Modeling and Simulation
Vol.
12
No.
01
(
2023
), Article ID:
60157
,
14
pages
10.12677/MOS.2023.121007
古代玻璃制品的成分分析与 鉴别
项辉1,王可2,金乐1,李霁昊2,李响3
1上海理工大学机械工程学院,上海
2上海理工大学光电信息与计算机工程学院,上海
3上海理工大学出版印刷与艺术设计学院,上海
收稿日期:2022年11月4日;录用日期:2023年1月3日;发布日期:2023年1月11日

摘要
在经过初步分析后,使用SPSS中的Fisher判别分析对附件1的样本数据整体进行两次Fisher判别分析,得出化学成分中对于分类有明显影响的主要变量和高钾玻璃、铅钡玻璃的分类规律。分析得知风化文物的未风化采样点与未风化文物的采样点性质相似,故将其视为未分化组样本再使用excel进行统计性分析。首先使用SPSS分别画出高钾玻璃化学成分和铅钡玻璃化学成分的散点图,若判断具有线性关系,再使用皮尔逊相关系数进行不同类型玻璃文物化学成分相关性分析。考虑到风化作用的影响,所以将高钾玻璃和铅钡玻璃分为风化高钾、未风化高钾、风化铅钡、未风化铅钡4类进行分析。在进行未知文物的类型鉴别分析时,使用RUSBoost算法和决策树模型分别进行鉴别,将两种方法得到的结果使用ROC曲线进行比较得出类型鉴别结果更好的模型,并使用网格搜索法进行模型的敏感性分析。本文对于探究高钾、铅钡玻璃的分类规律以及玻璃文物的分类有一定的应用价值。
关键词
Fisher判别分析,皮尔逊相关系数,RUSBoost算法,决策树模型,ROC曲线,网格搜索法

Composition Analysis and Identification of Ancient Glass Products
Hui Xiang1, Ke Wang2, Le Jin1, Jihao Li2, Xiang Li3
1School of Mechanical Engineering, University of Shanghai for Science and Technology, Shanghai
2School of Optoelectronic Information and Computer Engineering, University of Shanghai for Science and Technology, Shanghai
3College of Communication and Art Design, University of Shanghai for Science and Technology, Shanghai
Received: Nov. 4th, 2022; accepted: Jan. 3rd, 2023; published: Jan. 11th, 2023

ABSTRACT
After the preliminary analysis, the Fisher discriminant analysis in SPSS was used to conduct two Fisher discriminant analyses on the whole sample data of Attachment 1, and the main variables in the chemical composition that had a significant impact on the classification and the classification rules of high-potassium glass and lead-barium glass were obtained. After analysis, it is found that the unweathered sampling points of weathered cultural relics have similar properties to those of unweathered cultural relics, so they are regarded as undifferentiated group samples and then used excel for statistical analysis. Firstly, SPSS was used to draw scatter plots of chemical compositions of high-potassium glass and lead-barium glass respectively. If it is judged that there is a linear relationship, then Pearson correlation coefficient was used to analyze the chemical composition correlation of different types of glass relics. Considering the influence of weathering, high-potassium glass and lead-barium glass are divided into four categories: weathered high-potassium, unweathered high-potassium, weathered lead-barium and unweathered lead-barium for analysis. RUSBoost algorithm and decision tree model were respectively used for the type identification analysis of unknown cultural relics. ROC curve was used to compare the results of the two methods to obtain a model with better type identification results, and grid search method was used to analyze the sensitivity of the model. This paper has certain application value to explore the classification rules of high potassium, lead barium glass and the classification of glass relics.
Keywords:Fisher Discriminant Analysis, Pearson Correlation Coefficient, RUSBoost Algorithm, Decision Tree Model, ROC Curve, Grid Search Method

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
我国古代吸收来自西亚和埃及地区的玻璃技术后,在本土就地取材,为了降低炼制玻璃时的熔化温度,需要在石英砂中添加助熔剂和作为稳定剂的石灰石。由于添加的助熔剂的不同,导致了最终炼制出的玻璃的化学成分也不相同。常常作为助熔剂的物质有铅矿石和钾含量高的草木灰,前者形成的玻璃被称为铅钡玻璃是我国发明的品种,后者形成流行于我国岭南、东南亚及印度等范围内的钾玻璃。
受环境影响,古代玻璃极容易被风化,使其内部元素与环境元素大量交换,成分比例产生变化。
使用SPSS对附件1的样本数据整体进行两次Fisher判别分析,分别得出化学成分中对于分类有明显影响的主要变量和玻璃文物的分类规律。将风化文物的未风化采样点视为未分化组样本,使用excel进行统计性分析。分别画出高钾玻璃化学成分和铅钡玻璃化学成分的散点图,判断线性关系再使用皮尔逊相关系数进行不同类型玻璃文物化学成分相关性分析。考虑到风化作用的影响,所以将高钾玻璃和铅钡玻璃分为4类进行分析。在进行未知文物的类型鉴别分析时,使用RUSBoost算法和决策树模型分别进行鉴别,将两种方法得到的结果使用ROC曲线进行比较得出类型鉴别结果更好的模型,并使用网格搜索法进行模型的敏感性分析。
2. 高钾玻璃、铅钡玻璃的分类规律
LDA (Liner Discriminant Analysis)是一种十分经典的线性判别方法,又称为Fisher判别分析。其目标为求出一个最优的投影空间,使得异类点之间尽可能的远离,同类点之间尽可能的接近和密集,使得在完成投影后,可以将两类数据点有效的分开 [1]。
在使用SPSS进行线性判别分析时,将附件1中的数据根据玻璃文物是否风化分成两组分别进行判别分析和整体一起判别分析得到的结果进行比较,得到的结果相差不大,故此处为了简化模型的求解,因此采取整体一起判别分析的方法进行该部分的分析。由于玻璃文物的成分变量一共有14个,无法准确判断哪几个为主要变量,所以先采用一次判别分析,得到标准化典型判别函数系数如表1所示。

Table 1. Coefficients of full-component standardized canonical discriminant functions
表1. 全成分标准化典型判别函数系数
现对上表进行进一步的分析,由于玻璃的主要成分均为二氧化硅对玻璃类型的划分影响较小,所以在选取主要变量时剔除二氧化硅。在剩下的13个变量中,可以由初步分析的系数得知氧化铅和氧化钡这两种成分对于玻璃类型的相对影响较大,故接下去的第二次线性判别分析只选用这两个成分作为变量,得到表2。
Table 2. Normalized canonical discriminant function coefficients of some components
表2. 部分成分标准化典型判别函数系数
在第二次判别分析中,对于玻璃类型的判别成功率为91.4%,达到了较高的成功率。分析表2可以得知相较于高钾玻璃,氧化铅和氧化钡对铅钡玻璃的相对贡献率更加的明显。得到如下结论,氧化铅和氧化钡含量高的玻璃有较高的概率是铅钡玻璃,而氧化铅和氧化钡含量低的玻璃有较高的概率是高钾玻璃。
3. 风化前后化学成分的统计性分析
由分析得知风化文物的未风化采样点与未风化文物的采样点数据差别不大,所以在进行风化前后化学成分的统计性分析时,把附件1中表面风化但采集点是未风化的文物的数据样本归属于未风化组。
由图1、图2可知对于高钾玻璃,氧化钠、氧化钾、氧化钙、氧化镁、氧化铝、氧化铁、氧化铜、氧化铅、氧化钡、五氧化二磷、氧化锶、氧化锡、二氧化硫这十三个成分风化后的平均占比相较与风化前均降低,只有二氧化硅风化后的均值占比相较于风化前大幅度提高。由此可以看出风化对于各成分的相对作用都比较明显,且相较于二氧化硅对于其余十三个成分的相对作用率更高。
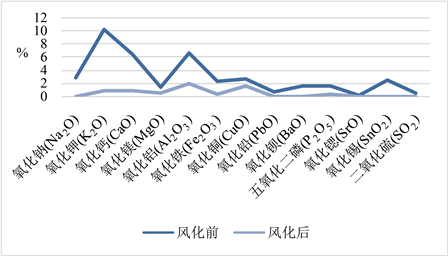
Figure 1. Changes in the mean proportion of 13 components of high potassium glass before and after weathering
图1. 高钾玻璃十三个成分风化前后占比均值变化
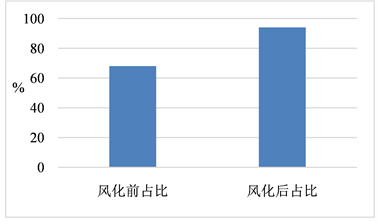
Figure 2. Comparison of the mean proportion of high potassium glass silica before and after weathering
图2. 高钾玻璃二氧化硅风化前后占比均值对比
由图3可知铅钡玻璃中二氧化硅的占比均值降低较明显,说明风化作用对于二氧化硅的作用量和作用率均较明显。氧化钠、氧化钾、氧化铁、氧化锶这四种成分在风化作用后占比均值减小不明显,说明风化作用对于这四种成分的作用率和风化作用对于整体的作用率差不多。其余的九个成分在风化作用后占比均值均升高,说明风化作用对于这九种成分的作用率均低于风化作用对于整体的作用率。
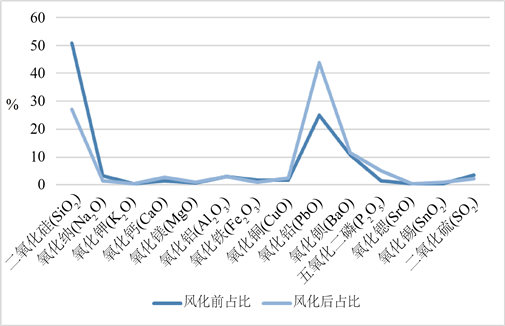
Figure 3. Comparison of mean ratios of 14 components of lead-barium glass before and after weathering
图3. 铅钡玻璃十四个成分风化前后占比均值对比
4. 不同类型玻璃文物化学成分相关性和差异性分析
使用SPSS画出附件1中样本高钾玻璃化学成分和铅钡玻璃化学成分的散点图如图4和图5所示。

Figure 4. Dot plot of chemical dispersion of high potassium glass
图4. 高钾玻璃化学成分散点图
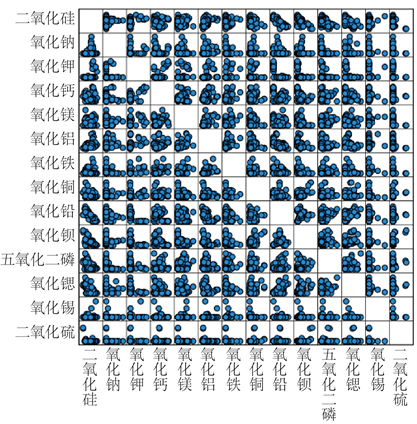
Figure 5. Dot plot of chemical dispersion of lead-barium glass
图5. 铅钡玻璃化学成分散点图
由散点图矩阵可知各化学成分之间具有线性关系,因此可以使用皮尔逊相关系数进行进一步的分析 [2]。由于风化作用会影响玻璃制品化学成分的含量,所以将高钾玻璃和铅钡玻璃分为4类,风化高钾、未风化高钾、风化铅钡、未风化铅钡进行分析。通过SPSS的皮尔逊模型利用附件1中的样本数据分析这4类玻璃制品化学成分之间的相关关系,得到的具有显著性关系的化学成分类型与其相关系数如表3~6所示。
Table 3. Relationship between weathering high potassium chemical components
表3. 风化高钾化学成分之间的关系
Table 4. Relationship between chemical components of unweathered high potassium
表4. 未风化高钾化学成分之间的关系
Table 5. Relationship between weathering lead barium chemical compositions
表5. 风化铅钡化学成分之间的关系
Table 6. Relationship between chemical compositions of unweathered lead and barium
表6. 未风化铅钡化学成分之间的关系
高钾玻璃与铅钡玻璃的化学成分有不同种类的差异性,如化学成分成正相关的种类、个数不同等,接下去将从差异性较明显的方面对上述表3~6及附件1进行分析。
由表6中的相关系数可知,铅钡玻璃中与氧化钾成正相关性的其他化学成分有6个,与二氧化硅成负相关性的其他化学成分有6个;而表4表明,高钾玻璃中与氧化钾成正相关性的其他化学成分只有2个,与二氧化硅成负相关性的其他化学成分只有2个。
由表4和表6可知,铅钡玻璃的化学成分中成正相关关系的个数比高钾玻璃的多,如图6所示。
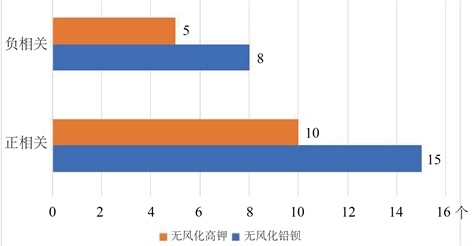
Figure 6. The number of types of chemical composition correlation of unweathered glass
图6. 无风化玻璃化学成分相关性的种类个数
由表3和表5可知,铅钡玻璃的各化学成分中有正相关性的比较多,共有11组,而高钾玻璃有正相关性的化学成分只有4组。在铅钡玻璃中对氧化锡成负相关性的其他化学成分个数比较多,有6种(氧化钙、氧化铁、氧化铅、氧化钡、五氧化二磷、氧化锶),而在高钾玻璃中,没有对氧化锡成负相关性的化学成分。
铅钡玻璃的化学成分中成负相关关系的个数比高钾玻璃的多,是高钾玻璃的3倍,如图7所示。
5. 未知类型玻璃文物的类型鉴别
5.1. RUSBoost预测模型的建立
RUSBoost算法是一种结合欠采样方法与Boosting的混合算法。将Boost算法的每轮迭代,在训练弱分类器之前,使用随机欠抽样方法抽取一定量的多数类样本和少数类组成平衡分布的训练数据集,用于弱分类器训练,RUSBoost运算步骤如下:
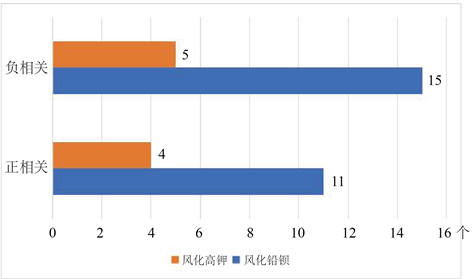
Figure 7. Number of types of correlations between weathering glass chemical compositions
图7. 风化玻璃化学成分相关性的种类个数
(1)
(2)
(3)
首先,所有样本初始化为1/m;其次,利用欠采样方法生成训练集S,并且通过对S中各样本的原有权重进行归一化处理,以获得一个弱分类器h(t)然后根据h(t)判别输出概率高为p1,低位p2,根据公式(1)计算误差e,根据公式(2)计算α(t)根据公式(3)更新权重并归一化。最终通过T次迭代,输出全部集成分类器:
在迭代过程中,RUSBoost算法通过调整样本权重的分布来提升后续基学习器的准确率 [3]。
由图8可知TP = 49,FN = 0,FP = 0,TN = 18得出分类准确率Accuracy = 1查全率和查准率的调和平均数F1 = 1,可知预测结果较为准确。
将附件2中的未知类别玻璃文物的化学成分进行分析,鉴别其属性,得出结果如表7所示。
5.2. 决策树模型的建立
决策树(decision tree)是一种基本的分类与回归方法,在分类问题中,表示根据特征对样本进行分类的过程。
将所有训练数据都放在根节点,选取最佳特征,根据特征将训练数据集分割成子集,使各个子集都具有在当前条件下最好的分类。构建叶节点,将分割后的子集分到所对应的叶节点去。递归进行,直至所有训练数据子集被基本正确的分类,或者没有合适的特征为止。
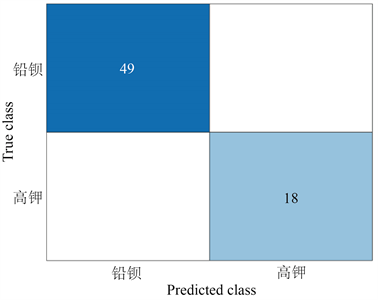
Figure 8. RUSBoost confusion matrix
图8. RUSBoost混淆矩阵
Table 7. Predicted types of unknown glass relics
表7. 未知玻璃文物预测类型
从根节点开始,对样本的某一特征进行测试,根据测试结果将测试数据分到其子节点,此时每个子节点对应着该特征的一个取值,递归的对要样本进行测试并分配,到达叶节点,最后将实例分到叶节点的类中 [4]。
默认决策树最大分裂数为100,分裂准则为Gini’s diversity index,根据决策树方法可得图9。
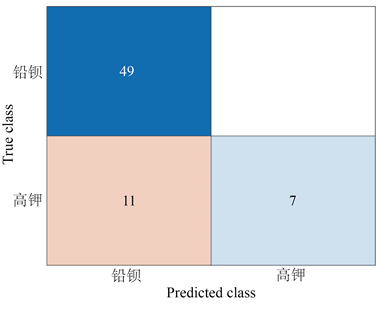
Figure 9. Decision tree confusion matrix
图9. 决策树混淆矩阵
TP = 49,FN = 0,FP = 11,TN = 7,得出分类准确率Accuracy = 83.6%,查全率和查准率的调和平均数F1 = 0.90。对附件2中的未知类别玻璃文物的化学成分进行分析,鉴别其属性,得出全为铅钡类型。可知预测结果偏差较大。
5.3. 模型的对比与预测结果分析
ROC曲线是根据一系列不同的分类阈值,以假正类率(False Positive Rate, FPR)为横坐标,真正类率(True Postive Rate, TPR)为纵坐标绘制的曲线。
ROC曲线的用法可以将不同模型的 ROC 曲线绘制在同一张图内,最靠近左上角的那条曲线代表的模型的分类效果最好。
AUC被定义为ROC曲线与下方的坐标轴围成的面积,AUC的范围位于[0, 1]之间,AUC越大则模型的分类效果越好,本文将AUC小于等于0.5的模型视为无效。在本文中当AUC大于0.85的模型可以认为表现较好 [5]。
通过对Boosted Trees和RUSBoost的ROC曲线比较得到图10如下所示。

Figure 10. RUS compared with BoostingAUC
图10. RUS与BoostingAUC比较
RUSBoosted Trees的AUC值为1,BoostedTrees的AUC值为0.966,可知RUSBoosted的分类效果更好。由此得出随机欠采样与标准提升程序AdaBoost相结合,通过删除多数类样本来更好地对少数类进行建模。并且使得算法更简单,模型训练时间更快。
通过图11可以更加直观的进行RUSBoost模型和决策树模型的比较,得出预测结果较为准确的值是表7所预测的值。
5.4. 模型敏感性分析
敏感性分析是研究一个数学模型或数值输出中的不确定性如何被划分和分配到输入中的不确定性的不同来源。通常操作方法为控制其他参数不变的情况下,改变模型中某个重要参数的值,然后观察模型的结果的变化情况。选取结果最优的时候的参数。决策树的最大分裂数越大,树越复杂可能导致过拟合的现象,如果值过小树深度过浅可能导致欠拟合的现象。因此通过敏感性分析获得最佳的最大分裂树。
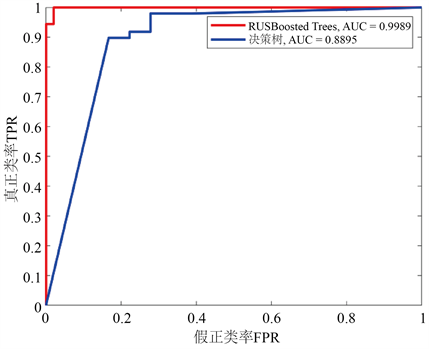
Figure 11. RUS compared to the decision tree AUC
图11. RUS与决策树AUC比较
网格搜索法是指定参数值的一种穷举搜索方法,通过将估计函数的参数通过交叉验证的方法进行优化来得到最优的学习算法。即将各个参数可能的取值进行排列组合,列出所有可能的组合生成“网络”。然后将各个组合用于SVM训练,并使用交叉验证对表现进行评估 [6]。
使用网格搜索对RUSBoost中决策树的个数和决策树的最大分裂数进行调参得到图12。
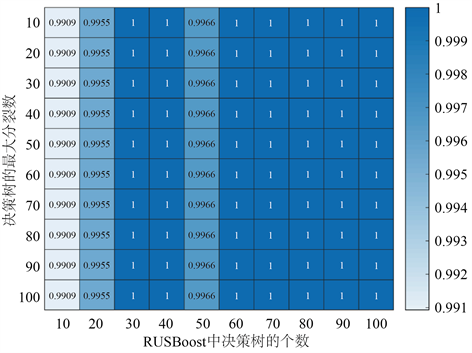
Figure 12. RUSBoost thermal map
图12. RUSBoost热力图
由图12可知决策树的最大分裂数为10,RUSBoost中决策树的个数为30的时候,AUC为1,分类效果最好。
决策树分裂有三个准则分别为Gini’s diversity index,Twoing rule,Maximum deviance reduction,通过网格搜索得到图13。
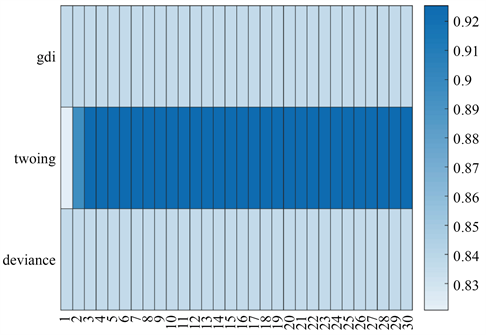
Figure 13. Decision tree thermal map
图13. 决策树热力图
由图13可得当决策树分裂准则为Twoing rule,最大分裂数为3时,分类效果最好,此时F1的值为0.9254,准确率Accuracy提高到91%,再次预测结果如表8所示。
Table 8. Type prediction scores
表8. 类型预测分数
6. 结语
在经过两次Fisher判别分析后,得出化学成分中对于分类有明显影响的主要变量为氧化铅和氧化钡,分类规律为氧化铅和氧化钡含量高的玻璃有较高的概率是铅钡玻璃,而氧化铅和氧化钡含量低的玻璃有较高的概率是高钾玻璃。将附件1中表面风化但采集点是未风化的文物的数据样本划归未风化组后,使用excel对附件1数据进行统计性分析。得到结论,风化对高钾玻璃中各成分的相对作用都比较明显,且相较于二氧化硅对于其余十三个成分的相对作用率更高。风化作用对铅钡玻璃中二氧化硅的作用量和作用率均较明显,对氧化钠、氧化钾、氧化铁、氧化锶这四种成分的作用率和风化作用对于整体的作用率差不多,对其余九个化学成分作用率均低于风化作用对于整体的作用率。
使用SPSS分别画出高钾玻璃化学成分和铅钡玻璃化学成分的散点图,在得到其有线性关系后使用皮尔逊相关系数得出4类玻璃文物成分的相关系数。分析相关系数表可知未风化组中,铅钡玻璃的化学成分中与氧化钾成正相关性的其他化学成分有6个,而高钾玻璃只有2个;与二氧化硅成负相关性的其他化学成分种类有6个,而高钾玻璃只有2个。在风化组中,铅钡玻璃的各化学成分中有正相关性的比较多,共有11组,而高钾玻璃有正相关性的化学成分只有4组。在铅钡玻璃中对氧化锡成负相关性的其他化学成分有6个,而在高钾玻璃中,没有与氧化锡成负相关性的化学成分。
在进行未知文物的类型鉴别分析时,由RUSBoost混淆矩阵和决策树模型预测分别对附件2中的未知类别玻璃文物的化学成分进行分析,鉴别属性。使用ROC曲线对比两个模型的预测结果,可知RUSBoost混淆矩阵得出的预测结果更准确。最后使用网格搜索法对RUSBoost中决策树的个数和决策树的最大分裂数进行调参,可知决策树的最大分裂数为10,RUSBoost中决策树的个数为30的时候,AUC为1,分类效果最好。该模型在实际应用中,对于玻璃文物的分类有着一定的应用价值。
文章引用
项 辉,王 可,金 乐,李霁昊,李 响. 古代玻璃制品的成分分析与鉴别
Composition Analysis and Identification of Ancient Glass Products[J]. 建模与仿真, 2023, 12(01): 67-80. https://doi.org/10.12677/MOS.2023.121007
参考文献
- 1. 黄利文. 基于变量择优的Fisher逐步判别分析方法[J]. 系统科学与数学, 2021, 41(8): 2338-2348.
- 2. 张景香, 刘亚丹, 杨钊. 基于SPSS分析煤灰白度的影响因素[J]. 煤炭技术, 2022, 41(2): 230-231. https://doi.org/10.13301/j.cnki.ct.2022.02.059
- 3. 钟华星. 基于RUSBoost算法的违约风险预测模型构建与应用[J]. 财会月刊, 2020(10): 74-80. https://doi.org/10.19641/j.cnki.42-1290/f.2020.10.010
- 4. 樊良优, 姚小强, 王刚, 刘伟, 夏智权. 基于决策树的指挥控制决策方法[J/OL]. 电光与控制: 1-7. http://kns.cnki.net/kcms/detail/41.1227.TN.20220913.1940.033.html, 2022-11-04.
- 5. 宋花玲. ROC曲线的评价研究及应用[D]: [硕士学位论文]. 上海: 第二军医大学, 2006.
- 6. 马小凤. 机器学习在学生通过率预测中的应用研究[D]: [硕士学位论文]. 重庆: 西南大学, 2019.