids. Finally, the detail-enhanced image and the color-corrected image are reconstructed by weighted fusion to produce the enhanced output image. The subjective and objective performance evaluations show that the proposed method in the paper can enhance the details and global contrast of the dark area images more effectively compared to the contrast algorithm, making the output image with better visual effects. Therefore, the method is an effective method for low light image enhancement and has certain engineering application value.
Keywords:Low Illumination, Image Enhancement, Retinex, Laplace Pyramid, Trilateral Filtering

Copyright © 2022 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
在低照度条件下拍摄的图像,如夜视或背光等条件下,通常会表现出低对比度、颜色失真和低信噪比的特点,位于黑暗区域的细节信息被“掩埋”,这将阻碍对感兴趣区域信息的识别,因此,对低照度图像进行增强很有必要。图像增强的目的在于提升图像的对比度,使图像的特征更适合人类视觉或机器视觉提取感兴趣的目标信息。低照度图像应该通过增强黑暗区域的细节,抑制曝光过度的区域,改善全局对比度和动态范围来恢复。为了有效改善低照度条件下彩色图像的视觉效果和图像质量,我们提出了一种基于MSRCR的拉普拉斯金字塔方法进行低照度图像增强,该方法采用MSRCR算法估计原始低照度图像中的两个特征分量,即照度和反射率,将两个分量进行分离提取之后,即可进行相应的校正和增强处理,另外本文引入拉普拉斯金字塔进行特征提取,可以获得更多的边缘信息和细节信息,最后采用线性加权融合对光照分量和反射分量进行融合重构出输出增强图像。该方法非常简单明了,因为大多数计算都是在像素级执行的。大量实验表明,本文算法可以使低光照下拍摄的图像得到有效增强,与其他竞争技术相比,该方法在主观和客观评价方面取得了更好的结果,并避免了传统方法过度增强和高噪声等缺点,在不丢失细节信息的情况下保持了图像的自然性,图像的视觉效果和质量得到很大的提升。
综上所述,本文的主要贡献如下:
1) 提出了一种新的用于低照度图像增强的处理框架,将照明分量与反射分量分离处理,最终通过融合重构出增强图像。该框架可以有效地增强各种弱光条件下拍摄的图像;
2) 采用MSRCR算法用于分解卷积图像以获得照度和反射分量。通过对照明进行伽马校正和对增强结果进行补偿来确保色彩自然性能;
3) 利用拉普拉斯金字塔进行特征提取,可以获取更多的边缘信息和细节信息,减少了图像失真;
4) 引入三边滤波滤除反射分量图像中的噪声,该方法弥补了双边滤波无法滤除脉冲噪声的缺陷,从而避免图像出现边缘伪影现象。
2. 相关工作
低照度图像增强处理是低光环境下目标检测(如检测车辆、行人等)的必要工作,许多低照度图像增强算法已经被提出。目前的主流方法总体可以分为两大类:基于数字图像处理的传统方法以及基于深度学习的方法,以下两小节将详细介绍这两部分内容。
2.1. 传统方法
2.1.1. 直方图均衡化
直方图均衡算法 [1] [2] [3] 对图像的原始直方图进行变换。非线性变换用于重新分配图像的像素值,提高图像的整体对比度,使图像更清晰。CLAHE [2] 算法设置阈值来限制图像局部对比度的增强,并使用插值算法来改善块效果。解决了图像对比度过度增强的问题。Ramli等人 [3] 根据平均亮度递归分解输入图像的灰度级。然后对得到的子直方图进行直方图均衡化。该算法处理后的图像在较高程度上保持了图像的亮度,但容易丢失图像的细节信息。另外,直方图均衡算法有一个明显的缺点,就是在图像增强过程中没有考虑图像的空间信息﹐图像对比度增强受到限制。
2.1.2. Retinex的方法
Retinex [4] 理论基于颜色恒常性。该方法将输入的弱光图像分为光层和反射层,然后对光层进行校正,最终得到光照均匀的图像。多尺度Retinex (MSR)算法 [5] 压缩了图像的动态范围,增强结果的亮度合适。但图像局部区域对比度增强,导致局部细节颜色失真。MSRCR [6] 在MSR中加入色彩恹复因子来调整色彩失真问题。LIME [7] 使用先验结构来估计光照图并确定最终增强结果的反射率。Priyadarshini等人 [8] 将CNN与Retinex理论相结合,提出了一种多尺度Retinex模型,该模型利用多尺度对数变换、微分卷积、颜色恹复函数三个功能模块对图像进行增强。Zhang等人 [9] 结合最大信息商和Retinex理论提出了一种自监督的光照增强网络。此外,图像处理中基于Retinex理论的其他算法可以提高图像对比度。避免颜色失真,但算法效率较低,难以应用于实际应用。
2.1.3. 小波变换的方法
基于小波变换的图像增强算法增强了多尺度的图像。该类算法认为在低照度环境下获取的图像对图像的高频分量影响较大。Jung等人 [10] 提出了一种基于双树复小波变换(DT-CWT)的高效对比度增强方法,该方法可以在不放大噪声的情况下对大范围的图像进行操作。然而,大多数基于小波变换的算法对图像的高频部分进行了增强而忽略了图像的低频部分,导致增强效果不佳。
2.2. 深度学习
2.2.1. 卷积神经网络
LIME [7] 算法通过使用增强的拉格朗日数乘法和加权策略来实现光照图优化。基于深度自动编码器的方法LLNet [11] 从低光图像中识别信号特征并自适应地增强图像。该方法避免了图像较亮部分过饱和的问题。RetinexNet [12] 的图像分解和连续增强操作。此外,该方法使用去噪工具BM3D [13] 对分解后的反射图进行去噪。该方法为图像增强方法提供了一个很好的分解方案。KinD [14] 从Retinex理论中汲取灵感。图像被分解为两部分,光照图和反射图,光照率用于调光,反射率用于劣化去除。
2.2.2. 对抗生成网络
基于对抗生成网络的方法不需要配对数据集,但需要仔细选择训练图像。Enlighten GAN [15] 通过无监督学习增强图像,该学习基于双重鉴别器来平衡全局和局部低光图像。Zero-DCE [16] 也是一种用于图像增强的无监督学习方法。该方法针对每个像素学习增强的高阶方程的参数,通过调整方程的参数来学习网络。这种方法开辟了一种新的学习策略,消除了需要配对数据集,但由于缺少真实数据而无法恢复图像细节的问题。
这些工作的性能在很大程度上依赖于数据集的质量。由于缺乏一个良好的指标来评估增强结果的整体质量的各个方面,例如细节保留、视觉自然度和对比度分布,基于深度学习方法的增强结果在某些视觉方面并不令人满意。
3. 本文算法
下面详细介绍MSRCR-拉普拉斯金字塔(MSRCR-LP)方法的整体框架以及实现过程。
3.1. 整体框架
首先,该方法使用MSRCR来估计照明,然后,对照度分量进行伽马校正以增强颜色,并使用拉普拉斯金字塔来增强反射的细节。最后,将校正后的照明添加到反射分量中,并使用由拉普拉斯金字塔处理的图像对结果进行加权。该方法的整体框图如图1所示:
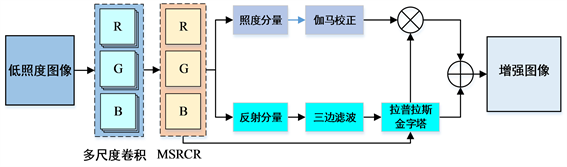
Figure 1. Overall framework of MSRCR-LP
图1. MSRCR-LP整体框架
3.2. MSRCR对比度增强
MSRCR算法是Retinex算法 [17] [18] [19] 的扩展,它能实现在广泛的照明条件下感知表面的恒定颜色,从而有效提高了图像的质量,从而其色彩恒常性能相较于传统的Retinex算法有了很大的提升。不同于传统的线性和非线性方法只能增强某一类图像特征,Retinex算法可以自适应地增强各种不同类型的图像。它假设理想图像表示为:
(1)
其中,L对应图像的照度分量,决定着图像的动态范围;R是独立于照明的反射分量。它对应于图像的高频分量,即图像的细节特征。Retinex算法的目标是从初始图像中估计照度L,通过去除L即可得到反射分量。然而,单尺度Retinex (SSR)算法无法在动态范围和色调对比度之间实现平衡,甚至可能导致图像存在光晕伪影。考虑到SSR的局限性,Jobson等人 [5] 提出了多尺度Retinex (MSR)算法,MSR算法将SSR的不同加权尺度相加。MSR算法兼顾图像动态范围和颜色保真度 [19],定义如下:
(2)
(3)
其中,RMSRi是使用MSR算法对第I分量图像I(x,y)进行变换的输出,G(x,y)是个N不同尺度的包络支持函数。这里,N代表维度,考虑到计算效率,我们在实际应用中通常使用三维(N = 3)。通常,小刻度为 ,中刻度为 ,大范围为 ,最后,ωn表示权重,其中 ,在实际应用中每个ωn的值相等。由于MSR的输出图像可能有明显的颜色失真。为了解决这个问题,进一步提出了MSRCR,其表达如下:
(4)
其中 是用于调整RGB颜色通道百分比的颜色恢复函数。因为我们对MSRCR使用单色通道图像,所以我们将 重新定义如下:
(5)
其中M是输入图像的像素总数。实际上,由于图像本身或光线的影响,每个图像的动态范围是不同的。在传输估计中,我们考虑了模糊图像的动态范围,因为它可以代表部分光线照度,并有助于传输估计。同时,这避免了当传输和模糊图像关系太密切时,恢复图像中出现过饱和 [20]。
3.3. 三边滤波
针对反射分量图像存在明显噪声的问题,故有必要对其边缘位置的像素进行平滑滤波。在夜视或背光这种自然环境下获取的图像往往不仅仅包含高斯噪声,而且存在脉冲噪声,然而双边滤波器在处理脉冲噪声方面的性能并不理想,它会将脉冲噪声视作图像边缘,因此处理过后会出现边缘伪影现象 [21]。所以本文采用三边滤波的方法来滤除反射分量图像包含的噪声,三边滤波器在双边滤波器基础上添加了一个脉冲权重,因此,其在增强图像的细节信息以及对于在滤除图像加性高斯噪声等方面有很好的效果,同时对图像可能存在的脉冲噪声有很好的处理效果,解决了图像的边缘伪影等问题。
三边滤波是由双边滤波改进得到,其核心是在原滤波器基础上引入一个脉冲权重,用于处理脉冲噪声 [22]。令x、y分别表示一幅图像中两个任意像素的位置,I(x,y)和I(y)表示这两个像素的像素值,x = (x1,x2)是待处理像素点的位置,表示中心点为x、滤波器宽为N的邻域,该滤波器被应用处理真实图像时,可令K=Kx(1)。权重函数可表示如下:
(6)
本文中采用秩序绝对差(ROAD)函数 [23] 判断任意一像素点是否处于图像中的边缘位置。设:
(7)
则:
(8)
其中表示ri(x)邻域K中删除d(x,y)后的第i个小的d(x,y)值;而m的数量是K邻域内除x点外的像素点总数的一半。图像边缘点所在的邻域一半以上的像素点都与这个边缘点的灰度值相近,由此得到的秩序绝对差函数值将较小;反之会存在较大的值 [24]。由上述的定义可知:K = Kx(1),m = 1。这里将脉冲权重函数定义为:
(9)
该权重函数通过用当前像素点周围像素的加权平均值来代替受脉冲噪声干扰的点,达到平滑滤除脉冲噪声的目标。另外为了减小未被脉冲噪声干扰的像素点受到影响的概率 [25],令:
(10)
(11)
若当前点没有受脉冲噪声影响,则 ,即脉冲权重不存在,此时三边滤波器相当于双边滤波器;若存在脉冲噪声,脉冲权重则会对当前点进行三边滤波处理。下面给出了滤除噪声后的图像点GF(x)的表达式:
(12)
3.4. 拉普拉斯金字塔特征提取
为了解决三边滤波后图像部分细节信息丢失的问题,可以通过拉普拉斯金字塔将增强后的MSRCR图像分解为不同的空间频带,然后对每个空间频率层分别进行处理,提取出更多的边缘信息和细节信息。将上述信息与滤波图像进行加权融合,增强图像细节。在高斯金字塔的启发下 [26],拉普拉斯金字塔由Adelson和Burt提出 [27],其核心就是对输入图像进行分解,并获得不同分解层的详细特征信息。首先,对原始图像进行高斯低通滤波和隔行子采样,以获得高斯金字塔的第一层,由此类推,然后对获取的新的一层图像进行上述滤波和采样操作,以获得上层图像,从而构建出高斯金字塔。在此过程中,高斯金字塔的构造过程可表示如下:
(13)
其中N是高斯金字塔中的层数,CL和RL分别是高斯金字塔中第L层的列数和行数,ω(m,n)是二维低通滤波器。高斯金字塔由 多层图像构成,其中G0是底层图像。拉普拉斯金字塔可以通过在高斯金字塔中找到相邻层之间的差异来获得。利用插值方法将第k层图像Gk放大,Gk被放大为 ,所以Gk的大小和Gk−1的大小一样,该过程如下式所示:
(14)
其中Gk是金字塔的第k层, 是Gk的扩展图像,第k − 1层的图像Gk−1由以下方式表示:
(15)
公式(14)生成第k − 1层拉普拉斯金字塔。因为Gk是Gk−1低通滤波和下采样,Gk的细节明显少于Gk-1。因此, 由Gk插值得到,仍然小于Gk-1。LPk-1是 和Gk−1的差值,它不仅反映了高斯金字塔Gk和Gk-1的不同层之间的差异,而且包括在Gk-1重模糊和下采样过程中损失的高频信息 [27]。拉普拉斯金字塔的定义如下:
(16)
其中表示金字塔顶层,LPL是第L层图像,拉普拉斯金字塔由 组成。其定义可表示如下:
(17)
其中TF是表示滤波后的图像,RMSRCRi表示采用MSRCR算法增强后的图像,Layers是金字塔中的层数,Sigma1是第一金字塔的比例,Radius1是第一金字塔的半径,Sigma2是第二金字塔的比例,Radius2是第二金字塔的半径,λ代表权重系数。使用RGB色彩空间的每个通道,增强图像RMSRCRi的拉普拉斯金字塔的表达式如下式所定义:
(18)
(19)
(20)
优化后的拉普拉斯金字塔对RMSRCRi的两个不同尺度的高斯金字塔层进行下采样,得到两个高斯金字塔后进行区分,然后得到拉普拉斯金字塔细节图像。最后,将预先设定的权重系数λ(λ>1)加入到滤波后的图像中,从而得到拉普拉斯金字塔的细节图像。
(21)
3.5. 线性加权融合
基于上述过程,通过MSRCR可以得到 、 和 ,它们分别是增强的R、G和B通道;伽马校正获得经过照明校正的R、G和B通道,分别是GaR、GaG和GaB。此外三边滤波器获得经过去除噪声后的R、G和B通道,即TFR、TFG和TFB,拉普拉斯金字塔从RGB颜色空间获得每个通道的细节特征LLR、LLG和LLB。通过将颜色校正图像的校正照明添加回反射分量,获得 、 和 。得到细节增强图像和颜色校正图像后,对每个通道的RGB颜色空间进行线性加权融合得到增强输出图像的每个通道分量如式(22)~(24)所示:
(22)
(23)
(24)
其中ResultR(x,y)、ResultG(x,y)和ResultB(x,y)表示R、G和B通道的增强图像,α是权重系数,并设置 。
4. 实验结果与分析
为了验证本文提出的算法的有效性,同时和其他增强算法的性能进行对比,本节将新提出的算法与几种主流且先进的方法进行定性和定量比较,包括直方图均衡化(AE)、LIME算法 [7]、MSRCR算法并给出了这4种图像增强方法对应的低照度图像实验结果,所有方法都在6张具有不同程度的暗度和噪声水平的图像上进行了测试。图2(a)~(f)是6幅低照度原始图像,图3(a)~(d)分别是基于上述四种方法的实验结果。所有实验均在运行Windows 10操作系统、64 G RAM和2.4 GHz CPU的PC上进行。
4.1. 主观评价
从图3的实验结果可以直观得出,无论源图像是远景还是近景,所有的算法都明显改善了每张图像的整体可见度和对比度,都能获得符合人类视觉的较清晰图像,图像增强使得源图像中被“掩埋”在黑暗中的细节信息被增强得突显出来。然而通过仔细观察可以发现这些算法之间的差异,直方图均衡化和LIME算法处理后的图像明显比其他图像暗,初始的暗区并未的得到充分的曝光,未能恢复低照度区域的
 (a) 测试图像1
(a) 测试图像1
 (b) 测试图像2
(b) 测试图像2
 (c) 测试图像3
(c) 测试图像3
 (d) 测试图像4
(d) 测试图像4
 (e) 测试图像5
(e) 测试图像5
 (f) 测试图像6
(f) 测试图像6
Figure 2. Low-light raw image
图2. 低照度原始图像





 (a) 直方图均衡化
(a) 直方图均衡化





 (b) LIME算法
(b) LIME算法





 (c) MSRCR算法
(c) MSRCR算法





 (d) 本文算法
(d) 本文算法
Figure 3. Low-light image enhancement results based on different algorithms
图3. 基于不同算法的低照度图像增强结果
像素的颜色,依旧有不少细节信息因为亮度和对比度较低而变得模糊,所得到的图像还是存在缺陷。图3(c)对应的增强图像显然具有更大的对比度,有许多突出的细节。然而,这些图像表现出严重的色调偏差,并且可以很明显的感受到图像收到高强度噪声的干扰,图像整体的视觉效果较差。图3中(d)对应本文提出的算法的增强结果,我们可以得到所提出的算法大大增强了需要强调的目标前景,在色彩和细节方面都有明显改善,而没有过度放大黑暗区域的噪声,也没有过度增强图像,并且不存在色彩偏差的问题,图像整体呈现清晰自然的视觉效果,远优于其他算法。总的来说,通过人类视觉主观评估,本文的算法在可见度、对比度和颜色方面都取得了比其他算法更好的结果。
4.2. 客观评价
为了客观地评估算法的有效性和高效性,我们信息熵、峰值信噪比(PSNR)和对比度三个客观评价指标。信息熵反映图像信息量大小,其值越大,则图像信息越丰富,细节保持越好。峰值信噪比(PSNR)表示一个信号的最大功率与可能影响其噪声功率的比值,PSNR越大,失真度就越小。对比度能够较好地反映视觉效果,其值越大,则图像越清晰醒目。均方误差,也被称为图像的平均灰度值方差,它可以反映图像灰度值的动态范围。其计算方法如式(26)~(28)所示,为了计算PSNR。我们先引入均方误差(MSE),MSE值越小,表明隐藏在两个图像中的信息越相似,其计算方法如式(25)所示,最后得到上述评估指标的结果如图4所示。
(25)
(26)
(27)
(28)
其中,f(x,y)为初始图像像素点(x,y)的像素值,F(x,y)为增强图像像素点(x,y)的像素值,g(x,y)为增强图像像素点(x,y)的梯度值,M和N分别是图像的宽和高。
从图4的结果我们得出,基于本文算法得到的图像在信息熵和峰值信噪比以及对比度上,都稳定地超过了其他算法,这分别对应在增强性能方面,本文提出的方法增强的图像具有更高的对比度和更丰富的细节,同时包含的噪声更少,因此图像失真最小。上述指标的比较结果表明,本文的方法的综合性能远远优于其他方法,我们提出的方法对真实的低照度彩色图像具有更好的增强效果。
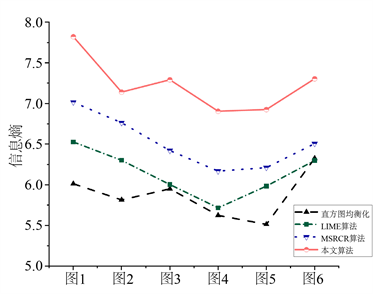 (a) 信息熵
(a) 信息熵
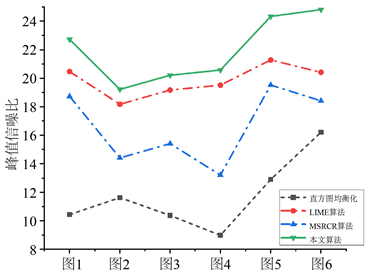 (b) 峰值信噪比
(b) 峰值信噪比
 (c) 对比度
(c) 对比度
Figure 4. Objective evaluation indicator results
图4. 客观评估指标结果
5. 结论
本文提出了一种改进的低照度图像增强算法。本文解决了低照度图像增强的两个问题:曝光不充分无法凸显图像细节信息和过度增强从而导致色彩偏差和高噪声干扰。针对低照度图像的特性,在深入研究经典的Retinex理论的基础上,我们在传统的MSRCR算法的基础上融合拉普拉斯金字塔方法,将二者的优势结合,在尽可能多地保留图像细节的前提下,处理的图像信息色彩丰富,色彩丰富,颜色更接近原图,且并未造成色差偏差和过度增强。通过信息熵、峰值信噪比、对比度三个客观指标的评估,可以得出本文提出的算法优于其他三种对比算法,表明该算法对于弱光彩色图像的增强具有一定的参考意义。值得肯定的是,我们的低光图像增强技术可以为许多基于视觉的应用提供支持,例如边缘检测、特征匹配、对象识别和跟踪,通过提供高可见度的输入图像,从而提高后续的检测和识别性能。不足的是所提算法不能用于增强视频图像,需要进一步努力通过降低计算复杂度来提高其实时性能。
基金项目
这项工作得到了浙江省自然科学基金项目LY17F020034号拨款的支持。
文章引用
刘申澳,韩永华. 基于MSRCR-拉普拉斯金字塔方法的低照度图像增强
Low Illumination Image Enhancement Based on MSRCR-Laplace Pyramid Method[J]. 图像与信号处理, 2022, 11(03): 113-124. https://doi.org/10.12677/JISP.2022.113013
参考文献
- 1. Cheng, H.D. and Shi, X.J. (2004) A Simple and Effective Histogram Equalization Approach to Image Enhancement. Digital Signal Processing, 14, 158-170.
https://doi.org/10.1016/j.dsp.2003.07.002 - 2. Reza, A.M. (2004) Realization of the Contrast Limited Adaptive Histogram Equalization (CLAHE) for Real-Time Image Enhancement. Journal of VLSI Signal Processing Systems for Signal, Image and Video Technology, 38, 35-44.
https://doi.org/10.1023/B:VLSI.0000028532.53893.82 - 3. Chen, S.D. and Ramli, A.R. (2003) Contrast Enhancement Using Recursive Mean-Separate Histogram Equalization for Scalable Brightness Preservation. IEEE Transactions on Consumer Electronics, 49, 1301-1309.
https://doi.org/10.1109/TCE.2003.1261233 - 4. Land, E.H. (1977) The Retinex Theory of Color Vision. Scientific American, 237, 108-129.
https://doi.org/10.1038/scientificamerican1277-108 - 5. Jobson, D.J., Rahman, Z. and Woodell, G.A. (1997) A Multiscale Retinex for Bridging the Gap between Color Images and the Human Observation of Scenes. IEEE Transactions on Image Processing, 6, 965-976.
https://doi.org/10.1109/83.597272 - 6. Jiang, B., Woodell, G.A. and Jobson, D.J. (2015) Novel Multi-Scale Retinex with Color Restoration on Graphics Processing Unit. Journal of Real-Time Image Processing, 10, 239-253.
https://doi.org/10.1007/s11554-014-0399-9 - 7. Guo, X.J., Li, Y. and Ling, H.B. (2016) LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Transactions on Image Processing, 26, 982-993.
https://doi.org/10.1109/TIP.2016.2639450 - 8. Priyadarshini, R. Bharani, A., Rahimankhan, E. and Rajendran, N. (2021) Low-Light Image Enhancement Using Deep Convolutional Network. In: Raj, J.S., Iliyasu, A.M., Bestak, R. and Baig, Z.A., Eds., Innovative Data Communication Technologies and Application, Springer, Singapore, 695-705.
https://doi.org/10.1007/978-981-15-9651-3_57 - 9. Zhang, Y., Di, X., Zhang, B., et al. (2020) Self-Supervised Image Enhancement Network: Training with Low Light Images Only. arXiv:2002.11300.
- 10. Jung, C., Yang, Q., Sun, T., et al. (2017) Low Light Image Enhancement with Dual-Tree Complex Wavelet Transform. Journal of Visual Communication and Image Representation, 42, 28-36.
https://doi.org/10.1016/j.jvcir.2016.11.001 - 11. Lore, K.G., Akintayo, A. and Sarkar, S. (2017) LLNet: A Deep Autoencoder Approach to Natural Low-Light Image Enhancement. Pattern Recognition, 61, 650-662.
https://doi.org/10.1016/j.patcog.2016.06.008 - 12. Wei, C., Wang, W., Yang, W. and Liu, J. (2018) Deep Retinex Decomposition for Low-Light Enhancement. arXiv:1808.04560.
- 13. Dabov, K., Foi, A., Katkovnik, V., et al. (2007) Image Denoising by Sparse 3-D Transform-Domain Collaborative Filtering. IEEE Transactions on Image Processing, 16, 2080-2095.
https://doi.org/10.1109/TIP.2007.901238 - 14. Zhang, Y.H., Zhang, J.W. and Guo, X.J. (2019) Kindling the Darkness: A Practical Low-Light Image Enhancer. Proceedings of the 27th ACM International Conference on Multimedia, Nice, 21-25 October 2019, 1632-1640.
https://doi.org/10.1145/3343031.3350926 - 15. Jiang, Y.F., Gong, X.Y., Liu, D., et al. (2021) EnlightenGAN: Deep Light Enhancement without Paired Supervision. IEEE Transactions on Image Processing, 30, 2340-2349.
https://doi.org/10.1109/TIP.2021.3051462 - 16. Guo, C.L., Li, C., Guo, J., et al. (2020) Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 13-19 June 2020, 1777-1786.
https://doi.org/10.1109/CVPR42600.2020.00185 - 17. Wu, L.F., Zhou, P. and Xu, X. (2013) An Illumination Invariant Face Recognition Scheme to Combining Normalized Structural Descriptor with Single Scale Retinex. Chinese Conference on Biometric Recognition, Jinan, 16-17 November 2013, 34-42.
https://doi.org/10.1007/978-3-319-02961-0_5 - 18. Lin, H.N. and Shi, Z.W. (2014) Multi-Scale Retinex Improvement for Nighttime Image Enhancement. Optik, 125, 7143-7148.
https://doi.org/10.1016/j.ijleo.2014.07.118 - 19. Rahman, Z., Jobson, D.J. and Woodell, G.A. (2011) Investigating the Relationship between Image Enhancement and Image Compression in the Context of the Multi-Scale Retinex. Journal of Visual Communication and Image Representation, 22, 237-250.
https://doi.org/10.1016/j.jvcir.2010.12.006 - 20. Liu, Y.H., Yan, H.M., Gao, S.B. and Yang, K.F. (2018) Criteria to Evaluate the Fidelity of Image Enhancement by MSRCR. IET Image Processing, 12, 880-887.
https://doi.org/10.1049/iet-ipr.2017.0171 - 21. Deswal, S., Gupta, S. and Bhushan, B. (2015) A Survey of Various Bilateral Filtering Techniques. International Journal of Signal Processing, Image Processing and Pattern Recognition, 8, 105-120.
https://doi.org/10.14257/ijsip.2015.8.3.10 - 22. Choudhury, P. and Tumblin, J. (2005) The Trilateral Filter for High Contrast Images and Meshes. ACM SIGGRAPH 2005 Courses, Los Angeles, 31 July-4 August 2005, 5-es.
https://doi.org/10.1145/1198555.1198565 - 23. Garnett, R., Huegerich, T., Chui, C., et al. (2005) A Universal Noise Removal Algorithm with an Impulse Detector. IEEE Transactions on Image Processing, 14, 1747-1754.
https://doi.org/10.1109/TIP.2005.857261 - 24. Chang, H.H. (2010) Entropy-Based Trilateral Filtering for Noise Removal in Digital Images. 2010 3rd International Congress on Image and Signal Processing, Yantai, 16-18 October 2010, 673-677.
https://doi.org/10.1109/CISP.2010.5647219 - 25. Vaudrey, T. and Klette, R. (2009) Fast Trilateral Filtering. International Conference on Computer Analysis of Images and Patterns, Münster, 2-4 September 2009, 541-548.
https://doi.org/10.1007/978-3-642-03767-2_66 - 26. Li, S.T., Hao, Q.B., Kang, X.D., et al. (2018) Gaussian Pyramid Based Multiscale Feature Fusion for Hyperspectral Image Classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 11, 3312-3324.
https://doi.org/10.1109/JSTARS.2018.2856741 - 27. Adelson, E.H., Anderson, C.H., Bergen, J.R., et al. (1984) Pyramid Methods in Image Processing. RCA Engineer, 29, 33-41.