Computer Science and Application
Vol.
09
No.
12
(
2019
), Article ID:
33293
,
10
pages
10.12677/CSA.2019.912251
End-to-End Multi-Entity Relationship Extraction for Chinese Text
Hao Yang
Institute of Network Technology, Beijing University of Posts and Telecommunications, Beijing

Received: Nov. 14th, 2019; accepted: Nov. 29th, 2019; published: Dec. 5th, 2019

ABSTRACT
Relationship extraction can obtain key information in the text. Entity relationship extraction is a method to identify entities in unstructured text and extract the relationships between entity pairs. For the traditional relationship extraction with the help of external NLP tools and local classification, the end-to-end entity relationship extraction model can reduce the error propagation between pipeline models and obtain better results. An end-to-end entity relationship extraction model based on BiLSTM was designed to solve the problem of multiple entity pairs in Chinese texts by making decisions on the possibility of corresponding entities and relationships. In Chinese text, three kinds of entity recognition and 10 kinds of relation extraction are realized. The experimental results show that this method can achieve a better result of multi-entity relation extraction without manual construction of complex features.
Keywords:Entity Relation Extraction, End-to-End, BiLSTM, Multiple Entity Pairs
面向中文的端到端多实体关系提取研究
杨 浩
北京邮电大学网络技术研究院,北京
收稿日期:2019年11月14日;录用日期:2019年11月29日;发布日期:2019年12月5日

摘 要
关系提取可以获得文本中的关键信息。实体关系提取是在非结构化文本识别出实体并提取出实体对之间关系的方法。针对传统的关系提取借助外部NLP工具和局部分类等问题,端到端的实体关系提取模型可以减少管道模型之间的错误传播,获得更好的效果。设计一种基于BiLSTM的端到端的实体关系提取模型,通过决策对应实体和关系的可能性,解决中文文本中的多实体对的问题。在中文文本上,实现了3种实体识别10类关系提取。实验结果表明该方法无需人工构建复杂特征即可得到较好的多实体对关系抽取效果。
关键词 :实体关系提取,端到端,BiLSTM,多实体对

Copyright © 2019 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
随着互联网上非结构化文本数据越来越多,关系提取对文本数据的提取和分析也扮演着愈加重要的作用。关系提取短文本中的信息以三元组的形式<实体,关系,实体>表示,获取的三元组不仅体现出实体之间的关系,还能广泛的运用到知识图谱、智能搜索引擎、自动问答系统等领域 [1] [2] [3] [4]。
早期的关系提取 [5] [6] [7] [8] 不仅需要人工大量的选定特征,并且因为中文句子的词法、句法、语法等方面的复杂性,很难适应大规模的中文关系提取。随着深度学习的兴起,神经网络模型可以自动提取文本中的特征,可以大量减少人工提取特征的工作,也能更好的适应大规模中文数据的关系提取工作,这也是当前中文短文本中的关系提取的主流方法 [9]。但是这种管道模型只是对实体对之间的关系进行提取,忽略了前置步骤的实体识别,这样不仅忽略了文本中的实体前置信息,还可能造成管道方法中的错误传播,同时我们还要对需要预测关系的实体做出标记,这也会造成巨大的人工成本。
除了把实体和关系抽取看作两个分开的任务的管道模型,还有整合实体识别和关系抽取的联合模型 [10] [11] [12]。针对文本中可能会包含多个实体对以及每个实体标识多个关系的问题,我们设计端到端的模型可以同时提取同一短文本中的实体和关系,其中实体可能参与到多个关系中。
为此我们设计一种端到端的实体关系提取模型,可以联合性的提取出实体和实体之间的关系。这种实体关系提取模型避免了依赖外部自然语言处理工具和手工特征造成的错误传播,同时整合整个句子的语法信息来促进全局的特征信息学习。为了针对端到端的关系提取,我们建立了参数共享的神经模型,通过BiLSTM提取文本特征,以更好地学习上下文语义表示。由于中文文本的复杂性,一个句子中可能存在多个实体,所以会存在一个句子中含有多个实体关系对,特定实体与多个实体产生关系,为了解决这样的问题,本文采用同时计算对应实体和关系类型的得分,进而得到特定实体与其对应实体和关系类型的概率。如图1所示,是一个句子的输入与输出,“钱钟书和杨绛结婚之后诞下了爱女钱瑗”这个句子包含人名实体“钱钟书”、“杨绛”和“钱瑗”,用实体的最后一个字符表示该实体的位置,分别计算实体与对应实体及关系的概率。实体对最大概率的关系就是提取出来的三元组关系对,最后提取出实体关系对为<钱钟书,夫妻,杨绛>,<钱钟书,父母,钱瑗>和<杨绛,父母,杨绛>。
本文提出了一种端到端的关系提取模型,减少关系提取手工特征和手工标注的工作量,避免依赖外部工具造成的错误传播,整合句子中的依赖信息使实体识别和关系提取之间相互促进。由于中文文本中词向量存在稀疏性等问题,所以本文采用字向量输入。同时本文解决一个句子中的多实体关系提取问题以及一个实体具有多个实体关系对。本文在来自互联网上的中文短文本数据集上对该模型进行了实验,实验结果证明了该方法在多实体关系提取上达到了很好的效果。

Figure 1. Input and output of sentences
图1. 句子的输入和输出
2. 相关研究
关系提取是自然语言处理中的一个重要子任务,可以应用到许多NLP任务上,比如知识图谱、自动问答等领域。实体识别和关系提取是从非结构化文本中提取信息的两个中心任务。目前主流的关系提取是依赖于双向LSTM编码的深度学习方法。传统的关系提取方法是将实体识别作为管道中的一个前身步骤,预测给定实体之间的关系。为了提高性能和更加简便,常常会考虑端到端的进行实体关系的提取。
现有的关系提取方法也可以分为基于手工特征的方法和基于神经网络的方法。Rink和Harabagiu [13] 设计了16种特性,这些特性通过使用多种监督NLP工具包和资源来提取,该工作利用了从外部语料库中提取的许多特征,用于支持向量机分类器。近年来,深度神经网络在在关系提取方面也有较大进展。在处理短文本的时候,卷积神经网络(CNN)是常用的神经网络模型。文献 [14] [15] [16] [17] 都使用了CNN自动从句子中学习特征,不需要人工构建复杂的特征工程,最小化对外部资源的依赖。随后为了解决长句子之间重要的语义依赖关系和记忆功能,又引入了递归神经网络 [18] [19] 和长短时记忆网络 [20]。张和王 [21] 提出利用双向RNN从原始文本数据中学习关系模式。虽然双向RNN可以同时访问过去和未来的上下文信息,但是由于梯度消失问题,上下文的范围是有限的。PengZhou [22] 等人提出了基于注意力的双向长短时记忆网络来捕捉句子中最重要的语义信息,无需使用额外的知识和NLP系统。
传统的关系提取方法是将实体识别作为管道中的一个前身步骤。解决实体及其关系提取问题的主要框架是管道法和联合提取法。联合提取法就是在提供文本输入的情况下,共同识别实体及其之间的关系,这也叫做端到端模型。Miwa和Bansal [23] 提出了一个由基于长短时记忆网络和树状结构LSTM层组成神经网络模型,用于实体识别,并使用两个组件之间共享参数进行关系分类。他们的模型严重依赖于依赖树的构建。Zheng S [24] 等人提出了一种混合神经网络来进行实体识别和关系提取。他们的模型包括实体识别模块和关系提取模块,这两个模块通过共享BiLSTM编码层的参数来促进实体识别模块和关系提取模块的相关性,并且没有复杂的特征工程。
3. 模型设计
实体关系提取的端到端模型能够减少错误信息的传播和对外部自然语言处理工具的依赖,并且端到端模型对自然语言处理任务的落地应用也有着巨大的价值。端到端模型能够同时识别实体和实体对之间的关系。由于文本的复杂性,输入当中经常会存在包含多个实体对以及特定实体与多个实体同时存在关系的问题,为此我们拼接实体识别和关系提取的模型,在得出实体的基础上预测实体对及它们之间的关系,分别计算特定实体与对应实体和关系类型的得分与概率,从而判定该实体对的关系类型。模型的基本结构如下图2所示。包括字向量表示层,双向序列LSTM (BiLSTM)层,CRF层,sigmoid评分层。
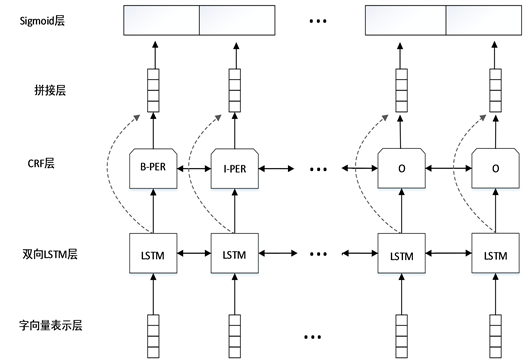
Figure 2. End-to-end entity relation extraction model structure
图2. 端到端实体关系提取模型结构

Figure 3. Working flow chart of the model
图3. 模型工作流程图
我们的模型的输入是一个字符序列,然后将其表示为单词向量。BiLSTM层能够为每个通过LSTM结构合并上下文的单词提取更复杂的表示。然后CRF和sigmoid层就能够生成命名实体识别和关系提取这两个任务的输出,其中CRF分类每个字符所属实体的类型BI0,B代表的是实体的第一个字符,I表示的是实体中除开头字符的其它字符,O表示不属于实体的的字符,经过CRF层之后就可以识别出句子中的实体。我们用实体中最后一个字符表示这个实体,然后将该实体经过BiLSTM层提取的特征与其它每一个实体经过BiLSTM层提取的特征融合,并计算它与每一个预定义标签的得分,经过sigmoid层得到每个标签的概率,标签概率最大且超过阈值就说明该标签是这两个实体的之间的关系。每个字符的输出是双重的:一个实体识别标签和一组元组组成的标记实体和它们之间的关系的类型。由于我们假设了基于标记的编码,所以我们只将实体的最后一个标记作为另一个标记对应的实体,从而消除了冗余关系。该模型的工作流程如图3所示。
3.1. 数据预处理
本文的数据是通过搜集互联网上面的中文文本数据,主要包括百度百科,新浪微博和搜狐等媒体。我们对数据进行清洗、筛选出比较合理以及富含实体和语义的文本,并在已经预训练好的字向量表上再一次加载训练该文本。对文本进行实体标注和关系标注之后完成了数据预处理的工作。
3.2. 字向量表示层
在输入中文句子以前,我们需要将句子转化为一个标记序列。当给定一个句子 作为输入序列时,嵌入层将句子中的每个字符映射为一个向量。目前常用的工具是word2vec。word2vec是一种浅层神经网络模型,它可以从大量的语料库中以无监督的方式学习语义知识,为语料库中的单词产生一个能表达语义的向量。word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。嵌入其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中。
在中文文本里,为了避免引入外部自然语言处理工具,造成错误的传播,本文将使用字嵌入向量。
当输入一个句子 时,我们根据已经预训练好的word2vec跳跃表,获得句子中每个字符对应的字向量。输入标记序列中有丰富的语料信息,为后续的各层提供上下文信息。
3.3. BiLSTM编码层
当输入的句子经过嵌入层向量化之后,就要对字向量的信息进行编码。我们用的是BiLSTM模型。一个单词序列可以表示为 ,n为给定句子的长度。在字嵌入层之后,有两个并行的LSTM层:前向LSTM层和后向LSTM层。对于每个单词的wt,前向层通过考虑从w1到wt的上下文单词信息对wt进行编码,并将其标记为ht。同样的,后向层将根据上下文单词信息从wn到wt进行编码,标记为ht。
LSTM模型能够很好的捕获较长距离的依赖。LSTM主要包括细胞状态,临时细胞状态,隐层状态,遗忘门,记忆门和输出门。LSTM主要通过对细胞状态中信息遗忘和记忆新的信息来进行信息的传递,有用的信息保留,无用的信息遗忘。LSTM模型适合对时序数据的建模。但是LSTM无法编码从后到前的信息,所以采用BiLSTM可以更好的编码上下文信息。LSTM模型的运行细节如下公式所示:
(1)
(2)
(3)
(4)
(5)
(6)
在每个时间步,lstm内存块是用来计算当前隐藏向量ht 基于前面的隐藏向量ht1 ,前面的细胞向量ct1 和当前输入字嵌入wt ,就可以表示为: 和 。最后,我们可以整
合ht-和ht+来表示第t个单词的编码信息,表示为 。
3.4. 实体识别层
经过BiLSTM编码之后,要识别出句子中的实体。
实体识别任务可以描述为一个序列标记问题,标记主要分为BIO。B代表每个实体的开头,I代表每个实体的非开头部分,O代表这个字符不属于实体。我们为句子中的每个字符分配一个标记,每个实体由句子中的多个连续标记组成。本文主要进行人名实体、地名实体和组织实体的识别。
在BiLSTM对嵌入层表示的句向量矩阵进行提取特征信息之后,连接一个softmax层,输出各个标记的概率,预测每个字符的实体类型。但是softmax只能预测出文本序列与标记的关系,但是文本序列标记之间有很强的依赖性,要符合标记之间的规则。比如说标记I-ORG后不能跟一个I-PER标记。这个时候CRF中的转移矩阵可以用来表示标记之间的依赖关系,当违反转移矩阵之间的关系时,得分就会很低,即概率很小,那么这种标记就会被舍弃。线性链CRF的得分公式被定义为如下:
(7)
CRF得分主要由两部分组成,一部分是LSTM预测标签得分,另一部分是表示从一个标签到另一个标签的CRF转移矩阵得分,用softmax分类器计算各个实体标签的概率,得到交叉熵损失函数Lner ,通过最小化损失函数优化实体识别模型的参数。
3.5. 关系提取层
在本层,关系提取主要解决的是多实体对的关系提取问题。当提取出句子中的实体之后,下一步是预测实体之间的关系。除了将句子原本的信息输入以外,为了加强实体和关系的联系,实体标记的信息也要输入到关系提取层。
在一般的句子中,一个实体可能有多个实体关系对。给定输入的序列以及预定义好的关系标签集合,我们的目标是识别序列中每个字符向量中可能的对应实体以及最可能的对应的关系标签,我们选取结合对应实体和关系标签对应的概率超过阈值则是我们想要获取的结果,是提取出的一个实体关系对。我们预测三元组是预测每一个字符的对应的实体及它们对应的关系。计算字符wi 和wj之间的关系标签rk得分公式如下:
(8)
上标 是用于关系标签的表示法。f是激励函数。然后将公式的计算得分经过sigmoid函数处理,可以得到字符wi与字符wj之间关系为rk的概率P:
(9)
在训练的过程中,我们最小化句子中关系提取的交叉熵损失函数,来优化模型的参数:
(10)
m是关系标签集中的关系数量。经过训练后,让实体wi 对应的实体wj和关系标签rk的估计联合概率超过阈值,我们可以预测多个关系对。对于端到端实体关系提取任务,我们计算的目标函数是Lner + Lrc 。
4. 实验
为了验证多实体关系提取的端到端模型的的有效性,我们在收集和预处理过的中文数据集上进行实验。
4.1. 实验环境和评价指标
实验环境配置如表1所示。对实体关系提取效果的评价指标主要有准确率P、召回率R和F值三个指标对进行评价。它们的计算公式如下:
(11)
(12)
(13)

Table 1. Experimental environment
表1. 实验环境
4.2. 实验数据
实验数据来源于网上的资料和媒体,包括新浪微博,百度百科和搜狐等媒体。对搜集的数据,我们筛选语义比较丰富,包含明显的实体及关系的语句作为数据集。我们一共收集了28.3万字,3840句,包含8729个实体关系对。
实体类型标注如表2所示。实体类型主要标注为BIO,B代表一个实体的开头字符,I代表一个实体的其它部分的字符,O代表非实体字符。后缀包括PER、LOC和ORG,分别代表人名,地名,组织名。
Table 2. Entity types
表2. 实体类型
关系类型如表3所示,分为十类。其中“父母”、“师生”、“夫妻”、“手足”、“同学”是人名实体之间的关系。“合作”和“竞争”是人名实体之间和组织实体之间的关系。“成员”是人名实体和组织实体之间的关系。“领导”是人名实体之间和人名实体和组织实体或地名实体之间的关系。“去过”是人名实体和地名实体之间的关系。
Table 3. Relationship types
表3. 关系类型
将数据进行预处理后,进行10折交叉验证,随机将数据切分成10个互不相交的大小相同的子集,然后利用9个子集的数据作为训练集,1个子集的数据作为测试集,最后选出S次测评中平均测试误差最小的模型。本文随机选取其中3456句作为训练集,384句作为测试集。
4.3. 实验设计
为了验证本文提出的端到端的多实体关系提取模型的效果和性能,除了本文提出的模型之外,还包括三组对比实验,分别是BiLSTM + CRF的实体识别实验、LSTM + softmax的关系提取实验和单实体对的端到端实体关系提取实验。
对比实验1是实体识别实验,将预训练的字向量矩阵用BiLSTM神经网络提取特征信息之后,采用CRF作为分类器进行实体的识别。
对比实验2是关系提取实验,先把数据集中的句子当中的实体标注出来,然后使用BiLSTM对句子中对应的向量矩阵进行特征提取,然后用softmax对标注出的实体进行关系分类,从而获得实体对应的关系。
对比实验3是单实体端到端关系提取实验,使用文献 [24] 的模型,每个句子中只预测两个实体及其对应的关系。句子中的向量矩阵用BiLSTM提取特征之后,将BiLSTM的参数作为共享参数,再分别做实体识别和关系分类。
4.4. 实验结果及分析
实验结果如表4所示,在中文数据集上我们分别对比了四组实验。
实验中分别运行了经典的命名实体识别模型和关系提取模型。在传统的关系提取模型中采用的是管道模型,即先识别命名实体,再提取出命名实体之间的关系,如果忽略输入句子中的实体复杂性和依赖性,则管道型关系提取公式如公式:
(14)
Table 4. Experimental results
表4. 实验结果
由公式14可知,管道型的关系提取,F1值为实体识别和关系提取的F1乘积,端到端共享参数和端到端多实体对模型的F1都比实体识别和关系提取的F1乘积值60%高,端到端模型提取实体对关系效果要优于管道型实体对关系提取的效果,可见当命名实体识别和关系提取共享参数,同时对参数调优时会提升模型的训练效果。
端到端多实体对模型的训练效果明显高于端到端共享参数模型的提取效果,可见数据的标注方法不仅解决句子中多实体对的关系提取问题,并且实体标注信息对实体识别和关系提取的性能有很大的提升作用。
5. 结语
为了更好的将关系提取应用到实际语料中去,避免关系提取前大量的数据预处理,且一个句子中可能包含多个实体对,本文提出了一个端到端的多实体对关系提取的模型,采用了BiLSTM + CRF模型识别实体,然后将识别的实体信息和实体标注信息以及位置信息都作为输入的一部分用来训练关系提取模型,从而获得更好的效果。通过实验对比,端到端的多实体对关系提取模型优于传统的管道型关系提取模型和共享参数的端到端实体关系提取模型。
对于以后的工作,我们会构建一个更大的语料库以及更多的实体关系来训练模型,可以提取出更多关系的实体对,应用在更多的领域。除此之外,还会优化模型,比如使用bert来代替句子的向量化表示和提取句子的信息特征,来进一步优化模型,提高准确率。
文章引用
杨 浩. 面向中文的端到端多实体关系提取研究
End-to-End Multi-Entity Relationship Extraction for Chinese Text[J]. 计算机科学与应用, 2019, 09(12): 2256-2265. https://doi.org/10.12677/CSA.2019.912251
参考文献
- 1. 王超. 基于深度学习的中文微博人物关系图谱的研究与实现[D]: [硕士学位论文]. 武汉: 武汉邮电科学研究院, 2018.
- 2. 唐敏. 基于深度学习的中文实体关系抽取方法研究[D]: [硕士学位论文]. 成都: 西南交通大学, 2018.
- 3. 谢星辰. 互联网人物属性识别与融合方法研究[D]: [硕士学位论文]. 成都: 电子科技大学, 2018.
- 4. 黄蓓静. 深度学习技术在中文人物关系抽取中的应用研究[D]: [硕士学位论文]. 上海: 华东师范大学, 2017.
- 5. Mintz, M., Bills, S., Snow, R. and Jurafsky, D. (2009) Distant Supervision for Relation Extraction without Labeled Data. Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2-7 August 2009, 1003-1011. https://doi.org/10.3115/1690219.1690287
- 6. Culotta, A., McCallum, A. and Betz, J. (2006) Integrating Probabil-istic Extraction Models and Data Mining to Discover Relations and Patterns in Text. Proceedings of the Main Conference on Human Language Technology Conference of the North American Chapter of the Association of Computational Lin-guistics, New York, 4-9 June 2006, 296-303. https://doi.org/10.3115/1220835.1220873
- 7. Doddington, G.R., Mitchell, A., Przybocki, M.A., et al. (2004) The Automatic Content Extraction (ACE) Program-Tasks, Data, and Evaluation. Proceedings of the Fourth International Conference on Language Resources and Evaluation, Lisbon, Portugal.
- 8. Zelenko, D., Aone, C. and Richardella, A. (2003) Kernel Methods for Relation Extraction. Journal of Machine Learning Research, 3, 1083-1106.
- 9. Gábor, K., Buscaldi, D., Schumann, A.K., et al. (2018) Semeval-2018 Task 7: Semantic Relation Extraction and Classification in Scientific Papers. Proceedings of The 12th International Workshop on Semantic Evaluation, New Orleans, LA, 679-688. https://doi.org/10.18653/v1/S18-1111
- 10. Zhang, M., Zhang, Y. and Fu, G. (2017) End-to-End Neural Relation Extraction with Global Optimization. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 1730-1740. https://doi.org/10.18653/v1/D17-1182
- 11. Ammar, W., Peters, M., Bhagavatula, C., et al. (2017) The AI2 System at SemEval-2017 Task 10 (ScienceIE): Semi-Supervised End-to-End Entity and Relation Extraction. Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, 592-596. https://doi.org/10.18653/v1/S17-2097
- 12. Ren, X., Wu, Z., He, W., et al. (2017) CoType: Joint Extraction of Typed Entities and Relations with Knowledge Bases. Proceedings of the 26th International Confer-ence on World Wide Web, Perth, Australia, 3-7 April 2017, 1015-1024. https://doi.org/10.1145/3038912.3052708
- 13. Rink, B. and Harabagiu, S. (2010) Utd: Classifying Semantic Rela-tions by Combining Lexical and Semantic Resources. Proceedings of the 5th International Workshop on Semantic Evalu-ation, Los Angeles, CA, 15-16 July 2010, 256-259.
- 14. Tu, C., Zhang, Z., Liu, Z. and Sun, M. (2017) TransNet: Translation-Based Network Representation Learning for Social Relation Extraction. Proceedings of International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, 2864-2870. https://doi.org/10.24963/ijcai.2017/399
- 15. 司文豪, 贾雷萍, 戚银城. 基于卷积神经网络的中文人物关系抽取方法[J]. 计算机与现代化, 2018(9): 17-20.
- 16. Santos, C.N., Xiang, B. and Zhou, B. (2015) Classifying Relations by Ranking with Convolutional Neural Networks. arXiv preprint arXiv:1504.06580.
- 17. Nguyen, T.H. and Grishman, R. (2015) Relation Extraction: Perspec-tive from Convolutional Neural Networks. Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, Co, 39-48. https://doi.org/10.3115/v1/W15-1506
- 18. Meng, L. and Wu, B. (2017) Core Discovery and Relation Extraction in Organization Profiling. 2017 13th International Conference on Semantics, Knowledge and Grids, Beijing, 13-14 August 2017, 219-222. https://doi.org/10.1109/SKG.2017.00045
- 19. Rotsztejn, J., Hollenstein, N. and Zhang, C. (2018) ETH-DS3Lab at SemEval-2018 Task 7: Effectively Combining Recurrent and Convolutional Neural Networks for Relation Classification and Extraction. arXiv Preprint arXiv:1804.02042. https://doi.org/10.18653/v1/S18-1112
- 20. Peng, N., Poon, H., Quirk, C., Toutanova, K. and Yih, W.-T. (2017) Cross-Sentence N-Ary Relation Extraction with Graph LSTMS. arXiv Preprint arXiv:1708.03743. https://doi.org/10.1162/tacl_a_00049
- 21. Zhang, D.X. and Wang, D. (2015) Relation Classification via Recurrent Neural Network. arXiv Preprint arXiv:1508.01006.
- 22. Zhou, P., Shi, W., Tian, J., et al. (2016) Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2, 207-212. https://doi.org/10.18653/v1/P16-2034
- 23. Miwa, M. and Bansal, M. (2016) End-to-End Relation Extraction Using LSTMS on Sequences and Tree Structures. arXiv Preprint arXiv:1601.00770. https://doi.org/10.18653/v1/P16-1105
- 24. Zheng, S., Hao, Y., Lu, D., et al. (2017) Joint Entity and Relation Ex-traction Based on a Hybrid Neural Network. Neurocomputing, 257, 59-66. https://doi.org/10.1016/j.neucom.2016.12.075