Statistical and Application
Vol.3 No.04(2014), Article
ID:14603,7
pages
DOI:10.12677/SA.2014.34023
Influence Factors Analysis of Household Income in Western Minority Areas
School of Statistics and Mathematics, Yunnan University of Finance and Economics, Kunming
Email: 123558526@qq.com
Copyright © 2014 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received: Oct. 5th, 2014; revised: Nov. 6th, 2014; accepted: Nov. 15th, 2014
ABSTRACT
In recent years, with the development of economy, and the improvement of living standards of farmers, researches on the factors of household income have been increasing. In this paper, on the basis of those studies, using the data sampling from the farmer in the minority areas of west China, and the per capita income of local farmers, we propose a panel data model to study the factors influencing household income by comparing analysis with the simple OLS. At last, we put forward some relevant policy suggestions to improve the household income in the minority areas of west China based on the results of empirical analysis.
Keywords:Household Income, Panel Data Model, Policy Suggestions

西部民族地区农民收入的
影响因素分析
程 勇,刘梦琦
云南财经大学,统计与数学学院,昆明
Email: 123558526@qq.com
收稿日期:2014年10月5日;修回日期:2014年11月6日;录用日期:2014年11月15日

摘 要
近年来,随着经济的发展,农民生活水平的提高,学者们对农民收入影响因素的研究越来越多。本文在这些研究的基础上,基于西部少数民族地区农户的抽样调查数据和当地农民人均收入的实际情况,通过与简单OLS方法的对比分析,建立面板数据模型,对影响农户人均收入的影响因素进行了研究。最后基于实证分析的结果,提出增加西部少数民族地区农民收入的相关政策建议。
关键词
农民收入,面板数据模型,政策建议

1. 引言
农民收入是农村经济的晴雨表,是中国经济长期发展的预报器,是全面建设小康社会和解决“三农”问题的物质前提和基础。我国少数民族地区一直属于我国的欠发达地区,发展仍然落后,并且自改革开放以来,民族地区与发达地区的差距进一步扩大,尤其是西部少数民族地区,相对于我国普通地区而言是少数民族成分最复杂、自然条件最恶劣、生态功能最显赫的地区,也是贫困程度最深的地区之一:人口众多但受教育程度低,资源丰富但地理位置偏远,拥有特殊的民族文化但也有落后的风俗观念,推进这一地区的新农村建设,具有十分重要的政治意义、生态意义和经济意义,而农户收入问题是关系到该地区新农村建设的重要问题之一。云南省红河州位于云南南部,是一个有着众多贫困人口的多民族地区,其农民人均纯收入不仅低于云南省平均水平,也远低于全国平均水平。因此研究影响西部农民收入的因素对了解我国边疆民族地区的农业发展状况,制定科学的农业政策具有重要的现实意义。
近年来,随着科技的发展和人民生活水平的不断提高,农民收入问题的研究也越来越多:张旭阳(2012)运用主成分分析的方法讨论了影响农民收入来源的因素,并建立多元回归模型,使用逐步回归的方法研究了影响农民收入的主要因素,进而提出增加农民收入的政策性建议:调整生产结构、加大财政投入力度,改变投入方向、增加非农产业投入、提高农民的素质教育;辛翔飞(2008)[1] 等在研究中西部地区农户收入及差异的影响因素中,依据农户收入方程,确定影响农户收入的主要因素;熊璋琳(2010)等采用因子分析方法对影响农民收入的因素进行了分析,得出影响农民收入的公共因子有农业生产、扩大再生产、信息利用及减收因子,农民受教育程度及掌握信息的能力对农民收入也有较大影响;卢启程(2007)[2] 等在研究云南省区域农民收入与其受教育程度的关系时,采用OLS法进行多元线性回归并分别用向前法(forward)和向后法(backward)进行变量筛选,得到受教育程度是影响农民收入的主要因素;王风(2005)基于收入函数从理论上对中国农民收入增长的主要因素进行了系统性的分析,得出的结论是影响农民收入的因素有单位农产品增加值、农产品纵列以及农业人口;石磊(2013)等在研究西部民族地区农民收入增长问题中,使用多水平发展模型研究影响农民收入增长的因素,研究结果表明农民收入与劳动力受教育程度、劳动力数、经济作物播种面积等因素显著相关。
综合上述文献可以看出,已有的文献在研究农民收入的影响因素时大多建立在多元回归函数和收入函数的基础上,并且其中大部分都忽略了数据中个体异质性和遗漏变量的问题,往往不能有效的进行精确的估计。本文在已有研究的基础上,通过与简单OLS方法的对比分析,基于面板数据模型的优越性,建立面板数据模型,来研究西部民族地区农民收入的影响因素问题。
2. 面板数据模型
2.1. 面板数据
面板数据是对同一组个体在不同时点进行重复观测所得到的数据,也就是说它是变量Y对于N个不同个体的T个观测所形成的二维结构数据。从时间序列来看,面板数据可以描述不同个体随时间变化的规律;从横截面数据看,面板数据可以描述同一时间点上不同个体间的差异。由于面板数据综合了时间序列数据和横截面数据的特点,我们不仅能够同时利用时间序列数据和截面数据建模,还能够有效控制不可观测的个体异质性,克服遗漏变量的影响。简单来说,面板数据的表达形式为[3] :
 (1)
(1)
其中: 为被观测的个体数,
为被观测的个体数,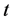 为重复观测次数,
为重复观测次数,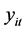 为被解释变量,
为被解释变量,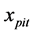 为解释变量,
为解释变量, 表示截距项,
表示截距项,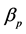 为待估参数,
为待估参数,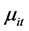 表示随机误差项。
表示随机误差项。
同时,假定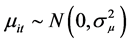 ,则模型可以写成如下形式:
,则模型可以写成如下形式:
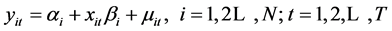 (2)
(2)
其中变量解释同模型(1)。
2.2. 面板数据模型
用来研究面板数据的模型称为面板数据模型,也就是说此模型是针对具有面板数据的结构而提出的。自面板数据这一新兴的计量经济学分析方法问世以来,它的理论和应用研究层出不穷,随着计量经济学科中统计方法和统计软件的不断完善,面板数据模型的理论方法已经走向成熟,并且基于面板数据模型的计量经济学分析已经成为计量经济学领域的重要组成部分[4] 。
相对只利用截面数据或只利用时间序列数据进行经济分析的模型而言,面板数据模型具有许多优点。首先,它通常提供给研究者大量的数据点,这样就增加了自由度并减少了解释变量之间的共线性,从而改进了计量经济估计的有效性;第二,面板数据模型可以从多层面分析经济问题;第三,截面变量和实际变量的结合能够显著地减少缺省变量所带来的问题。
面板数据模型分为静态面板数据模型和动态面板数据模型。所谓静态面板数据模型就是指模型中的解释变量中不包含被解释变量的滞后项的情形,它包括了混合模型、固定效应模型和随机效应模型等。反之若解释变量中包含了被解释变量的滞后项就变成了动态面板数据模型。由于静态面板数据模型在国内学术界研究和应用较多,这里只简单介绍一种静态面板数据模型。它的一般形式为[5] :
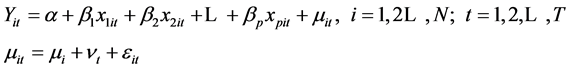 (3)
(3)
其中: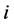 为被观测的个体数,
为被观测的个体数,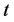 为重复观测次数,
为重复观测次数,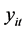 为被解释变量,
为被解释变量,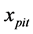 为解释变量,
为解释变量, 表示截距项,
表示截距项,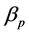 为待估参数,
为待估参数,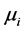 表示个体随机效应,
表示个体随机效应, 表示时间随机效应,
表示时间随机效应,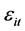 为随机误差。
为随机误差。
当 为随机误差项且有
为随机误差项且有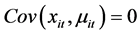 时,模型(3)为混合模型,即:
时,模型(3)为混合模型,即:
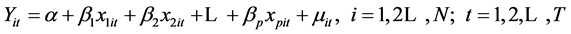 (4)
(4)
其中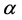 表示截距项,
表示截距项,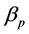 为待估参数,可以用混合最小二乘估计(Pooled OLS)来对其进行参数估计。
为待估参数,可以用混合最小二乘估计(Pooled OLS)来对其进行参数估计。
当假定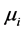 和
和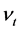 为固定待估参数,且
为固定待估参数,且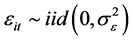 时,模型(3)为固定效应面板数据模型。即:
时,模型(3)为固定效应面板数据模型。即:
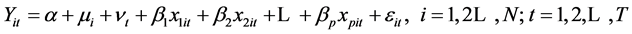 (5)
(5)
其中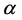 、
、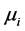 、
、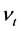 、
、 均为可估参数,可采用广义最小二乘法的协方差分析(ANCOVA)进行估计。
均为可估参数,可采用广义最小二乘法的协方差分析(ANCOVA)进行估计。
当假定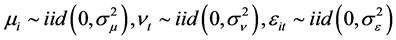 ,并且它们相互独立时,模型(3)为随机效应面板数据模型。即:
,并且它们相互独立时,模型(3)为随机效应面板数据模型。即:
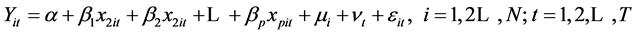 (6)
(6)
其中,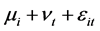 为复合残差项,
为复合残差项,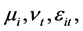 为不可观测的随机误差。随机效应模型可以用广义最小二乘估计(GLS)和极大似然估计(MLE)来进行参数估计。
为不可观测的随机误差。随机效应模型可以用广义最小二乘估计(GLS)和极大似然估计(MLE)来进行参数估计。
在对面板数据的分析中,多采用固定效应模型或随机效应模型,然后根据Husman检验的结果来确定使用哪种模型。实际上Hausman检验在某种程度上来说,是没有任何意义的,因为无论结果如何,选择固定效应模型总不会错。固定效应模型和随机效应模型之间最大的不同就在于其基本假设,即个体不随时间改变的变量是否与所预测的或自变量相关[6] 。固定效应模型认为包含个体影响效果的变量是内生的,而与此相反,随机效应模型是假设全部的包含个体随机影响的回归变量是外生的[7] 。在模型中变量的引入上,固定效应模型默认了那些不随时间变化而变化的自变量不会对因变量造成影响,因而不允许这类变量出现在模型之中;随机效应模型则认为表示某些个体特征的但不随时间变化而变化的自变量能够对因变量造成影响,允许这类变量引入到模型之中[8] 。
3. 模型建立
3.1. 模型变量的选择
农村居民收入主要由从事农业生产的收入和从事非农业生产收入两部分构成。其中,从事农业生产的收入受到土地面积、农业中粮食作物和其它经济作物的比例结构、高科技成果在农业生产中的运用情况和农民进行农业生产劳作的积极性等方面的情况影响;从事非农业生产的收入受到农村剩余劳动力转移情况、农民受教育水平以及劳动力平均年龄等方面的情况影响。由于农民进行农业生产劳作的积极性是不可量化的因素、高科技成果在农业生产中的实际运用情况无法明确量化,所以本文仅用人均土地面积、粮食播种面积占农作物播面积的比重、经济作物播种面积及比例等因素作为影响农业生产收入的主要因素;将就业类型、农民教育水平、劳动力平均年龄等因素作为影响非农业生产收入的主要因素。
本文使用的数据来自云南省红河哈洲统计局2006~2009年对3000农户的跟踪调查数据。该调查包括了红河州13个县市,298个行政村,每个行政村随机抽取10~15户进行调查,每户进行了四年的跟踪调查。调查数据对各县市及乡镇均有较好的代表性,调查指标涵盖了农户基本的社会经济情况和地理环境因素,是一组能够全面反映边疆少数民族地区农户经济发展和社会进步的微观经济数据,对研究边疆民族地区农户经济发展提供了重要的基础信息[9] 。经过对以往文献研究影响农户收入因素的整合以及对该数据中各个指标的分析,确定研究中所涉及的变量和指标如下表1所示:
在上述指标中,人均生产性固定资产原值(x2),人均实际经营的土地面积(x3),人均经济作物播种面积(x4)为物质资本指标;整半劳动力数(x6),劳动力的平均年龄(x7),劳动力的平均受教育程度(x8)和受培训的劳动力比例(x9)为劳动力资本指标;调查户从业类型(x1)和经济作物种植比例(x5)反映了农户生产经营结构 。剔除部分不可用数据及缺失数据,共得到包含1768个个体的样本,每个个体都包含4年的连续观察数据,因此是一个平衡的面板数据。
3.2. 建立模型
由于本文数据是从总体中随机抽取的,我们可认为数据中作为个体的农户是随机的,农户个体的特性(个体异质性)能够影响到人均收入,例如一个拥有身强力壮的劳动力的农户和一个只有单薄劳动力的农户,他们的收入是肯定不同的;其次,模型中有些变量是不随时间变化而变化的,例如调查户从业类型

Table 1. Variable explanation
表1. 数据变量说明
及劳动力平均受教育程度在短期内除了特殊情况是不会变的,又比如各个农户所处的地理位置差异及所处的自然条件除特殊情况也是不会变的,在一般的线性模型分析或者其他一些回归分析中,大多认为此类型的变量对响应变量没有影响或者产生影响较小,不会将其纳入分析模型;最后,所取样本为只含4个时间点的短面板数据,若采用固定效应模型会损失很大的自由度。那么综合以上情况,为了克服忽略个体异质性影响以及一般回归分析中遗漏那些不随时间变化而变化的变量带来的估计偏差问题,本文采用随性效应模型进行分析。为了验证随机效应模型的正确性,在建立模型估计后,我们用Breusch-Pagan检验[10] [11] 进行进一步确保使用模型的合理性。
3.2.1. 混合效应模型
当我们不考虑模型(3)中个体随机效应和时间随机效应时,模型就可以改变成混合效应模型形式,它的特点是无论对任何个体和截面,回归系数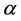 和
和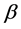 都相同,也就是将面板数据汇集成一个截面数来进行处理,此时我们用简单OLS估计就可以了,为简便,我们可以将混合效应模型(4)改写成如下形式,即:
都相同,也就是将面板数据汇集成一个截面数来进行处理,此时我们用简单OLS估计就可以了,为简便,我们可以将混合效应模型(4)改写成如下形式,即:
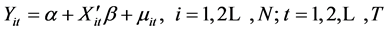 (7)
(7)
其中: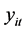 代表因变量,
代表因变量,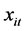 代表
代表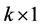 阶自变量,
阶自变量,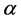 为截距项,
为截距项,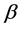 代表
代表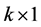 阶回归系数。
阶回归系数。
3.2.2. 随机效应模型
本文已经确定使用随机效应模型,那么固定效应模型就不再讨论,我们只考虑个体随机效应,并且将随机效应面板数据模型(6)改写成更为简洁的形式:
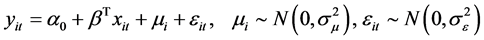 (8)
(8)
其中: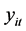 代表因变量,
代表因变量,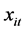 代表自变量,
代表自变量,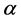 为截距项,
为截距项,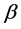 代表固定效应系数,
代表固定效应系数,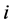 表示被观测的个体,
表示被观测的个体,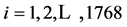 ,
,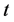 表示观测时间,
表示观测时间,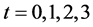 ,
, 代表随机效应,
代表随机效应, 为随机误差。
为随机误差。
3.2.3. Breusch-Pagan检验
Breusch-Pagan检验通过构建拉格朗日乘数来确定选择随机效应模型还是采用简单OLS估计的方法。
Breusch-Pagan检验的零假设是:个体之间没有差异。即,不同的个体之间不存在明显的不同。
它基本原理是:若约束是有效的,那么最大化拉格朗日函数所得到的有约束的参数估计量应该位于最大化原始样本似然函数的参数估计值附近。因而,在处对数似然函数的斜率应该趋近于0。因而,Breusch-Pagan检验就是在有约束估计量处,通过检验对数似然函数的斜率是否趋近于0来检验约束是否有效。
4. 农民收入影响因素实证分析
4.1. 混合效应模型
首先,运用混合效应模型来对农民收入模型进行分析研究,混合效应模型如下:
本文通过R软件的plm包,使用简单OLS估计对混合效应模型进行分析,分析结果如下:
OLS估计结果:
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
(Intercept) −6.7075e−01 2.4808e−01 −2.7038 0.006872**
x1 6.6854e−01 4.6935e−02 14.2440 <2.2e−16 ***
x2 8.3043e−02 9.6857e−03 8.5737 <2.2e−16***
x3 9.0009e−02 1.6708e−02 5.3871 7.391e−08***
x4 8.2507e−05 4.4166e−03 0.0187 0.985096 x5 −1.0668e+00 1.4072e−01 −7.5810 3.866e−14***
x6 −2.0363e−01 2.7147e−02 −7.5009 7.113e−14***
x7 4.8741e−02 4.2728e−03 11.4074 <2.2e−16***
x8 5.6925e−01 4.4146e−02 12.8945 <2.2e−16***
x9 −6.2622e−01 8.5827e−02 −7.2963 3.282e−13***
Signif. Codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Total Sum of Squares: 48229 Residual Sum of Squares: 41680 R-Squared: 0.1358 Adj. R-Squared: 0.13561 F-statistic: 123.303 on 9 and 7062 DF, p-value: <2.22e-16
4.2. 随机效应模型
然后,通过R软件的plm包,使用随机效应模型对数据进行分析,模型为:
分析结果如下:
随机效应模型回归数据
Effects:
var std.dev share idiosyncratic 5.2179 2.2843 0.925 individual 0.4231 0.6505 0.075 theta: 0.131 Coefficients:
Estimate Std. Error t-value Pr(>|t|)
(Intercept) −0.59685150 0.26590884 −2.2446 0.02483*
x1 0.63595353 0.04899551 12.9798 <2.2e−16***
x2 0.08324893 0.01017638 8.1806 3.322e−16 ***
x3 0.09118429 0.01811504 5.0336 4.932e−07***
x4 0.00016237 0.00441584 0.0368 0.97067 x5 −1.01850387 0.14691340 −6.9327 4.495e−12 ***
x6 −0.22116988 0.02926524 −7.5574 4.630e−14 ***
x7 0.04869175 0.00458386 10.6224 <2.2e−16 ***
x8 0.57281066 0.04755295 12.0457 <2.2e−16***
x9 −0.77507967 0.08849403 −8.7586 <2.2e−16 ***
Signif. Codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Total Sum of Squares: 43737 Residual Sum of Squares: 38554 R-Squared: 0.1185 Adj. R-Squared: 0.11833 F-statistic:105.478 on 9 and 7062 DF, p-value: <2.22e−16从结果中我们可以看到非观测性误差 的方差为0.42,表明确实存在个体之间的影响,即随机效应模型的可适用性。为了进一步确定用随机效应模型方法是否正确,继续采用Breusch-Pagan检验的方法,结果如下:
的方差为0.42,表明确实存在个体之间的影响,即随机效应模型的可适用性。为了进一步确定用随机效应模型方法是否正确,继续采用Breusch-Pagan检验的方法,结果如下:
Breusch-Pagan检验结果
Lagrange Multiplier Test—(Breusch-Pagan)
data: y ~ x1 + x2 + x3 + x4 + x5 + x6 + x7 + x8 + x9 chisq = 54.8555, df = 1, p-value = 1.297e−13 alternative hypothesis: significant effects
在0.05的显著水平下,我们的p值显著的小于0.05,因此使用随机效应模型方法进行分析比用简单OLS方法的混合效应模型更有效。
4.3. 结果分析
由于Breusch-Pagan检验确定了使用随机效应模型,那么我们从随机效应模型的系数表中,可以得出以下几点结论:
1) 农户人均纯收入与就业类型、人均固定资产原值、人均实际经营土地面积、经济作物种植比例、整半劳动力数、劳动力平均年龄、劳动力平均受教育程度以及受培训的劳动力比例在显著水平为0.05的水平下都显著相关,它们的系数分别为:0.64、0.08、0.09、−1.02、−0.22、0.05、0.57、−0.78。
2) 就业类型(x1)、经济作物种植比例(x5)、整半劳动力数(x6)、劳动力平均受教育程度(x8)、以及受培训的劳动力比例(x9)的系数绝对值都大于0.1,并且它们都非常显著,表明它们对人均纯收入的影响较大。
3) 经济作物种植面积(x4)的系数相对非常小,而且不显著,表明它对农民收入的影响不大。
4) 经济作物种植比例和整半劳动力数的系数为负,表明经济作物种植比例越高,家庭人口越多,人均纯收入越低。这说明边疆地区农村家庭中存在生产结构不合理、劳动力过剩或农业从业比重不均衡的情况。
5. 根据该模型提出政策建议
1) 从模型综合各因素可知,影响农民收入的主要因素有:家庭结构、劳动力的特点及作物种植比例。因此要想切实保障农民收入,就应该从以上三个方面入手,制定合理有效的政策。
2) 加快农业结构调整,引导农户改变生产结构。由于西部民族地区属于欠发达地区,地理位置较差,交通、通讯、电力等基础设施建设落后,吸引投资能力较弱,我们应该从实际出发,以促进第一产业发展为主导,合理分配农、林、牧、副、渔各业的比重以及粮食作物和经济作物的种植比例;合理配置农业资源,提高资源利用效率,因地制宜地发展非农产业,结合本地资源优势,以区域特色产业开发为重点进行农业结构调整,实现农业产业化[12] ;农业与非农业生产统筹经营,促进农户家庭生产经营多元化格局的形成。
3) 加强基础教育和职业培训,提高农民素质。加大对农村教育的扶持是提高农民素质的重要手段,针对边疆地区教育水平普遍较低的情况,更应该大力、全面地发展农村教育,提高农民受教育水平、接受技能培训的比例,提高农业科技成果转化率[13] 。加强农村教育培训体系建设,大力提高农民整体素质,从整体和长远上提高农村人力资本水平,促进农民收入增长[9] 。
4) 积极推进农村劳动力转移。长期以来,西部民族地区发展较慢,农业剩余劳动力较少,但是随即技术的进步和社会的发展,劳动力的转移成为必然,过多的剩余劳动力会造成人力资源的浪费,也会影响到农民的人均收入。引导和加快农村剩余劳动力有序的流动和转移,可以减少农村人口,增加农民收入,进一步提高人均收入水平[14] 。
5) 保证合理的作物种植比例。对于边疆地区农户来说,由于地貌特性以及交通、物资等条件的限制,从事农业生产依然是他们获取收入的主要来源。粮食作物虽然附加值比较小,但它是当地农户赖以生存的重要资源;经济作物虽然价格高、附加值高,但由于边疆地区的特殊地域特征造成的交通不便、通讯较差等问题使得经济作物的附加值也大打折扣,因此各地区应该结合本地实际情况,合理分配粮食作物与经济作物种植比例。
参考文献 (References)
- [1] 辛翔飞 (2008) 中西部地区农户收入及其差异的影响因素分析, 中国农村经济, 40-52.
- [2] 卢启程, 李怡佳, 邹平 (2007) 云南省区域农民收入与其受教育程度的关系调查. 教育与经济, 4, 7-10.
- [3] 武大勇 (2006) 计量经济学中国的面板数据模型分析. 硕士论文, 华中科技大学, 武汉.
- [4] 亓芳芳 (2010) 基于面板数据模型的中国民用汽车消费需求预测研究. 硕士论文, 中国科技大学, 合肥.
- [5] Baltagi, B.H. (2005) Econometric analysis of panel data. Antony Rowe Ltd, Great Britain, 1-55.
- [6] Green, S. (2008) Cochrane handbook for systematic reviews of interventions version 5.0.0, 183.
- [7] Mundlak, Y. (1978) On the pooling of time series and cross section data. Econometrica, 46, 69-85.
- [8] 韩雪亮 (2012) 企业间关系与企业商业信用融资的实证研究. 硕士论文, 暨南大学, 广州.
- [9] 石磊, 向其凤, 陈飞 (2013) 多水平模型及其在经济领域的应用. 科学出版社, 北京.
- [10] Breusch, T.S. and Pagan, A.R. (1979) A simple test for heteroscedasticity and random coefficient variation. Econometrica, 47, 1287-1294.
- [11] Breusch, T.S. and Pagan, A.R. (1980) The lagrange multiplier test and its applications to model specification in econometrics. The Review of Economic Studies, 47, 239-253.
- [12] 杨振宁, 朱镇斌 (2006) 我国农业经济发展影响因素的实证研究. 经济纵横, 10, 49-52.
- [13] 韩雪峰 (2009) 新时期促进我国农民收入增长问题分析. 农业经济, 5, 41-42.
- [14] 刘进宝, 张延君 (2004) 农业收入影响因素的计量经济分析. 经济论坛, 5, 117-118.