Advances in Applied Mathematics
Vol.
10
No.
07
(
2021
), Article ID:
43772
,
9
pages
10.12677/AAM.2021.107240
一种改进的PSO-SVM算法
郑恩涛,吴思燕,胡志涛,鞠豪
杭州师范大学理学院,浙江 杭州

收稿日期:2021年6月7日;录用日期:2021年6月28日;发布日期:2021年7月9日

摘要
粒子群优化(Particle swarm optimization, PSO)算法在整个训练数据集上搜寻支持向量机(Support vector machine, SVM)最优惩罚参数C和高斯核参数σ时会出现搜寻时间过长的问题。为了解决该问题,我们提出了一种基于距离配对排序(Distance pairing sorting, DPS)支持向量预选取的PSO-SVM算法(DPS- PSO-SVM)。该算法先将训练数据集进行DPS支持向量预选取构造一个支持向量候选集,然后利用PSO算法在支持向量候选集上对SVM参数寻优,最后将最优参数输入到SVM算法中对支持向量候选集进行训练。本文采用UCI数据库中的Breast Cancer数据和Banknote Authentication数据进行数值实验,结果表明该算法既能够缩短参数寻优时间,还能够保持PSO-SVM算法的高分类精度。
关键词
粒子群优化,支持向量预选取,距离配对排序,支持向量候选集,参数寻优
An Improved PSO-SVM Algorithm
Entao Zheng, Siyan Wu, Zhitao Hu, Hao Ju
College of Science, Hangzhou Normal University, Hangzhou Zhejiang

Received: Jun. 7th, 2021; accepted: Jun. 28th, 2021; published: Jul. 9th, 2021

ABSTRACT
In this paper, we introduce an improved PSO-SVM algorithm based on distance pairing sorting support vector preselecting. When particle swarm optimization (PSO) searches the optimal penalty parameter C and kernel function parameter σ of SVM on the whole training data set, the search time will be too long. In order to solve this problem, this paper proposes that the training data set uses distance pairing sorting support vector preselecting to obtain a support vector candidate set, and then the PSO parameter optimization process is put on the support vector candidate set. This can save a lot of parameter optimization time. The Breast Cancer data and Banknote Authentication data in UCI database are used in numerical experiments. The results show that the method can not only reduce the time of PSO parameter optimization, but also get good classification accuracy.
Keywords:Particle Swarm Optimization, Support Vector Preselecting, Distance Pairing Sorting, Support Vector Candidate Set, Parameter Optimization

Copyright © 2021 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
支持向量机(SVM)最早是由Vapnik [1] 在20世纪60年代中期提出。它是一种定义在特征空间上的间隔最大的线性分类器 [2]。通过使用核技巧和软间隔最大化将线性支持向量机推广至非线性支持向量机,所以支持向量机的参数的选择如核函数参数值 和软间隔最大化的惩罚参数值 对支持向量机的推广性能影响很大。如何快速高效搜寻最优支持向量机参数值变成了一个极其重要的问题。粒子群优化算法(PSO)是一种启发式的优化技术,源于对鸟群捕食的行为研究。粒子群优化算法有许多优点:无过多参数调节、简单易于实现、运算速度快、容易和其他技术协作使用 [3]。PSO满足支持向量机参数值寻优的要求,便顺势出现了基于粒子群算法优化支持向量机参数算法(PSO-SVM),PSO-SVM在很多领域内都得到了应用,如经济 [3]、工业 [4] 等方面。为了进一步缩短参数寻优的时间和提高分类预测准确率,近些年来很多学者对PSO-SVM进行了改进。
2006年,Li [5] 提出一种基于PSO算法和模拟退火算法(SA)相结合的SVM算法,实验结果表明该算法相比PSO-SVM和标准的SVM算法有较高预测准确率和更短的训练时间。2011年,Wang [6] 将主成分分析技术(PCA)和PSO算法相结合对SVM进行改进,即先用PCA对训练数据进行降维,然后在降维后的训练数据集上使用PSO算法对SVM参数进行寻优,研究结果显示该方法能够提高SVM的预测准确率。2011年,Wu [7] 针对SVM参数寻优过程中PSO收敛速度慢的问题,提出将Gauss变异算子和Cauchy变异算子相结合的混合变异策略,实验结果表明基于Gauss变异和Cauchy变异的混合变异策略的粒子群优化算法是可行和有效的,且优于标准的PSO算法。2014年,李平 [8] 提出将核主成分分析(KPCA)与PSO- SVM相结合的方法,实验结果表明该方法相比PCA和PSO-SVM相结合的方法分类效果更好,时效性更强。2015年,Firas [9] 将遗传算法(GA)和PSO算法与支持向量机相结合构成一个新的模型(GA-PSO- SVM),该混合模型较标准SVM算法具有较高的预测精度,而基于PCA的GA-PSO-SVM分类预测准确度更高。2018年,吴开兴 [10] 提出一种基于快速主成分分析法(FPCA)的PSO-SVM分类算法,实验结果表明该方法较标准的SVM分类算法分类预测准确率有所提高。2019年,Alaa [11] 提出采用量子行为粒子群算法(QPSO)对SVM的参数进行优化的模型(QPSO-SVM),与标准PSO算法、遗传算法(GA)和网格搜索法(GS)等几种优化算法相比较,分类错误率下降很多。
本文提出了一种基于距离配对排序支持向量预选取的PSO-SVM算法。由于PSO搜寻最优参数值时是在整个训练数据集上进行迭代优化,计算量大,优化时间很长,所以该算法将整个训练数据集先进行支持向量预选取得到一个支持向量候选集,然后利用PSO算法在支持向量候选集上对SVM的参数值 和 进行寻优并构建支持向量机模型,这样可以减少计算量从而缩短训练时间;又因为训练数据中的支持向量对于分类超平面的确定起着决定性作用,所以该算法还可以保持良好的分类预测准确率。
本文接下来第一节介绍基于距离配对排序的支持向量预选取算法(Support vectors preselecting based on distance pairing sorting, DPS)。第二节介绍粒子群算法、基于粒子群算法优化支持向量机参数算法和基于距离配对排序支持向量预选取的PSO-SVM算法。第三节是与本文提出算法相关的仿真数值实验及结果比较。
2. 基于距离配对排序的支持向量预选取算法
2.1. 支持向量机
设训练样本集 ,其中 , 表示原始输
入空间,支持向量机的基本思想是构造一个最大化两类样本间隔的分类超平面,可以转化为求解一个凸二次规划问题,如式(1)所示,
(1)
其中 是为了解决近似线性可分问题而引入的惩罚因子, 是拉格朗日乘子, 是核函数。高斯核函数是一种常用的核函数,其表达式如式(2)所示,
(2)
其中 为核参数。通过求解式(1)得到最优解 ,从而构成分类决策函数
(3)
分类决策函数每一个 对应一个训练样本 ,而 对应的那些样本就被称为支持向量。从支持向量机整个模型的构建当中会发现搜寻最优的参数值 和 是至关重要的,另外从中还可以看出支持向量对于分类决策函数的确定起着决定性作用,所以对训练数据集先进行支持向量预选取,然后在支持向量候选集上进行参数寻优构建支持向量机模型是现实可行的。下面2.2节将介绍一种支持向量预选取算法–基于距离配对排序的支持向量预选取算法。
2.2. 基于距离配对排序的支持向量预选取算法
通常支持向量只占训练样本的一小部分,从几何的角度来看支持向量主要分布在靠近分类超平面的两类样本集边界上 [12],即彼此之间靠的很近的两类样本很有可能成为支持向量。因此本文介绍一种支持向量预选取方法,即基于距离配对排序(DPS)的支持向量预选取算法 [13]。
DPS算法的基本思想是:分别从两类样本中任意挑选一个样本,计算其距离,直至遍历所有样本后将所得的所有距离按照从小到大的顺序进行排序,排序过程中距离对应的样本点不能重复,构造出按距离从小到大排列的样本对序列,然后按一定比例选取排在前面的样本对所关联的样本作为候选支持向量构成支持向量候选集。
如果已知样本线性可分,则样本之间的距离可以用欧氏距离计算;当样本非线性可分时,引进核函数 使原始空间中非线性可分样本映射到高维特征空间中变得线性可分,此时两个样本 和 之间的距离为:
(4)
下面是基于距离配对排序的支持向量预选取算法的具体描述。
算法1 (基于距离配对排序的支持向量预选取算法)
输入:训练样本集 ,其中 ,选取比率 ;
输出:支持向量候选集 。
1) 将训练数据集按类别分成两类,即 和 ;其中, 且 ;
2) 计算两类样本之间的距离矩阵 ,
;
3) 把距离矩阵 中的元素 按照从小到大的顺序进行排序,排序过程中元素关联样本
点不能重复使用,即排在前面的距离 所关联的样本点不参与后续的排序,与该样本点有关的所有距离数值都被删除。按照此方法排序构造出的序列有 个元素,即关联 对样本点;
4) 选取在序列中占比率为 的前 个元素关联的样本构建支持向量候选集 ,其中 , 个元素关联 个样本,即支持向量候选集 包含 个样本。
图1和图2分别是DPS支持向量预选取算法在线性情况和非线性情况下的效果图 [13]。
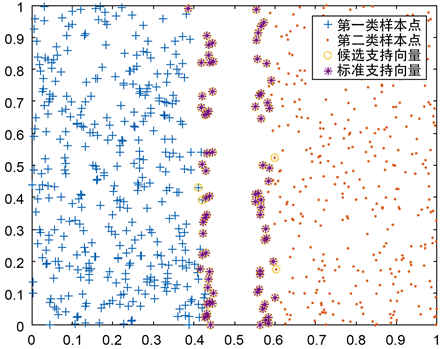
Figure 1. DPS support vector preselecting in linear case
图1. 线性情况下DPS支持向量预选取算法效果图

Figure 2. DPS support vector preselecting in nonlinear case
图2. 非线性情况下DPS支持向量预选取算法效果图
观察图1和图2知,DPS支持向量预选取算法无论是在线性情况下还是非线性情况下都能够有效提取训练数据集中大部分的支持向量,如果将粒子群优化算法在支持向量候选集上进行SVM参数寻优,将避免所有训练样本参与训练,使得参数优化过程的计算量变小,参数优化时间变少。
3. 基于距离配对排序支持向量预选取的PSO-SVM算法
构建支持向量机分类预测模型时,在合适地选择核函数的基础上 [14],对核参数 和惩罚参数 的选择是十分重要的。在很多情况下,为了某一个应用问题选择最优参数需要经过大量的尝试和失败,而粒子群优化算法的出现为SVM参数优化带来了曙光,两者的结合不但能够得到最优的SVM参数,而且使得支持向量机的应用得到了很大的推广。
3.1. 粒子群优化算法
粒子群算法是一种高效的启发式优化技术 [15],它是通过群体中个体之间的协作和信息共享来寻找优化问题的最优解。在求解优化问题中,粒子群算法设计了一种无质量的粒子,粒子只有两个属性:速度和位置。在优化迭代过程中,通过对每个粒子当前位置的性能比较得出全局的最优位置。每个粒子根据自身当前的位置和当前全局最优位置动态地调整自己下一次迭代的速度和位置,直至寻得最优解或超过最大迭代次数后截止。
标准PSO算法中的每个粒子调整移动位置和速度的公式 [16],如式(5)和式(6)所示,
(5)
(6)
其中 为迭代次数, 为惯性因子, 和 是取值为正数的学习因子, 和 是介于 之间的随机数, 和 分别代表第 个粒子在第 次迭代和第 次迭代时移动的速度, 和 分别代表第 个粒子在第 次迭代和第 次迭代时的位置, 代表整个粒子群在第 次迭代时的最优位置。
实际上,每个粒子在优化问题中都是一个潜在解,粒子适应度可以作为评价这些解好坏的标准。通常将支持向量机的分类预测准确率作为粒子适应度。
3.2. 基于粒子群算法优化支持向量机参数算法
利用粒子群算法优化支持向量机参数算法的流程如图3所示。

Figure 3. The flow chart of support vector machine parameter optimization algorithm based on particle swarm optimization
图3. 基于粒子群算法优化支持向量机参数算法流程图
3.3. 基于距离配对排序支持向量预选取的PSO-SVM算法
基于距离配对排序支持向量预选取改进PSO-SVM的算法基本思想是: 首先采用距离配对排序支持向量预选取算法(DPS)对训练数据集进行支持向量预选取得到一个支持向量候选集,然后在支持向量候选集上利用粒子群算法迭代优化支持向量机惩罚参数值 和核参数值 ,直至得到最优SVM参数值以及对应的最优支持向量机模型,最后将测试数据集输入最优支持向量机模型中进行预测得到测试结果。基于支持向量预选取改进PSO-SVM流程如图4所示。

Figure 4. The flow chart of improved PSO-SVM algorithm based on support vector preselecting
图4. 基于距离配对排序支持向量预选取的PSO-SVM算法流程图
4. 实验结果及比较
为了验证基于支持向量预选取改进PSO-SVM的可行性和有效性,本文将该改进方法与标准的SVM算法和PSO-SVM算法进行数值实验并对数值结果进行比较分析。实验使用Matlab R2018a,在2.3 GHz,Pentium,Dual CPU,4GB内存的硬件平台上运行。数值实验数据采用UCI数据库 [17] 中的Banknote Authentication 数据和Breast Cancer Wisconsin (Original)数据。Banknote Authentication数据有4个特征属性和1个类别属性,共1372个样本,从中选取1370个样本进行5重交叉实验,每组有274个样本,总共有5组,每一重交叉实验选取5组中的1组作为测试数据集,剩下的4组作为训练数据集。Breast Cancer Wisconsin (Original)数据有9个特征属性和1个类别属性,共683个样本,从中选取680个样本也进行5重交叉实验,每组有136个样本,共有5组,每一重交叉实验选取5组中的1组作为测试数据集,剩下的4组作为训练数据集。最后得到的各项分类预测结果是5重交叉实验预测结果的平均值。
在整个数值实验当中,支持向量机都全部采用高斯核函数,SVM惩罚参数值C的取值范围是[0.1,100],核参数值 的取值范围是[0.01,1000]。PSO-SVM有关参数设置如下:粒子维度d = 2,粒子总数m = 20,学习因子c1 = 1.5和c2 = 1.7,惯性因子W = 0.8,最大优化迭代次数tmax = 200,目标粒子适应度为0.001。基于支持向量预选取改进PSO-SVM的实验过程中,支持向量预选取方法采用2.2节介绍的基于距离配对排序的支持向量预选取算法,样本距离采用非线性距离式(4),其中核函数也采用高斯核函数,样本对选取比率 = 0.2,基于距离配对排序支持向量预选取改进PSO-SVM用DPS-PSO-SVM来表示。

Table 1. Data testing
表1. 数据实验
数据测试的结果如表1所示。在表格内,DN表示数据名称,AN表示算法名称,TRD表示输入的训练数据量,TED表示输入的测试数据量,C表示SVM的惩罚参数值, 表示SVM的核参数值,CPA表示分类预测准确率,TIME表示参数优化时间,其中DPS-PSO-SVM的参数优化时间包含DPS支持向量预选取的时间。
通过观察表1可以得到以下观点:
1) 从Banknote Authentication数据的实验结果来看,标准SVM算法经随意设置的参数C和 的分类预测准确率为91.02%,PSO-SVM算法的分类预测准确率是100%,本文提出的DPS-PSO-SVM算法的分类预测准确率为99.85%。PSO-SVM算法的分类预测准确率比标准SVM高8.98%,DPS-PSO-SVM也比标准SVM高8.83%,但PSO-SVM和DPS-PSO-SVM两者的分类预测准确率几乎一致。从实验结果还可以看出,PSO-SVM参数优化的时间平均是931.82 s,而DPS-PSO-SVM参数优化的时间平均只有40.81 s,DPS-PSO-SVM参数优化的时间比PSO-SVM要低很多,只占其4.38%。
2) 观察Breast Cancer Wisconsin数据实验结果可以得出,随意设置惩罚参数值C和核参数值 的标准SVM分类预测准确率平均为65.29%,PSO-SVM的分类预测准确率平均是96.03%,本文提出的DPS-PSO-SVM的分类预测准确率平均为96.32%,标准SVM的分类预测准确率比PSO-SVM要低30.74%,比DPS-PSO-SVM的要低31.03%,但PSO-SVM分类预测准确率和DPS-PSO-SVM的相差不大。在参数优化时间方面,PSO-SVM的参数优化时间平均为193.26 s,而DPS-PSO-SVM的参数优化时间平均只有11.92 s,DPS-PSO-SVM的参数优化时间只占PSO-SVM的6.17%。
综合上述结果分析得出三个结论。第一,SVM参数C和 的确对SVM的分类预测准确率存在很大影响;第二,利用粒子群算法优化SVM参数可以起到提高SVM分类预测准确率的效果;第三,本文提出的基于距离配对排序支持向量预选取改进PSO-SVM算法可以在不影响PSO-SVM分类预测准确率的情况下,大量缩短PSO-SVM参数优化时间。
5. 总结
为了解决PSO-SVM参数优化时间过长的问题,本文根据训练数据中支持向量分布的几何特征,提出了一种基于距离配对排序支持向量预选取改进PSO-SVM的算法(DPS-PSO-SVM)。我们采用UCI数据中的Breast Cancer数据和Banknote Authentication数据进行5重交叉数值实验,数值实验结果表明DPS- PSO-SVM算法能够缩短大量的参数优化时间,而且还保持了PSO-SVM算法的较高分类预测准确率。DPS-PSO-SVM算法的提出加快了参数优化的学习速度,从而进一步提高了SVM的广泛使用性能。
文章引用
郑恩涛,吴思燕,胡志涛,鞠 豪. 一种改进的PSO-SVM算法
An Improved PSO-SVM Algorithm[J]. 应用数学进展, 2021, 10(07): 2305-2313. https://doi.org/10.12677/AAM.2021.107240
参考文献
- 1. Vapnik, V. (1998) Statistical Learning Theory. Vol. 3, Wiley, New York, 401-492.
- 2. 李航. 统计学习方法[M]. 北京: 清华大学出版社, 2012: 95-135.
- 3. 杨钟瑾. 粒子群和遗传算法优化支持向量机的破产预测[J]. 计算机工程与应用, 2013, 49(18): 265-270.
- 4. Refan, M.H., Dameshghi, A. and Kamarzarrin, M. (2014) Improving RTDGPS Accuracy Using Hybrid PSOSVM Prediction Model. Aerospace Science and Technology, 37, 55-69. https://doi.org/10.1016/j.ast.2014.04.015
- 5. Li, X., Yang, S.-D. and Qi, J.-X. (2006) A New Support Vector Machine Optimized by Improved Particle Swarm Optimization and Its Application. Journal of Central South University of Technology, 13, 568-572. https://doi.org/10.1007/s11771-006-0089-2
- 6. Wang, H., Zhang, G., E, M.J. and Sun, N. (2011) A Novel Intrusion Detection Method Based on Improved SVM by Combining CPA and PSO. Wuhan University Journal of Natural Sciences, 16, Article No. 409.
- 7. Wu, Q. and Law, R. (2011) Cauchy Mutation Based on Objective Variable of Gaussian Particle Swarm Optimization for Parameters Selection of SVM. Expert Systems with Application, 38, 6405-6411. https://doi.org/10.1016/j.eswa.2010.08.069
- 8. 李平, 李学军, 蒋玲莉, 曹宇翔. 基于KPCA和PSOSVM的异步电机故障诊断[J]. 振动、测试与诊断, 2014, 34(4): 616-620.
- 9. Al Omari, F. and Liu, G. (2015) Novel Hybrid Soft Computing Pattern Recognition System SVM-GAPSO for Classification of Eight Different Hand Motions. Optik, 126, 4757-4762. https://doi.org/10.1016/j.ijleo.2015.08.170
- 10. 吴开兴, 范亭亭, 李丽宏, 张琳. 基于FPCA和PSOSVM回收塑料瓶分类[J]. 计算机工程与设计, 2018, 39(11): 3555-3558+3575.
- 11. Tharwat, A. and Hassanien, A.E. (2019) Quantum-Behaved Particle Swarm Optimization for Parameter Optimization of Support Vector Machine. Journal of Classification, 36, 576-598. https://doi.org/10.1007/s00357-018-9299-1
- 12. Zhang, L. (2008) Support Vectors Pre-extracting for Support Vector Machine Based on K Nearest Neighbour Method. Proceedings of 2008 IEEE International Conference on Information and Automation, Changsha, 20-23 June 2008, 1353-1358. https://doi.org/10.1109/ICINFA.2008.4608212
- 13. 韩成志, 郑恩涛, 马国春. 基于距离配对排序的支持向量预选取算法[J]. 应用数学进展, 2020, 9(2): 195-203.
- 14. Schoelkopf, B. and Smola, A. (2002) Learning with Kernels. The MIT Press, Cambridge, MA.
- 15. Jiao, L., Li, Y., Gong, M. and Zhang, X. (2008) Quantum-in-Spired Immune Clonal Algorithm for Global Optimization. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 38, 1234-1253. https://doi.org/10.1109/TSMCB.2008.927271
- 16. Farid, M. and Yakoub, B. (2008) Classification of Electrocardiogram Signals with Support Vector Machines and Particle Swarm Optimization. IEEE Transactions on Information Technology in Biomedicine, 12, 667-677. https://doi.org/10.1109/TITB.2008.923147
- 17. http://archive.ics.uci.edu/ml/datasets.php