Open Journal of Nature Science
Vol.03 No.03(2015), Article ID:15926,8
pages
10.12677/OJNS.2015.33011
The Application Research of Model Selection and Model Averaging in Meta-Analysis
Xiaoxiao Yin
School of Statistics and Mathematics, Yunnan University of Finance and Economics, Kunming Yunnan
Email: yinxiaoxiao2011@163.com
Received: Jul. 27th, 2015; accepted: Aug. 14th, 2015; published: Aug. 21st, 2015
Copyright © 2015 by author and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
Model selection and model averaging have been the important issues which are researched by statistics and economic circles. This paper relies on theories and methods of Meta-analysis and takes the analysis of factors influencing legumes-rhizobium mutualism cooperative systems as an example. Then, the application results of model selection and model averaging method in meta- analysis are compared. The results show that model averaging method can be applied to meta- analysis and its performance is better than model selection.
Keywords:Meta-Analysis, Model Selection, Model Averaging
模型选择与模型平均在Meta分析中的应用研究
尹潇潇
云南财经大学统计与数学学院,云南 昆明
Email: yinxiaoxiao2011@163.com
收稿日期:2015年7月27日;录用日期:2015年8月14日;发布日期:2015年8月21日

摘 要
模型选择与模型平均一直是统计学与计量经济学界研究的重要问题,本文依托Meta分析理论和方法,以分析豆科植物-根瘤菌互利共生合作系统的影响因素为例,比较模型选择与模型平均方法在Meta分析中的应用效果,结果表明模型平均方法既可应用于Meta分析中,分析效果又优于模型选择。
关键词 :Meta分析,模型选择,模型平均

1. 引言
通过统计建模解决一个实际问题时,往往我们可以建立多个统计模型,现在面临的问题是究竟采用哪个模型分析问题的效果较好,或者是怎样将所有模型提供的信息都充分利用起来,这就涉及到模型选择和模型组合的问题了。模型选择旨在从备选模型集中选择一个最优的模型,而模型组合(即模型平均)则为了充分利用所有模型提供的信息,给每个模型赋予一定的权重将它们组合起来。这样就避免选到一个分析效果差的模型,因为通过模型选择选出来的模型未必就是效果好的,只能说在所有模型中相对较好。因此,本文以分析豆科植物–根瘤菌互利共生系统的影响因素为例,分别使用这两种方法进行分析,然后比较这种方法的研究结果,结果表明模型平均方法不仅可以应用于Meta分析,而且其分析效果优于模型选择。
2. 研究背景
很多学者通过模型选择与模型平均方法分析解决一些实际问题,如Jerald B. Johnson等[1] 在研究生态学与进化论的相关问题时,通过Akaike information criterion (AIC)、Small sample unbiased AIC (AICc)、似然比检验以及Schwarz criterion等准则进行模型选择。尽管模型选择在一定条件下可以解决很多问题,但是它仍然有一些缺陷,如:可能会丢失一些有用的信息,由于问题分析都是基于所选择的模型,这样其他可能模型所反映的信息就会丢失;存在很大的风险,选择的模型可能与真实数据产生的过程比较接近,但有时相差甚远,而我们的目标并一定是寻找真实数据产生的过程,有时是估计参数或做预测。张新雨等[2] 采用多种模型平均方法如S-AIC、S-BIC、Jacknife等构建组合模型对我国的粮食产量进行预测。Donald Berry等[3] 于贝叶斯模型平均(BMA)的方法分析补充维生素E和死亡率的关系;在Meta分析的研究中,LiQuefeng等[4] 使用Lasso变量选择的方法处理基因表达数据。当Meta分析中涉及到多个备选模型时,一个自然的问题是如何确定一个合适的模型并据此开展分析,该问题落入了模型选择的范畴。鉴于上述模型选择方法的一些缺陷,国内外学者提出了许多解决办法,其中模型平均方法就是一种常用的而且备受欢迎的方法。但是,Meta分析中的模型平均问题还没有得到研究。接下来我们将模型平均方法应用于Meta分析中,研究豆科植物–根瘤菌互利共生系统的影响因素。
3. 研究方法介绍
3.1. 模型选择(Model Selection)
模型选择,伴随着不确定性,它是目前利用强大的计算机及其软件更详细的去探索数据提供信息的一个实践的例子。简而言之,模型选择就是从建立的众多可能模型中选择一个最适合解决已知问题的模型。模型选择的方法有很多,如Akaike information criterion (AIC)、Schwartz’s Bayes information criterion (BIC),AIC和BIC的计算公式如(1)、(2)式:
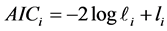 ,
, (1)
(1)
 ,
,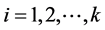 (2)
(2)
其中k为候选模型集中模型的个数; 和
和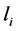 分别为第i个模型的极大似然函数和未知参数的个数;而n为样本的容量。
分别为第i个模型的极大似然函数和未知参数的个数;而n为样本的容量。
此外,我们还有其他模型选择的方法,如focused information criterion (FIC),FIC是通过极小化固定参数估计的均方误差(MSE)进行模型选择的,通常选择最小的MSE模型,这说明了FIC可应用于一些常见的情况下。虽然这些方法在统计学领域应用的非常普遍,但是它们也有各自的优点和缺点,一方面,通过AIC、BIC和FIC选择到一个最好的模型,我们可以利用该模型去解释数据的所有方面;另一方面,我们并不能确定所选择的模型对于一个估计好但对其他的估计效果也许会很差。因此,下面我们就介绍弥补模型选择缺陷的方法——模型平均。
3.2. 模型平均(Model Averaging)
模型平均,顾名思义,就是把来自不同模型的估计或者预测通过一定的权重平均起来,在一些文献中也称为模型组合,它一般包括组合估计和组合预测。事实上,模型选择是模型平均的特例,模型的权重取0或1,所以模型平均所做的估计比较稳健。模型平均的关键在于如何选取组合的权重,常用的权重选择方法有Smoothed AIC (S-AIC)、Smoothed BIC (S-BIC)、Mallow准则、Jackknife准则和OPT最优权重选择法等。下面我们简单的介绍下基于S-AIC、S-BIC以及Mallow准则的权重选择方法。本文主要运用S-AIC进行模型平均。
基于S-AIC和S-BIC准则的权重选择方法由Buckland,Burnham和Augustin (1997) [5] 提出,权重的计算公式为:
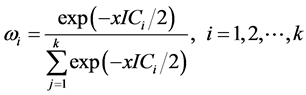 (4)
(4)
其中k表示候选模型集中模型的个数;i代表第i个模型;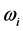 是第i个模型的权重;
是第i个模型的权重;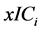 为第i个模型的AIC或BIC。由上可发现S-AIC和S-BIC的计算比较简单,因而是比较常用的权重选择方法。
为第i个模型的AIC或BIC。由上可发现S-AIC和S-BIC的计算比较简单,因而是比较常用的权重选择方法。
Mallow准则[6] 最初是在2007年由Hansen提出的,他通过极小化Mallow’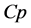 准则构建了最小二乘模型平均估计。具体过程为:
准则构建了最小二乘模型平均估计。具体过程为:
假设候选模型集中共有M个近似模型,被解释变量的实际值序列记为 ,预测值序列为
,预测值序列为 ,
, 为M个模型的权重集合,且满足
为M个模型的权重集合,且满足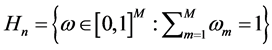 。则
。则 的模型平均估计为
的模型平均估计为
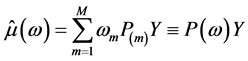 (5)
(5)
其中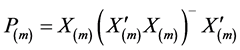 ,
,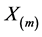 是一个
是一个 矩阵,其元素为
矩阵,其元素为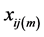 (
( 为第m个模型的解释变量的取值序列),
为第m个模型的解释变量的取值序列), 为第m个模型含有的回归变量个数。
为第m个模型含有的回归变量个数。
模型平均的Mallow准则为
 (6)
(6)
其中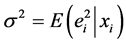 ,
,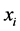 为自变量的第i个取值,
为自变量的第i个取值, 为实际值与估计值误差的平方。
为实际值与估计值误差的平方。
通过极小化(6)式就可以得到各个模型的权重,即 。将
。将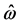 带入(5)式就可以得到观测值的Mallow Model Averaging (MMA)估计。
带入(5)式就可以得到观测值的Mallow Model Averaging (MMA)估计。
鉴于S-AIC的计算依靠AIC,因此,本文选择AIC进行模型选择。模型平均与模型选择相比,模型平均避免选到一个较差的模型;模型平均往往是将多个模型赋予权重组合起来,不会丢掉任何模型和遗失任何有用的信息,这样就可以充分利用所有的信息分析、解决问题;模型平均法并没有将建立的模型当作数据产生的真实过程,这样就可以保证估计或预测的准确性。模型平均方法经常被用于经济领域或其它领域做预测。
3.3. Meta-Analysis
针对同一个问题,可能会有很多不同的研究结果,这就需要我们采用一定的方法整合分析所有研究结果,最终得到一个相对统一且被大家认可的结论,即Meta分析(Meta-analysis)。Meta分析是汇总多项原始研究的结果并分析评价其合并效应量的一系列过程,它依靠搜集已发表或未发表的具有某一可比性的文献,应用特定的统计学方法进行合并分析与综合评价[7] 。Meta-analysis又称为“荟萃分析”,是对具备特定条件的、同课题的诸多研究结果进行综合的一类统计方法。Meta-analysis最重要的是文献资料的筛选,因为所选文献直接决定了我们提取的数据情况。Meta分析中,Meta回归模型通常包含以下两类:
第一,固定效应模型
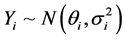 ,
, ,其中
,其中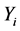 为第i个研究的统计量,期望
为第i个研究的统计量,期望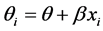 。
。
第二,随机效应模型
若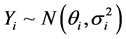 ,
,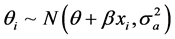 ,则随机效应Meta回归模型为
,则随机效应Meta回归模型为 。
。
我们常常使用Stata软件建立Meta回归模型,命令如:metareglnor factor 1,factor 2,factor 3,…,wsse (selnor);如果考虑交互效应时,命令中将交互项(interaction)添加进去即可。
本节通过Meta分析可以得到很多可能的分析模型,根据3.2中的方法,我们可以得到备选模型集中每个模型所占的权重集合即 ,将这些权重赋给对应的模型,从而将所有可能的模型组合起来最终得到一个组合模型(与模型选择相比,是全模型),然后就可以运用该模型对所要研究的问题进行分析、预测了。接下来就将上面介绍的模型选择与模型平均方法结合Meta分析应用到豆科植物-根瘤菌互利共生合作系统影响因素的实例分析中。
,将这些权重赋给对应的模型,从而将所有可能的模型组合起来最终得到一个组合模型(与模型选择相比,是全模型),然后就可以运用该模型对所要研究的问题进行分析、预测了。接下来就将上面介绍的模型选择与模型平均方法结合Meta分析应用到豆科植物-根瘤菌互利共生合作系统影响因素的实例分析中。
4. 模型选择与模型平均在Meta分析中的应用实例分析
针对同一个问题,可能得到不同甚至相左的研究结果,因此,采用Meta分析可以整合这些不同研究结果提供的信息,最终分析得到一个统一的结果。所以,通过Meta分析方法比使用其他方法得到的研究结果更为客观、全面。基于作者之前采用AIC和AICc准则进行模型选择做过豆科植物–根瘤菌互利共生合作系统的相关研究,而且AICc准则和S-AIC准则都是对AIC修正衍化得到,因此,在本文中,作者通过S-AIC权重选择准则进行模型平均分析,与AIC模型选择进行比较,这具有重要的意义。当然,在未来的研究中,我们可以通过其他模型平均方法(如S-BIC、Mallow准则等)进行研究分析,然后与S-AIC进行比较,这样可以很好的说明这些权重选择准则在模型平均方法中的应用效果。
所以,本文依托Meta分析理论和方法,收集大量豆科植物–根瘤菌互利共生合作系统研究的相关文献,根据文献中提供的二次数据建立Meta回归模型;基于AIC准则考虑模型选择问题;最后基于S-AIC准则研究Meta分析中的模型平均问题,进而据此分析豆科植物–根瘤菌互利共生系统中的影响因素。结果表明模型平均方法不但可以应用于Meta分析中,而且其分析效果优于模型选择。
4.1. 资料来源
本文主要通过Meta分析,建立Meta回归模型,结合模型选择与模型平均法分别研究豆科植物与根瘤菌组成的互利共生合作系统的影响因素。我们在ISI Web of Knowledge Web of Science database和谷歌学术(Google Scholar)上查询国内外学者对豆科植物–根瘤菌互利共生合作系统所做的相关研究,将查询到的文献所提供的一些信息作为Meta分析和Meta回归的实例数据。我们将可能对该合作系统造成影响的已知研究中的五个因素:宿主类型(Host Classification)、合作者类型(Cooperator genus)、施肥与否(Fertilization)、控制措施(Measured effect)和接种复杂度(Design class)分别记作X1、X2、X3、X4、X5。
4.2. 模型选择分析
根据资料提供的数据信息,我们建立Meta回归模型进行分析。除了各个单因素即主效应为可能的影响因素外,各个主效应之间的交互作用也可能对豆科植物–根瘤菌互利共生合作系统产生一定的影响。由于我们不能确定包含哪些解释变量可以得到较好的分析结果,因此,建立Meta回归模型时应将所有的主效应以及交互效应都考虑进去。用Stata软件建立Meta回归模型,探索性的建立很多模型,记录各个模型的F统计量、P值以及方差,经过筛选,最终得到51个模型。简单列举几个模型:
Model1:metareglnorX3X4X1*X4 X1*X5 X3*X4,wsse (selnor);
Model2:metareglnorX3X4X5 X1*X4 X1*X5 X3*X4,wsse (selnor);
Model3:metareglnorX2 X3X4X1*X4 X3*X4,wsse (selnor);
Model4:metareglnorX3X4X1*X4 X1*X5 X3*X4,wsse (selnor);
Model5:metareglnorX3X4X5X1*X4 X3*X4,wsse (selnor);
… … …
Model51:metareglnorX3X4X5X1*X3X1*X4,wsse(selnor)。
通过Matlab软件分别计算这51个模型的极大似然函数,再结合公式(1)计算并记录每个模型的AIC,各个模型的AIC值如表1所示。
观察表1,将所有模型的AIC值进行排序,得到AIC值最小的模型为Model2, 。通过AIC模型选择准则,我们从所有候选模型中选择模型2对豆科植物–根瘤菌互利共生合作系统的影响因素进行分析,认为该模型在所有模型中的分析效果最好。建立模型2的命令为metareglnorX3X4X5 X1*X4 X1*X5 X3*X4,wsse (selnor),由此发现该模型包含主效应X3 (Fertilization)、X4 (Measured effect)以及X5 (Design class),此外还有交互效应X1*X4 (Host Classification* Measured effect)、X1*X5 (Host Classification* Design class)和X3*X4 (Fertilization* Measured effect)。经过模型选择以及由模型2,我们得到影响豆科植物-根瘤菌互利共生系统的主要因素为X3、X4、X5、X1*X4、X1*X5以及X3*X4。
。通过AIC模型选择准则,我们从所有候选模型中选择模型2对豆科植物–根瘤菌互利共生合作系统的影响因素进行分析,认为该模型在所有模型中的分析效果最好。建立模型2的命令为metareglnorX3X4X5 X1*X4 X1*X5 X3*X4,wsse (selnor),由此发现该模型包含主效应X3 (Fertilization)、X4 (Measured effect)以及X5 (Design class),此外还有交互效应X1*X4 (Host Classification* Measured effect)、X1*X5 (Host Classification* Design class)和X3*X4 (Fertilization* Measured effect)。经过模型选择以及由模型2,我们得到影响豆科植物-根瘤菌互利共生系统的主要因素为X3、X4、X5、X1*X4、X1*X5以及X3*X4。
4.3. 模型平均分析
根据4.2得到的51个模型,每个模型含有的变量种类以及个数不同,解释效果也不同,因此,下面通过模型平均整合这些模型提供的信息进行全面分析。根据公式(4)以及4.2计算的AIC值,我们可以分别计算出各个模型所占的S-AIC权重。利用计算出的权重结果将51个模型组合起来,最终得到一个组合分析模型。S-AIC权重结果如表2所示。
通过模型平均,我们最终得到一个包含51个模型的组合模型,每个模型都有一个权重。由表2可知组合模型中权重较大且排在前五的模型有第二、第三、第四、第五和第九个,说明这五个模型在整个组合模型中的所起的解释作用最大。这五个模型的构建命令如下:
Model2:metareglnorX3X4X5 X1*X4 X1*X5 X3*X4,wsse (selnor);
Model3:metareglnorX2 X3X4X1*X4 X3*X4,wsse (selnor);
Model4:metareglnorX3X4X1*X4 X1*X5 X3*X4,wsse (selnor);
Model5:metareglnorX3X4X5X1*X4 X3*X4,wsse (selnor);
Model9:metareglnorX3X4X1*X4 X3*X4,wsse (selnor);

Table 1. Akaike Information Criterion of every model
表1. 每个模型的AIC
Table 2. The weight of Smoothed Akaike Information Criterion
表2. S-AIC权重
从整个组合模型来看,所有模型中包含的可能的解释变量对豆科植物–根瘤菌互利共生合作系统或多或少都有影响,只不过所占权重较大的模型中的解释变量影响作用较大。模型平均结果表明:X2、X3、X4、X5、X1*X4、X3*X4、X1*X5是影响该合作系统的主要因素,其他的如X1、X1*X3、X3*X5、X4*X5等因素也有一定的影响,不过影响力较小而已。
4.4. 模型选择与模型平均法所得结果的比较
一方面,利用AIC准则我们从51个模型中选择了一个最好的模型,得到豆科植物–根瘤菌互利共生系统的主要影响因素有X3、X4、X5、X1*X4、X1*X5以及X3* X4。而通过模型平均方法,使用S-AIC给每个模型赋权重,最后所得全模型,该组合模型包含了51个模型,解释作用低的模型其权重较小,最终得到的影响因素有X2、X3、X4、X5、X1*X4、X3*X4、X1*X5、X1、X1*X3、X3*X5、X4*X5等。与模型选择相比,我们给51个模型都赋予了各自的权重,得到的这样一个组合模型包含了数据提供的所有信息,而且模型平均最后得到的组合模型包含模型选择选出的模型2。因此,我们分析豆科植物-根瘤菌互利共生系统的影响因素,模型平均方法比模型选择更加方便准确,得到的影响因素相对较全面具体。
另一方面,表2的分析结果揭示了模型平均方法不但为我们提供了豆科植物–根瘤菌互利共生系统的影响因素,也具体给出了每个模型中的每个因素对该系统影响的重要性。而模型选择仅仅给出了所选的一个最优模型,从这个模型只能发现哪些因素对共生系统有影响,信息量较小,与模型平均相比,遗失了很多有用信息。
5. 结论
综上所述,基于模型选择与模型平均方法,通过对影响豆科植物-根瘤菌互利共生系统的因素实例进行Meta分析,由分析结果说明模型平均方法不但可以应用于Meta分析中,而且其分析效果优于模型选择。具体结论如下:
(1) 本文基于Meta分析,整合了豆科植物–根瘤菌互利共生系统的相关研究,建立了许多Meta回归模型。基于所建立的Meta回归模型,我们分别采用模型选择和模型平均方法对豆科植物–根瘤菌互利共生系统影响因素的分析模型进行确定。结果表明:模型平均方法得到的组合分析模型,详细的解释了豆科植物–根瘤菌互利共生合作系统的主要影响因素有X2、X3、X4、X5、X1*X4、X3*X4、X1*X5、X1、X1*X3、X3*X5、X4*X5等,此外,根据每个模型所占的权重,发现X4、X3、X1*X4以及X3*X4这四个因素的影响作用最大。而通过模型选择,得到X3、X4、X5、X1*X4、X1*X5以及X3*X4是该合作系统的影响因素。模型选择得到的模型中没出现的变量并不能说明其对合作系统没有影响,模型平均方法弥补了这一缺陷。
(2) 事实上,线性回归中,模型平均方法的分析效果往往优于模型选择,经本文研究发现:模型选择与模型平均方法除了应用于线性回归中之外,也均可应用于Meta分析中,而且模型平均的分析效果优于模型选择,这和线性回归的结论是一致的。因此,未来可将模型平均广泛的应用于统计学以及其他领域。
基金项目
本文得到云南财经大学研究生创新基金项目(2015YUFEYC015)的资助。
文章引用
尹潇潇. 模型选择与模型平均在Meta分析中的应用研究
The Application Research of Model Selection and Model Averaging in Meta-Analysis[J]. 自然科学, 2015, 03(03): 81-88. http://dx.doi.org/10.12677/OJNS.2015.33011
参考文献 (References)
- 1. Johnson, J.B. and Omland, K.S. (2004) Model selection in ecology and evolution. Trends in Ecology & Evolution, 19, 101-108. http://dx.doi.org/10.1016/j.tree.2003.10.013
- 2. 张新雨, 邹国华 (2011) 模型平均方法及其在预测中的应用. 统计研究, 6, 97-102.
- 3. Berry, D., Wathen, J.K. and Newell, M. (2009) Bayesian model averaging in me-ta-analysis: vitamin E supplementation and mortality. Clinical Trials, 6, 28-41. http://dx.doi.org/10.1177/1740774508101279
- 4. Li, Q., Wang, S., Huang, C.C., et al. (2014) Meta-analysis based variable selection for gene expression data. Biometrics, 70, 872-880. http://dx.doi.org/10.1111/biom.12213
- 5. Buckland, S., Burnham, K. and Augustin, N. (1997) Model selection: An integral part of inference. Biometrics, 53, 603-618. http://dx.doi.org/10.2307/2533961
- 6. Hansen, B. (2007) Least squares model averaging. Econometrica, 75, 1175-1189. http://dx.doi.org/10.1111/j.1468-0262.2007.00785.x
- 7. 石修权, 王增珍 (2008) Meta回归与亚组分析在异质性处理中的应用. 中华流行病学杂志, 5, 497-501.