Computer Science and Application
Vol.
10
No.
04
(
2020
), Article ID:
35012
,
6
pages
10.12677/CSA.2020.104068
A Faster Lightweight Face Recognition Model
Shuai Peng1, Hongbo Huang1,2, Weijun Chen1, Shuwen Pan1,2
1Computer School, Beijing Information Science and Technology University, Beijing
2Institute of Computing Intelligence, Beijing Information Science and Technology University, Beijing

Received: Mar. 23rd, 2020; accepted: Apr. 7th, 2020; published: Apr. 14th, 2020

ABSTRACT
With the development and application of deep learning-based approaches, face recognition algorithms have already been used on devices with sufficient computing resources and achieved high accuracy and fast speed. Face recognition models based on deep learning have better recognition accuracy, but requiring a large amount of computing resources. Aiming to this problem, this paper designs a model called Lite-Inception-ResNet, which is a lightweight network model based on deep learning algorithms and requires much fewer computing resources. The proposed model is based on the Inception-ResNet model and improved in network architecture and activation functions. Experiments on VGGFace2 and LFW show that the Lite-Inception-ResNet model can reduce the amount of parameters by 88.2% and the amount of calculation by 76.5% with only a 0.1% accuracy reduction, making the model more suitable for devices with less computing resources.
Keywords:Deep Learning, Face Recognition, Lightweight

一种更快捷的轻量级人脸识别模型
彭帅1,黄宏博1,2,陈伟骏1,潘淑文1,2
1北京信息科技大学计算机学院,北京
2北京信息科技大学计算智能研究所,北京

收稿日期:2020年3月23日;录用日期:2020年4月7日;发布日期:2020年4月14日

摘 要
随着基于深度学习的人脸识别算法的发展和应用,人脸识别算法已经可以运用在计算资源充足的设备上并取得很高的精度和较快的速度,但是在计算资源受限设备上的应用有诸多困难。基于深度学习的人脸识别模型有着更好的识别精度,但是大多数基于深度学习的模型均需要大量的计算资源来支持运行。本文针对这一问题,设计出一个占用少量计算资源的基于深度学习算法的轻量级网络模型Lite-Inception-ResNet,该模型基于具有良好性能的Inception-ResNet模型,在保持原模型良好性能的基础上对卷积核和网络架构进行了优化和重新设计,并选用了性能更好的激活函数。在VGGFace2和LFW上的实验表明,新模型可以在LFW数据集上仅降低0.1%正确率的情况下减少88.2%的参数量和76.5%的计算量,使该模型可以较好地应用于计算资源较少的设备上。
关键词 :深度学习,人脸识别,轻量级

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
近年来,随着深度学习的发展,基于深度学习的人脸识别方法在现实中得到了广泛的应用。尤其在公共安全、智慧城市和金融交易等方面,对人脸识别技术的需求与日俱增。当前基于深度学习的人脸识别算法在精度上已经可以满足各类需求,但是其需要用到的计算量是非常大的,对运用的计算设备有着较高的需求,尤其高精确度的人脸识别模型通常需要用到大型的并行运算设备,这对于将模型迁移到计算资源少的小型设备上是一种挑战。因此,如何减少模型消耗的计算成本,设计出在计算资源少的小型设备上能高效运行的轻量级网络模型,已经成为进一步研究的热点之一。
轻量级网络模型吸引了大量研究人员的关注,目前已经取得不少的研究成果,如通过裁切、压缩和编码来降低网络模型的参数量和计算量的方法 [1]。另有一些工作如MobileNet [2] 和ShuffleNet [3] 等则通过重新设计网络结构,引入逐通道卷积和逐点卷积等方式来降低参数量。这些模型在降低参数量和计算量的同时,其识别率等性能也下降明显,使得如何在轻量级网络模型的性能和计算复杂度之间取得恰当的均衡成为一个新问题。本文针对这一问题,提出一个以大型网络架构Inception-ResNet [4] 为基础,在识别率几乎没有下降的情况下优化出的一个轻量级网络模型Lite-Inception-ResNet,在性能和计算量之间取得了更好的平衡。
2. 相关研究与方法基础
2.1. 人脸识别相关进展
近几年,基于卷积神经网络的方法已经成为人脸识别的主流方法,其主要分为两条研究路线,一条是对于网络架构进行改进的方法 [5] [6],通过改进网络结构来提升模型的性能和速度。另一条是对损失函数进行改进的方法 [7] [8] [9],通过改进损失函数来增强网络在大规模人脸识别上的区分度。随着模型在精度上的不断提升,为了使网络结构能更好的运用于小型设备上,对于轻量级网络结构的研究 [2] [3] 也与日俱增。
2.2. Inception-ResNet架构
Inception-resnet是由Google提出的一个卷积神经网络架构,其有v1和v2两个版本,该网络架构由几个简单的卷积层、下采样层和几十个Inception-resnet模块所组成。Inception-resnet模块的设计思路源于GoogLeNet [10] 中的Inception模块和ResNet [11] 中的残差思想,每个Inception-resnet模块均由一个Inception模块和残差直连组成。Inception模块可以从特征图里获取到不同尺度的特征信息,残差思想则可以保留下更多前几层网络所获取到的特征信息,并使网络得以训练的更深。结合了Inception模块和残差思想的Inception-resnet模块可以使整体网络拥有更为优秀的特征提取能力。
2.3. PReLU
PReLU [12] 是由何恺明等人提出的一种可以被训练的激活函数,其设计思路源于LeakyReLU [13]。常用的激活函数ReLU是将特征图中的所有负值置于零,这可能会使特征图损失部分提取出的特征信息。LeakyReLU则是将特征图中的所有负值乘上同一个固定的常数α,这样既能起到非线性的作用,同时减少特征图的信息损失。PReLU则是更进一步将这个α设置为可训练参数,这样使得网络拥有更好的可训练性。由于Leaky ReLU和PReLU均是只增加一个参数,所以如果将常用激活函数ReLU改进为Leaky ReLU或是PReLU,则可以更好的发挥网络在特征提取上的性能,而增加的参数量和计算量是近乎忽略不计的。
3. 网络架构设计
本文以Inception-ResNet v2为基础网络架构,设计出一个参数量远比Inception-ResNet v2少的网络结构Lite-Inception-ResNet。Inception-Resnet v2网络结构由一个基础模块和四十个Inception-Resnet模块还有两个下采样Inception模块所组成,其中基础模块由几个卷积层和池化层组成,下采样Inception模块则是包含了下采样操作的Inception模块。本文提出的Lite-Inception-ResNet则是在此基础之上适当减少参数量并将使用的Inception-Resnet模块数减少到了十三个。Lite-Inception-ResNet的网络架构如表1所示。在模型的参数总量上,Inception-ResNet v2有55 M的参数量,而Lite-Inception-ResNet缩减到了6.5 M的参数量,在总参数量上有8.4倍的缩减。

Table 1. The network architecture of Lite-Inception-ResNet
表1. Lite-Inception-ResNet的网络架构
为进一步优化模型的性能,在经过详细对比实验的基础上,本文提出在Lite-Inception-ResNet中使用PReLU激活函数替换Inception-ResNet模型的ReLU激活函数。这个优化只增加了上百个参数,对于总参数量而言是微乎其微的。通过实验验证了PReLU激活函数对本文提出的模型在性能上有明显提升。
网络模型在最后一层输出的人脸特征向量为512维的特征向量,这样可以使模型提取出更具有泛化性的特征来表征人脸的特征信息。训练时模型时在最后加的损失函数用的是Softmax Loss,通过Softmax Loss来指导整个网络模型的训练和参数权值更新。
4. 实验及结果
4.1. 数据集及其处理
本文使用的训练数据集是VGGFace2 [14] 数据集。VGGFace2是当前大规模人脸数据集之一,包括九千多个人的三百多万张人脸图像,且数据集质量较好,总体数据包含的噪声较少。
测试数据集使用的是LFW [15] [16] 数据集。LFW数据集是专门用来测试算法性能的人脸图片数据集,它包含一万多无约束的人脸照片。其所有人脸照片都标注有人物名字,且进行过简单的处理,保证每张图片中只有一张完整人脸。在该数据集上可以较好的测试小型人脸识别网络模型的性能。
所有的训练数据集及测试数据集均通过MTCNN [17] 在同一标准下裁剪出标准的人脸图像,以使模型对人脸特征的提取更为一致。
4.2. 模型训练细节
模型的训练是在NVidia GeForce RTX 2080Ti GPU上进行的,使用TensorFlow [18] 框架来构建和更新网络模型。网络模型的输入图像大小设定为163 × 163,值得一提的是,为更进一步提升模型的泛化性能,我们在训练的时候对图像进行了随机水平翻转。每个模型均训练100轮,每一轮训练1000次迭代并在该轮结束时在LFW数据集上验证一次,每次迭代的batch size大小设定为100,即每次迭代用100张图片来训练网络。使用的优化方法是Batch Gradient Descent,初始学习率为0.05,每20轮下降一次学习率,每次下降学习率乘上0.2。
4.3. 实验结果及分析
实验针对三个模型进行观察比对及分析,分别是Inception-ResNet v2模型、Lite-Inception-ResNet模型和Lite-Inception-ResNet (+PReLU)模型。在训练过程中,使用TensorBoard [18] 对其进行可视化来观察训练效果,如图1所示,其中Value是模型在LFW数据集上的正确率。从图中可以看出,Lite-Inception-ResNet模型并没有因为网络的缩减而明显影响网络模型的训练,缩减后的模型在性能上并没有显著的劣化。
实验进行了两组比对,第一组是Inception-ResNet v2模型和Lite-Inception-ResNet模型的比对,其参数量、计算量及在LFW数据集上的测试结果比对如表2所示。第二组是Lite-Inception-ResNet模型和Lite-Inception-ResNet (+PReLU)模型进行对比,其在LFW数据集上的测试结果比对如表3所示。
由表2可以看出,我们的模型在参数量和计算量上分别减少了7.5倍和3.3倍,其在LFW上的精确度有0.43%的损失。对网络结构的简化虽然导致了在精确度上有所降低,但是其影响并不显著,仍可以达到较高的识别精度。其6.5 M的参数量和628 M的计算量显著的减小了对计算资源的依赖,可以布置在更多计算资源少的设备上,使模型有更大的应用空间。
在对于模型激活函数的改进上,由表3可以看出,将激活函数从ReLU换成PReLU,可以明显的提升Lite-Inception-ResNet模型的性能,且在参数量和计算量上几乎没有增加。该模型最终仅比Inception-ResNet v2模型相差0.1%的精确度,在参数量和计算量的消耗上则有数量级上的明显降低。实验结果表明Lite-Inception-ResNet的简化是成功的,PReLU的运用对Lite-Inception-ResNet起到了非常积极的作用,Lite-Inception-ResNet (+PReLU)在保持识别率几乎没有下降的情况下,显著减少了网络参数量和计算量,加大了模型的泛用性。
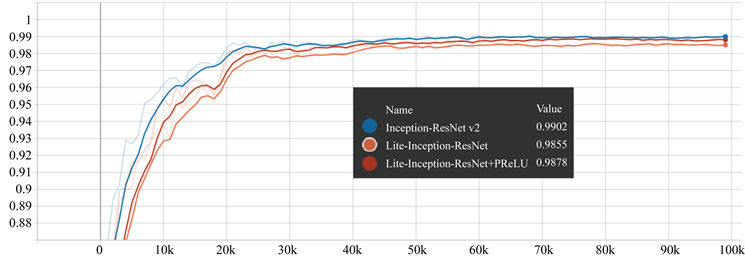
Figure 1. Validation results of the model on the LFW dataset during training
图1. 训练过程中模型在LFW数据集上的验证结果
Table 2. The first set of comparative models and their test results on LFW
表2. 第一组比较模型及其在LFW上的测试结果
Table 3. The second set of comparative models and their test results on LFW
表3. 第二组比较模型及其在LFW上的测试结果
5. 结论
本文针对目前基于深度学习的人脸识别模型普遍需要大量计算资源的问题,设计了一种轻量级的人脸识别模型。该网络模型在保持有较好识别精度的情况下,显著减少了计算量和参数量,使得模型可以应用到计算资源受限的设备上,对于人脸识别算法的更进一步推广和普及具有积极意义。
基金项目
北京市教委科技计划一般项目(KM201811232024 );北京信息科技大学促进高校内涵发展“信息+”项目–多源光谱生物特征活体识别平台建设;北京信息科技大学高教研究重点项目(2019GJZD01)。
文章引用
彭 帅,黄宏博,陈伟骏,潘淑文. 一种更快捷的轻量级人脸识别模型
A Faster Lightweight Face Recognition Model[J]. 计算机科学与应用, 2020, 10(04): 659-664. https://doi.org/10.12677/CSA.2020.104068
参考文献
- 1. Han, S., Mao, H. and Dally, W.J. (2015) Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv Preprint arXiv:1510.00149.
- 2. Howard, A., Sandler, M., Chu, G., et al. (2019) Searching for Mobile Net v3. Proceedings of the IEEE International Conference on Computer Vision, 1314-1324. https://doi.org/10.1109/ICCV.2019.00140
- 3. Ma, N., Zhang, X., Zheng, H.T., et al. (2018) Shuf-flenet v2: Practical Guidelines for Efficient CNN Architecture Design. Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 116-131. https://doi.org/10.1007/978-3-030-01264-9_8
- 4. Szegedy, C., Ioffe, S., Vanhoucke, V., et al. (2017) Incep-tion-v4, Inception-Resnet and the Impact of Residual Connections on Learning. Thirty-First AAAI Conference on Arti-ficial Intelligence, San Francisco, CA, 4-9 February 2017.
- 5. Taigman, Y., Yang, M., Ranzato, M.A., et al. (2014) Deepface: Closing the Gap to Human-Level Performance in Face Verification. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1701-1708. https://doi.org/10.1109/CVPR.2014.220
- 6. Parkhi, O.M., Vedaldi, A. and Zisserman, A. (2015) Deep Face Recognition. https://doi.org/10.5244/C.29.41
- 7. Wang, F., Cheng, J., Liu, W., et al. (2018) Additive Margin Softmax for Face Verification. IEEE Signal Processing Letters, 25, 926-930. https://doi.org/10.1109/LSP.2018.2822810
- 8. Wang, H., Wang, Y., Zhou, Z., et al. (2018) Cosface: Large Margin Cosine Loss for Deep Face Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 5265-5274. https://doi.org/10.1109/CVPR.2018.00552
- 9. Deng, J., Guo, J., Xue, N., et al. (2019) Arcface: Additive Angular Margin Loss for Deep Face Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4690-4699. https://doi.org/10.1109/CVPR.2019.00482
- 10. Christian, S., Wei, L., Yangqing, J., et al. (2015) Going Deeper with Convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1-9.
- 11. He, K., Zhang, X., Ren, S., et al. (2016) Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, 26 June-1 July 2016, 770-778. https://doi.org/10.1109/CVPR.2016.90
- 12. He, K., Zhang, X., Ren, S., et al. (2015) Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 1026-1034. https://doi.org/10.1109/ICCV.2015.123
- 13. Maas, A.L., Hannun, A.Y. and Ng, A.Y. (2013) Rectifier Nonlinear-ities Improve Neural Network Acoustic Models. Proceedings of ICML, 30, 3.
- 14. Cao, Q., Shen, L., Xie, W., et al. (2018) Vggface2: A Dataset for Recognising Faces across Pose and Age. 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15-19 May 2018, 67-74. https://doi.org/10.1109/FG.2018.00020
- 15. Huang, G.B., Mattar, M., Berg, T., et al. (2008) Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments.
- 16. Huang, G.B. and Learned-Miller, E. (2014) Labeled Faces in the Wild: Updates and New Reporting Procedures. Technical Report, Department of Computer Science, University of Massachusetts, Amherst, MA.
- 17. Zhang, K., Zhang, Z., Li, Z., et al. (2016) Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Processing Letters, 23, 1499-1503. https://doi.org/10.1109/LSP.2016.2603342
- 18. Abadi, M., Agarwal, A., Barham, P., et al. (2016) Tensorflow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv Preprint arXiv:1603.04467.