Statistics and Application
Vol.07 No.02(2018), Article ID:24467,10
pages
10.12677/SA.2018.72016
The Implementation of Random Trial of Statistical Distribution in Eviews
Yingzi Cao
International Business College, Shaanxi Normal University, Xi’an Shaanxi

Received: Mar. 27th, 2018; accepted: Apr. 16th, 2018; published: Apr. 23rd, 2018

ABSTRACT
Random simulation is an important way for people to understand the regularity of random phenomena. It has an important application in understanding and studying the distribution characteristics of statistics and estimates. Eviews software provides a platform for people to carry out random simulation. In this paper, a few examples are given to illustrate the strong support of Eviews’s random simulation function to the research of statistics and estimation distribution.
Keywords:Random Simulated, Statistics, Estimators, Eviews
统计分布的随机试验在Eviews中的实现
曹樱子
陕西师范大学国际商学院,陕西 西安
收稿日期:2018年3月27日;录用日期:2018年4月16日;发布日期:2018年4月23日

摘 要
随机模拟是人们认识随机现象中的规律性的一种重要方式,在认识和研究统计量和估计量的分布特征时具有重要应用。Eviews软件为人们进行随机模拟提供了一种平台。本文通过几方面的举例说明了该软件的随机模拟功能对统计量和估计量分布的研究提供的有力支持。
关键词 :随机模拟,统计量,估计量,Eviews

Copyright © 2018 by author and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
人们可以通过反复的观察认识随机现象中的规律性,也可以通过主动的随机试验来认识随机现象中的规律性。它们都需要通过大量的重复进行才能获得对随机现象的认识。在实践中,观察当然是被动的,而随机试验有时费时费力,有时难以进行。随机模拟是人们认识随机现象中的规律性的另外一种重要方式,在研究统计量和估计量的分布特征时具有重要应用。统计量和估计量是统计过程中的重要概念,它们是样本的函数,随着样本的变化而变化,具有一定的分布规律。人们通过解析的推理方法已经得出了很多统计量和估计量的分布特征,还不清楚大量的统计量和估计量的分布特征。
随着统计软件的不断推出,随机模拟可以很容易地进行,给人们认识随机现象提供了工具和手段。随机模拟是一种通过设定随机试验,反复生成样本,计算统计量和估计量,进而研究其分布特征的方法。Eviews软件除了提供各种经济计量分析功能外,还提供了很多随机抽样函数(该软件有数据处理、作图、统计分析、建模分析、预测和模拟等六大类功能),为人们进行随机模拟提供了一种平台。利用Eviews软件的随机模拟功能,反复产生很多组样本,能够探索统计量和估计量的分布规律。
2. Eviews中的随机抽样函数
Eviews中提供了18种随机变量的随机抽样函数,都是以@r开头,加上相应的分布名称,如表1所示(括号中是分布参数) [1] [2] [3] :
运用这些函数就可以从18种随机变量所服从的分布中抽取任意数目的随机样本,进行随机试验或对统计量和估计量的分布特征进行经验研究。下面通过几方面的例子介绍随机试验在Eviews中的实现。

Table 1. Random sampling function in Eviews
表1. Eviews中的随机抽样函数
3. 估计圆周率的随机试验
对于圆周率p,人们提出了很多种估计方法。现在设计一个随机试验来估计p。构造一个单位正方形和内切圆,往正方形里面随机地投点。定义一个随机变量X,如果随机投点落在内切圆内则其值为4,否则其值为0。这样理论上来说X的期望为p。该试验在Eviews软件中实现的代码如下(代码可以在命令行逐条运行) [4] :
wfcreate mywork u 1 10000
'建立工作文件,命名为mywork,范围是1~10000,即模拟10000次
series x=@runif(0,1)
'建立序列x,其值是从均匀分布中随机抽取,10000个,也可用rnd函数得到
series y=@runif(0,1)
scat x y
'查看散点图
genr z=4*((x-0.5)^2+(y-0.5)^2<0.5^2)
'生成新序列z,如果点(x,y)落在圆内,则取值为4,否则取值为0
z.stats
'查看序列z的描述性统计量的值
图1是运行一次的结果。从图1可以看到,这次通过10,000个随机投点对p的估计结果为3.1468。随着样本容量的增大,模拟结果就会越来越接近于p的真值。当然,以上代码也可以编写到程序窗口,通过点击程序窗口的run按钮,重复运行。
4. 对随机变量的函数分布的验证
统计理论指出,如果随机变量X服从标准正态分布,则X2服从卡方分布;如果随机变量Y服从正态分布,则eY服从几何正态分布(或称作对数正态分布)。对于这些结论可以在Eviews软件中加以验证。模拟试验的代码如下:
wfcreatemyfillu11000
series x=@rnorm
'创建序列x,数值随机抽取于N(0,1)
genr x2=x^2
'生成新序列x2,X2=X2
x2.hist
'绘制序列x2的直方图
series y=1+0.5*@rnorm
'创建序列y,数值来自于N(1,0.52)
genr expy=exp(y)
'生成新序列expy,expy=exp(y)
expy.hist
'绘制序列expy的直方图
下面是一次随机模拟的结果(图像经过了冻结、合并):
图2中的左图说明X2服从的是卡方分布,右图说明expy服从的是几何正态分布。通过该验证可以

Figure 1. The distribution of 10,000 random sampling points and estimation of PI
图1. 10,000个随机抽样点的分布及其对圆周率的估计

Figure 2. Empirical relations of normal, chi square and geometric normal distribution
图2. 正态分布和卡方分布、几何正态分布的经验关系
增加对正态分布和卡方分布、几何正态分布之间关系的认识,同时获得对卡方分布、几何正态分布的分布特征的认识。还有其他的分布结论也可以验证,例如t分布、F分布等。
5. 对样本统计量的随机模拟
统计量是统计数据处理中的重要概念,是对样本特征的总结或概括。统计量的分布是通过样本特征推断总体特征的理论基础,研究统计量的分布是统计理论中的一项重要内容。对于像均值这样的统计量所服从的分布,理论上已经有了确定的结果,通过Eviews软件可以进行验证,从而对其特征获得感性的、直观的认识。而对于偏度、峰度这些统计量所服从的分布,理论上还没有确定的结论,通过Eviews软件的随机模拟可以获得一定的经验认识。
5.1. 对样本均值分布的随机模拟
统计理论指出,如果总体服从正态分布,即 ,则容量是n的样本均值也服从正态分布,且 ;如果总体不服从正态分布,当样本容量很大时,样本均值渐近地服从正态分布。现在假定一个总体服从的分布为 ,另一个总体服从参数为3的指数分布。在Eviews中进行随机模拟,
重复抽样1000次,每次200个样本数,观察样本均值的分布。模拟的代码如下(循环语句必须输入到程序窗口,通过命令program打开程序窗口,运行大约2分钟):
wfcreatemyworku11000
for !k=1 to 1000
'定义控制变量!k,建立循环,循环1000次
series x{!k}
'建立序列x{!k}
series y{!k}
smpl 1 200
'调整样本范围到1~200
x{!k}=1+2*@rnorm
y{!k}=@rexp(3)
'序列y{!k}的值来自参数是3的指数分布
scalar xm=@mean(x{!k})
'计算序列x{!k}的样本均值
scalar ym=@mean(y{!k})
smpl 1 1000
'恢复工作文件范围到1~1000
matrix(1000,2)mat
'建立矩阵mat(1000´2)
mat(!k,1)=@mean(x{!k})
'将序列x{!k}的均值存放于矩阵mat第一列中
mat(!k,2)=@mean(y{!k})
next
'循环结束
deletex??x???y??y???
'删除一些序列(?是通配符)
mtos(mat,g)
'将矩阵mat转化为两个序列(默认名称是ser01和ser02)
ser01.hist
'查看序列ser01的直方图
ser02.hist
从图3可以看出,样本均值的均值接近于1,样本均值的标准差接近于 ,并且JB统计量说明不能拒绝样本均值服从于正态分布的原假设。
从图4可以看出,样本均值的均值接近于3,样本均值的标准差接近于 ,同样JB统计量说明也不能拒绝样本均值服从于正态分布的原假设,表明试验结果与理论结论一致。
对于该随机模拟,可以更改模拟次数、样本容量、总体的分布类型等对样本均值的分布特征一一加以验证。
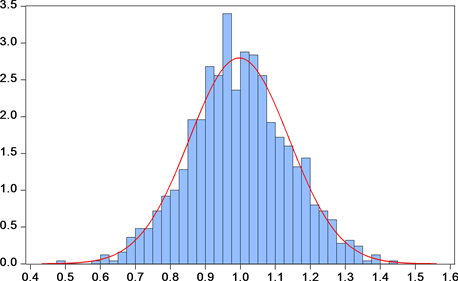
Figure 3. Distribution of sample mean of normal distribution (sample volume is 200)
图3. 正态分布的样本均值的分布(样本容量为200)
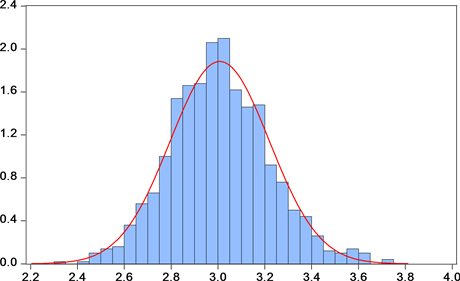
Figure 4. The distribution of sample mean of exponential distribution (sample volume is 200)
图4. 指数分布的样本均值的分布(样本容量为200)
5.2. 对正态分布的样本偏度和峰度分布的随机模拟
统计理论指出,如果总体服从于正态分布,则容量是n的样本偏度和样本峰度渐近地服从均值为0,方差分别为6/n和24/n的正态分布。(检验样本是否来自于正态分布的JB统计量正是在此基础上构造出来的。)该结论的证明比较困难,但是可以通过随机模拟获得直观认识。现在假定一个总体服从的分布为 ,从中重复抽样2000次,每次300个样本数,观察样本偏度和峰度的分布。模拟的代码如下:
wfcreatemyfileu1300
for !k=1 to 2000
series x{!k}
x{!k}=1+2*@rnorm
scalar xs=@skew(x{!k})
'计算序列x{!k}的样本偏度
scalar xk=@kurt(x{!k})
'计算序列x{!k}的样本峰度
matrix(2000,2)mat1
mat1(!k,1)=@skew(x{!k})
mat1(!k,2)=@kurt(x{!k})
next
deletex??x???
range 1 2000
'扩大工作文件范围为1~2000
mtos(mat1,g)
ser01.qqplot
'查看序列ser01的qq图(分位数-分位数图)
ser02.qqplot
下面的图5是一次运行的结果(将两个图像冻结、合并):
从图5可以看出,样本偏度服从正态分布,而样本峰度与正态分布还有一定差距,可以增大样本容量和增加模拟次数来进一步验证。
类似的,还可以通过随机模拟来研究来自于其他分布的各种统计量(比如偏度、峰度、中位数、极小值、极大值等等)的分布特征。
5.3. 对相关系数的分布的模拟
统计理论指出,当两个总体的相关系数r等于0时,样本相关系数r服从于自由度为 ,标准差
为 的t分布。现在从两个独立的标准正态分布中每次抽取500个样本数,重复10,000次来验证该
结论。在Eviews中进行随机模拟的代码如下:
wfcreate xishu u 1 10000
series rxy
for !a=1 to 10000
smpl 1 500
series x=@rnorm
series y=@rnorm
scalar r=@cor(x,y)
'计算样本相关系数r
rxy(!a)=r
'将样本相关系数存放在序列rxy中
next
smpl 1 10000
rxy.hist
rxy.distplot cdf
'查看序列rxy的经验分布函数图
下面的图6是一次运行的结果(将直方图和经验分布函数图冻结、合并)。
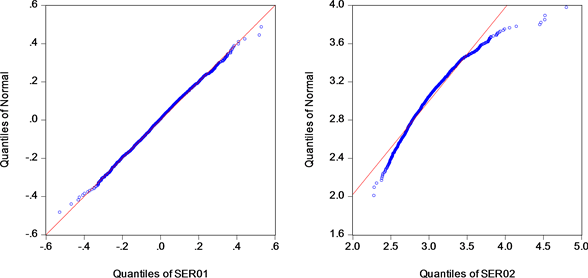
Figure 5. qq diagram of the skewness and kurtosis of random sample (sample volume is 300)
图5. 正态分布随机样本的偏度和峰度的qq图(样本容量为300)

Figure 6. Distribution diagram of sample correlation coefficient (sample volume is 500)
图6. 样本相关系数的分布图(样本容量为500)
从图6左边的直方图可以看出,样本相关系数的分布与t分布一致;右边的经验分布函数图说明样本相关系数的分布与标准正态分布相当接近(样本容量很大)。
当总体相关系数
时,因为
,所以样本相关系数将会是一个有偏的分布。理论上,经过Fisher变换:
,z将渐进地服从均值为
,标准差为
的正态分布。这时获得样本数据的方法是首先生成两个无关的
的随机取值,然后令
,则
的相关系数从理论上来讲为r,通过反复生成 的取值,就可以模拟样本相关系数的分布。
的取值,就可以模拟样本相关系数的分布。
6. 对估计量的随机模拟
经济计量学理论指出,在满足高斯-马尔科夫假定条件下,普通最小二乘估计量是最佳线性无偏估计量。由于在实际中总体模型总是未知的,并且只有一组样本数据,所以该特征难以展示。我们可以指定一个总体模型,然后在Eviews中反复抽样进行模型的估计,由多次得到的估计结果就可以展示参数估计量的无偏性 [5] 。
假定的总体模型为: 。随机模拟的代码如下:
wfcreate my u 1 2000
series x
x(1)=-10
'序列x的第1个值赋值为-10
smpl 2 21
x=x(-1)+1
'序列x的前一个值加1为下一个值
smpl 1 21
for !k=1 to 2000
series y{!k}
y{!k}=2+0.2*x+3*@rnorm
equation eq{!k}.ls y{!k} c x
'建立方程对象,名称为eq{!k},用最小二乘法估计
matrix(2000,3)ma
ma({!k},1)=c(1)
ma({!k},2)=c(2)
ma({!k},3)=@se
'矩阵ma的第三列存放每次估计的标准误
next
smpl 1 2000
mtos(ma,g)
freeze(g1) ser01.hist
'冻结ser01的直方图,名称为g1
freeze(g2) ser02.hist
freeze(g3) ser03.hist
graph graph01.merge g1 g2 g3
'合并三个直方图,名称为graph01
graph01.align(3,1,1)
'将三个直方图横向排列
图7是一次运行的结果。从图7可以看出,参数估计量具有无偏性,并且也服从正态分布。这就展示或者说验证了理论结论。在经济计量学理论中,还有很多类似结论都是对重复样本而言的,通过Eviews软件进行重复抽样就可以直观化这些结论。

Figure 7. The unbiased estimator of the least squares (intercept, slope, and standard error)
图7. 最小二乘法估计量的无偏性(从左到右分别是截距、斜率和标准误差)
7. 结语
在实践中,人们首先是对某些随机现象中的规律性获得经验认识,然后经过理论分析才上升到理性认识。大量的随机现象中的规律性是难以通过这种方式来认识和研究的。随机模拟是人们获得经验认识的一种重要方式。Eviews软件提供了强大的随机模拟功能。本文通过几方面的举例说明了Eviews的随机模拟功能对统计量和估计量分布的研究提供的有力支持。对于统计活动和经济计量活动中的很多随机模拟问题,可以类似地进行研究。
文章引用
曹樱子. 统计分布的随机试验在Eviews中的实现
The Implementation of Random Trial of Statistical Distribution in Eviews[J]. 统计学与应用, 2018, 07(02): 124-133. https://doi.org/10.12677/SA.2018.72016
参考文献
- 1. 陈灯塔. 应用经济计量学——EViews高级讲义[M]. 北京: 北京大学出版社, 2012.
- 2. 高铁梅. 计量经济分析方法与建模: EViews应用及实例[M]. 第2版. 北京: 清华大学出版社, 2009.
- 3. 张晓彤. Eviews使用指南与案例[M]. 北京: 机械工业出版社, 2007.
- 4. 莫达隆. 概率统计中随机模拟实验的设计——兼谈eviews随机数发生器的使用[J]. 福建教育学院学报: 高教, 2012(4): 119-121.
- 5. 王佐仁, 徐生霞. 蒙特卡罗方法下线性模型的异方差性检验方法[J]. 统计与信息论坛, 2016(11): 33-37.