Computer Science and Application
Vol.
10
No.
01
(
2020
), Article ID:
33890
,
9
pages
10.12677/CSA.2020.101007
A Web Page Cleaning Method Based on Template and SVM
Jincheng Yan, Yunfeng Wang*
Department of Computer Science and Technology, Sichuan University, Chengdu Sichuan

Received: Dec. 20th, 2019; accepted: Jan. 2nd, 2020; published: Jan. 9th, 2020

ABSTRACT
This paper presents a method of web page denoising based on template and support vector machine (SVM). This method divides web page noise into common noise and personalized noise. Firstly, a template library from the web page collection is established, and the common noise of web page will be removed by using the template. And then, the features for block-level labels are calculated, with which the SVM model is trained. Finally, the trained SVM model is used to divide block-level labels into noise and main text, achieving the purpose of denoising. This method can effectively remove the copyright, navigation, advertising and other noise information in the web page. Compared with the pure use of SVM for web page denoising, both accuracy and recall rate of this method were improved.
Keywords:Web Page Clean, Template, SVM

基于模板和SVM协同工作的网页去噪方法
严金承,王运锋*
四川大学计算机学院,四川 成都

收稿日期:2019年12月20日;录用日期:2020年1月2日;发布日期:2020年1月9日

摘 要
本文提出一种基于模板和支持向量机(SVM)协同工作的网页去噪方法。该方法将网页噪声分为公共噪声和个性化噪声两类。首先从网页集合中建立模板库,利用模板去除网页公共噪声。对于剩下的个性化噪声,先计算块级标签特征,利用这些特征训练SVM模型,最后用训练好的SVM模型将块级标签分为噪声和正文两类,达到去噪目的。该方法能够有效去除主题型网页中的版权、导航、广告等噪声信息。与单纯使用SVM进行网页去噪相比,查准率和查全率上均有提升。
关键词 :网页去噪,模板,SVM

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
Web网页蕴含着大量有价值的信息,已成为搜索引擎、舆情分析、问答系统等文本分析领域的天然数据矿场,但Web网页中同时掺杂着与正文内容无关的信息,例如:网页版权信息、广告、导航栏等。如何抽取网页正文内容,去除上述“网页噪声”,有着重要的研究意义。目前,网页去噪的方法主要包括:基于规则的方法、基于模板的方法、基于视觉信息的方法和基于机器学习的方法。基于规则的方法需要人工分析网页,手工构建规则,应用受限。基于模板的方法过于呆板,拓展性差。基于视觉信息的方法对现在以DIV + CSS为主流布局的网页不太适用且效率低下。基于机器学习的方法依赖于所选取的样本特征,对于短文本噪声识别度低。本文分析了网页噪声规律,将网页噪声分为公共噪声和个性化噪声。由于公共噪声内容固定且文本较短,利用模板法先行对公共噪声去噪,效率高、识别准,能弥补SVM对包含短文本噪声的标签块识别不准的问题。同时,利用SVM对个性化噪声去噪提高了模板法去噪的拓展性。
2. 研究现状
文献 [1] 综述了网页去噪方法,从模型数量的角度,将网页去噪分为多模型网页去噪和单模型网页去噪两类。文献 [2] 主要通过启发式规则去噪,将文档斜率曲线中的“高地”部分确定为正文内容。文献 [3] 单纯利用模板的方法,首先得到一个文本字符流,选择大小为W的窗口在字符流上滑动,每次滑动结果称为一个Shingle,通过计算Shingle集中不同Shingle的频率来确定模板,最后通过模板筛选噪声,剩下的内容即为正文内容。文献 [4] [5] [6] 基于视觉特征对网页去噪,提出了经典算法VIPS,文献 [7] 对VIPS进行了改进,利用样式特性对样式树进行权重标注,提取正文内容。文献 [8] - [15] 主要利用了机器学习的方法,将网页去噪问题当作分类问题处理,特别是文献 [12] 的方法,利用支持向量机对网页去噪,取得了较好的效果。
本文提出的基于模板和SVM协同工作的网页去噪方法,结合模板法和支持向量机对网页去噪的优点,有以下优势:
1) 为每个网站建立模板库,对该网站的公共噪声,诸如:版权信息,部分导航信息去噪,有较精准的去噪能力。
2) SVM对网站的个性化噪声,诸如:广告等去噪,有较好的适应性,弥补了模板法去噪呆板,不灵活的缺点。
3. 网页数据准备
本文预先爬取了各大主流新闻网站网页共3000篇,网页量分布如表1:

Table 1. Web page volume distribution
表1. 网页量分布
4. 建立模板库
本文将网页噪声分成公共噪声和个性化噪声两类。来自同一网站的不同网页通常有着一些共同信息,比如网站版权信息,此外,由于现代网页通常基于一套样式模板来开发,以保持网站的风格性和美观性,所以这些共同信息还包括统一风格的导航栏,保持网页结构的模板化信息等,这部分噪声称为公共噪声,其他噪声称为个性化噪声,如图1。其中,红框中内容为公共噪声,绿框中内容为个性化噪声,黑框中内容为正文。由于公共噪声内容固定,利用模板法直接进行比对能精准快速的对其进行识别。

Figure 1. Category of web page noise
图1. 网页噪声分类
通过URL前缀可识别网页的所属网站。下面为网站X建立模板库:
1) 初始化已处理网下标i = 1,每批次处理计数count = 1。初始化标签集合S为空集,S中的标签记为Sk(k = 1, 2, 3, …),该标签的频次记为Fk。
2) 处理该网站下的第i个网页Xi(i = 1, 2, 3, …)。将网页Xi的标签记为XiTj(j = 1,2,3,…,m)。设定j = 1。对于XiTj,依次与S中的所有标签比较,查看是否有标签名相同,内容相近的标签。若存在标签Sn与XiTj标签名相同,内容相近,则Fn++,否则将XiTj加入S。j+ = 1,直到处理完Xi的所有标签。
3) 处理完Xi后,判断count是否达到阈值N1。若没有达到,则Xi+ = 1,count+ = 1。返回步骤2,处理下一个网页。否则进入步骤4。
4) 查看S中所有标签的频次Fk,若Fk达到阈值N2,则将其对应的标签Sk持久化为模板,同时置count = 1,清空缓存集S,返回步骤2,进入下一批次的网页处理,直到处理完在该网站下爬取的所有网页。
例如,网站X中可能的两篇网页的部分HTML代码如图2。处理完后,缓存集中的结果如表2:

Figure 2. A part of web page code
图2. 某网页部分代码
Table 2. Labels in cache S
表2. 缓存集S中的标签
N1、N2、判断文本内容相近算法的选取对模板库质量有重要的影响。N1过小,统计后,公共噪声标签频次与正文内容标签频次差别将会很近,导致没有合适的N2值对二者进行区分,无法识别出公共噪声。N1过大将大大增加算法的计算量,导致性能降低。
缓存集大小与正文内容和公共噪声的频次关系如图3,可以看出正文内容和个性化噪声在频次统计中不会高于3,故在N1适中的情况下,比如取到10,将N2设置为3可很好的区分公共噪声。
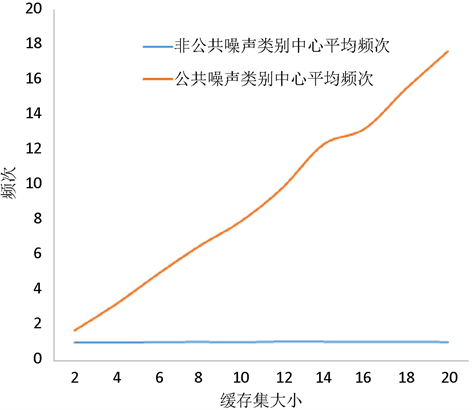
Figure 3. Cache set size-category center diagram
图3. 缓存集大小-类别中心关系图
对于文本内容相近的判断,可借用编辑距离算法 [13]。为保证模板库中模板的准确性,本文采用较为严格的策略,以两文本中文本长度较短的文本作参照,对于文本长度不超过8的文本,可将编辑距离设定为0,即文本必须相同,才判断为相近。对于文本长度超过8的文本,每超过8个字,可增加一个编辑距离。若用D表示文本TA和文本TB的编辑距离,即:D ≤ (Min(Len(TA),Len(TB)))/8时,可判断为TA、TB相近。其中,Len()表示获取文本长度的函数。
5. 标签特征化
将网页去噪问题当作分类问题,即要利用SVM分类器将每个标签及其内容分为噪声和非噪声两类。经统计,噪声内容和非噪声内容一般聚集在某块级标签内,故本文以块级标签为单位计算标签特征。网页中块级标签主要包括:body标签、section标签、div标签。在计算特征时,要去掉嵌套在块级标签的其他块级标签内容。例如,对于如2中所述网页,在计算body标签的特征时,要抛开其中嵌套的div标签。下面介绍各特征属性及计算方法。
5.1. 特征计算方法
1) 外部文本长度比率。外部文本长度比率R1是块级标签内所有文本长度innerLen和整个HTML页所有文本长度outerLen的比值,统计发现,包含正文内容的块级标签内所有文本长度占全文所有文本长度的比重一般较大,故标签R1特征往往较大。
2) 链接文本长度比率。链接文本长度比率R2是块级标签内所有链接文本长度innerLinkLen和整个HTML页所有链接文本长度outerLinkLen的比值,统计发现,包含正文内容的块级标签所有链接文本长度占全文所有链接文本长度的比重一般较小,故标签R2特征往往较小。
3) 链接标签数量比率。链接标签数量比率R3是块级标签内a标签数量innerLinkNum和整个HTML页a标签数量outerLinkNum的比值,统计发现,包含正文内容的块级标签内a标签数量占全文a标签数量比重一般较小,故标签R3特征往往较小。
4) 图片标签数量比率。图片标签数量比率R4是块级标签内img标签数量innerPicNum和整个HTML页img标签数量outerPicNum的比值,统计发现,包含正文内容的块级标签内img标签数量占全文img标签数量比重一般较小,故标签R4特征往往较小。
5) 内部文本长度比率。内部文本长度比率R5是块级标签内链接文本长度innerLinkLen和块级标签内所有文本长度innerLen的比值,统计发现,包含正文内容的块级标签内链接文本长度占块级标签内所有文本长度比重一般较小,故标签R5特性往往较小
5.2. 数据平滑化
计算上述标签特征时,可能遇到分母为0的情况。为简单起见,本文引用自然语言处理领域的加法平滑方法 [16],在计算上述标签特征时,分母统一加上1。该方法对最终的计算结构影响不大,又避免了除0情况的发生。平滑后各特征计算公式如下:
5.3. 特征计算示例
以图2中网页1所示代码为例,计算各块级标签统计量和特征,其结果如表3和表4。
Table 3. Statistics of block label
表3. 各块级标签统计量
Table 4. Features of block label
表4. 各块级标签特征
注:总计结果略小于1的原因由数据平滑造成。
6. 数据训练及模型生成
1) 数据标注。对第1章爬取的所有网页进行特征计算后,采用人工标注的方式,标注其块级标签中的内容是否为正文内容。
2) 保证正负样本均衡。一般来说,某网页正文内容块级标签较少,噪声块级标签较多。故爬取得到的噪声样本将远远多于正文样本。在训练前对噪声样本进行抽样,保证正负样本数量均衡。
3) 确定SVM核函数 [17],由于训练样本中特征数量较少,故采用径向基核函数将样本映射到更高纬空间,可以取得更好效果。
4) 确定模型参数。采用10折交叉验证法进行训练,确定最终模型参数,保证参数较优。
7. 协同去噪方法
该方法分为两阶段对网页进行去噪,具体步骤为:
1) 通过网页的URL前缀找到对应网站模板库。
2) 遍历待去噪网页的所有标签,若该标签与模板库中某标签的标签名相同,且文本内容相近。则认为该标签所含内容为公共噪声,将这些标签删除,即除去了公共噪声。内容相近的判断方法与第3章所描述的方法一样。
3) 经过步骤1后,按第4章的方法计算网页剩余的块级标签特征,送入训练好的SVM模型进行识别。包含噪声的块级标签标记为0,包含正文内容的块级标签标记为1。
4) 保留标记为1的块级标签,将其所包含的内容提取出来,去噪完成。
8. 实验结果与分析
8.1. 评价指标
以叶子标签为单位,对协同方法去噪结果采用查准率和查全率 [18] 进行评价。由于SVM模型对块级标签进行分类,故将块级标签下的叶子标签分类结果设为该块级标签分类结果。下面通过混合矩阵介绍这两种评价指标,如表5:
Table 5. The mixed matrix
表5. 混合矩阵示意
根据上述混合矩阵,查准率P和查全率R的计算方式如下:
(1)
(2)
8.2. 实验结果
根据上述评价指标,本文采用第6章介绍的方法对爬取的3000篇网页进行去噪,其结果如表6:
Table 6. The result of de-noising
表6. 协同方法去噪结果
为说明协同去噪方法对去噪效果的提升,本文与文献 [15] 的方法进行了对比实验,实验结果如表7:
Table 7. The result of comparing
表7. 对比实验结果
8.3. 实验分析
从实验结果来看,本文方法在查准率和查全率都有较好的表现。对于搜狐新闻,查准率略低,是因为爬取的网页中有较多的链接型网页和图片型网页,所以本文方法对于主题型网页有较好的效果,而对图片型和链接型网页表现略差。与文献 [12] 方法的对比实验中,本文方法在查全率上有明显提升,是因为文献 [12] 需要对正文信息定位,一是可能发生定位错误,二是有少许正文信息存在于主要div标签之外。其次,查准率的略微提升得益于模板法对固定短小的公共噪声识别有较高的准确性,弥补了单纯使用SVM不能较好的识别短文本噪声的不足。
9. 结束语
本文提出了模板与SVM协同工作的网页去噪方法,利用事先建立好的模板库识别网页中的公共噪声信息,再通过SVM模型对网页中个性化噪声进行识别。实验表明,该方法整体效果较好。但是本文在训练SVM模型时,计算的标签特征量较少,没有结合文本内容的语义信息进行考虑。其次,SVM模型识别阶段是以块级标签为单位,对于块级标签中正文内容和噪声信息混合的情况,无法将二者分开,后续将对这些内容继续研究。
基金项目
成都市科技计划项目资助(2019-RK00-00015-ZF)。
文章引用
严金承,王运锋. 基于模板和SVM协同工作的网页去噪方法
A Web Page Cleaning Method Based on Template and SVM[J]. 计算机科学与应用, 2020, 10(01): 51-59. https://doi.org/10.12677/CSA.2020.101007
参考文献
- 1. 毛先领, 何靖, 闫宏飞. 网页去噪: 研究综述[J]. 计算机研究与发展, 2010, 47(12): 2025-2036.
- 2. Finn, A., Kushmeric, N. and Smyth, B. (2001) Fact or Fiction: Content Classification for Digital Libraries. Proceedings of the 2nd DELOS Network of Excellence Workshop on Personalization and Recommender Systems in Digital Libraries, Dublin, Ireland, 1-6.
- 3. Gibson, D., Punera, K. and Tomkins, A. (2005) The Volume and Evolution of Web Page Templates. In: Proceedings of the 14th International Conference on Word Wide Web, ACM, New York, 830-839. https://doi.org/10.1145/1062745.1062763
- 4. Cai, D., Yu, S., Wen, J.R. and Ma, W.-Y. (2003) Extracting Content Structure for Web Pages Based on Visual Representation. In: Zhou, X., Orlowska, M.E. and Zhang, Y., Eds., Web Technologies and Applications. APWeb 2003. Lecture Notes in Computer Science, Springer, Berlin, Heidelberg, 406-417. https://doi.org/10.1007/3-540-36901-5_42
- 5. Cai, D., Yu, S., Wen, J.R. and Ma, W.-Y. (2003) VIPS: A Vi-sion-Based Page Segmentation Algorithm. Microsoft Research.
- 6. Debnath, S., Mitra, P., Pal, N. and Giles, C.L. (2005) Automatic Identification of Informative Sections of Web Pages. IEEE Transactions on Knowledge and Data En-gineering, 17, 1233-1246. https://doi.org/10.1109/TKDE.2005.138
- 7. 王健, 张金. 基于节点权重的网页去噪方法的研究[J]. 计算机技术与发展, 2017, 27(10): 83-86.
- 8. 伊政, 徐武平, 徐爱萍. 一种基于结构分析的网页主题区域发现方法[J]. 计算机工程与应用, 2015, 51(6): 227-230+259.
- 9. 郗家贞, 郭岩, 黎强, 等. 一种短正文网页的正文自动化抽取方法[J]. 中文信息学报, 2016, 30(1): 8-15.
- 10. 周艳平, 李金鹏, 宋群豹. 一种基于SVM及文本密度特征的网页信息提取方法[J]. 计算机应用与软件, 2019, 36(10): 251-255+261.
- 11. 李桐宇, 任锐, 蔡鸿明, 等. 基于文本对象模型的自动化网页内容提取方法[J]. 上海交通大学学报, 2018, 52(10): 1363-1369.
- 12. 杨贤, 唐超兰, 李航. 基于文本块密度与标签路径等特征的正文提取[J]. 广东工业大学学报, 2018, 35(2): 51-56.
- 13. 陈雪, 徐慧, 沈家峻. 基于网页结构的网页去噪算法设计[J]. 软件, 2013, 34(8): 95-97.
- 14. 宋鳌, 支琤, 周军, 等. 基于LCS的特征树最大相似性匹配网页去噪算法[J]. 电视技术, 2011, 35(13): 44-48+63.
- 15. 梁东, 杨永全, 魏志强. 基于支持向量机的网页正文内容提取方法[J]. 计算机与现代化, 2018(9): 21-26+31.
- 16. W. Bruce Croft, Donald Metzler, 等. 搜索引擎信息检索实践[M]. 北京: 机械工业出版社, 2010.
- 17. 刘春卫, 罗健旭. 基于混合核函数的PSO-SVM分类算法[J]. 华东理工大学学报(自然科学版), 2014, 40(1): 96-101.
- 18. Raghavan, V. and Wang, G.S. (1989) A Critical Investigation of Recall and Precision as Measures of Retrieval System Performance. ACM Trans on Information Systems, 7, 205-229. https://doi.org/10.1145/65943.65945