Hans Journal of Data Mining
Vol.
11
No.
02
(
2021
), Article ID:
41904
,
16
pages
10.12677/HJDM.2021.112009
带有范例元组的交互式数据转换映射方法研究
李静,李贵,李征宇,韩子扬,曹科研
沈阳建筑大学,信息与控制工程学院,辽宁 沈阳
收稿日期:2021年3月19日;录用日期:2021年4月20日;发布日期:2021年4月27日

摘要
模式映射是Web异构大数据集成的重要研究内容之一,通常包含实例层和模式层两方面的研究,本文的研究重点主要集中在模式层。要想在短时间内完全掌握这门技术并且加以运用,这对于那些不熟悉模式转换所涉及的转换语义和语言的非专家用户来说几乎是不可能的。因此,本文在已有的关于数据转换研究成果的基础之上提出了一个适用于非专家用户的交互式模式映射设计框架系统。首先,对由非专家用户提供的不完整的表达性较差的数据转换范例元组进行预处理。然后,再通过简单的用户交互递归地对初始范例元组的有效性进行布尔查询从而得到最终映射规则。其次,本文提出了两种探索所有数据转换映射空间的策略以满足任意用户范例元组。在探索过程中系统会根据与用户交互的结果来保留最适合用户需求的规则,并动态地剪枝搜索空间从而减少与用户交互的次数,本文实验采用来自中国土地市场网的数据集成转换来验证本文方法的有效性。
关键词
Web大数据,数据集成,数据转换,模式映射,布尔查询
Research on Interactive Data Conversion Mapping Method with Example Tuples
Jing Li, Gui Li, Zhengyu Li, Ziyang Han, Keyan Cao
School of Information & Control Engineering, Shenyang Jianzhu University, Shenyang Liaoning

Received: Mar. 19th, 2021; accepted: Apr. 20th, 2021; published: Apr. 27th, 2021

ABSTRACT
Schema mapping is one of the important research contents of heterogeneous big data integration on Web, which usually includes two aspects: instance layer and schema layer. The focus of this paper is mainly on schema layer. It is almost impossible for non-expert users who are not familiar with the semantics and language involved in schema transformation to master this technology and apply it in a short time. Therefore, based on the existing research results on data conversion, this paper proposes an interactive schema mapping design framework system for non-expert users. Firstly, the incomplete data transformation paradigm tuples with poor expressiveness provided by non-expert users are preprocessed. Then, the validity of the initial example tuple is recursively queried by simple user interaction, and the final mapping rules are obtained. Secondly, this paper proposes two strategies to explore the mapping space of all data transformations to satisfy any user paradigm tuple. In the process of exploration, the system will keep the rules that are most suitable for users’ needs according to the results of interaction with users, and prune the search space dynamically to reduce the number of interactions with users. In this experiment, the data integration transformation from China Land Market Network is used to verify the effectiveness of this method.
Keywords:Web Big Data, Data Integration, Data Exchange, Schema Mapping, Boolean Query

Copyright © 2021 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
随着Web数据源的不断丰富和互联网技术的不断提高,Web数据集成技术得到了前所未有的发展。这使得人们获得的Web信息资源大量增加,方便了人们的工作和生活。于此同时,集成来自不同数据源的数据是开发Web大数据应用的重要任务,现行的数据管理应用常常从多个异构Web数据源集成数据,以构建或补充特定领域或多领域的知识库。另外当前的数据集成系统在进行数据交换时至少要解决两方面的问题:一方面是对于映射实例层的研究,主要研究内容是如何寻找无冗余的数据交换解。另一方面是对数据集成过程中模式层的研究,主要涉及映射规则的生成、选择及优化 [1]。
首先,数据交换问题(data exchange problem) [2] 最初是由Fagin、Kolaitis等人提出的并且现如今大部分关于数据交换的研究皆是以此为基础研究而来,即数据交换是在源模式下获取结构化数据,并创建目标模式的实例以尽可能准确地反映源数据的问题。其次他们还给出了一个代数规范,该规范在数据交换问题的所有解决方案中选择一类我们称之为通用的特殊的解决方案。且通用解决方案能够很好的解释源和目标数据。它代表了所有可能的解决方案的整个空间。
其次,针对数据集成中的模式映射的问题。如文献 [3] 模式映射可分为模式匹配和映射生成两步。模式匹配的目标为发现模式元素间的对应关系,映射生成的目标为产生符合模式语义约束的元素集与元素集之间具有蕴含或相等关系的逻辑表达式。其关键在于如何从大量的潜在的映射规则集里面选择一些能最好的解释源数据库和目标数据库的映射规则,并且要尽可能地减少目标数据库里面的数据冗余度。如文献 [4] 提出了一种基于概率软逻辑(PSL)的方法来解决模式映射问题。即在给定元数据约束和数据实例的情况下,从潜在映射空间中选择一组最佳映射。但是该方法通常针对小型映射场景有比较好的性能表现,然而针对大型的映射场景就显得有些乏力,并且该文献里面并未过多地详述初始映射规则集的由来。
本文的研究重点主要集中在初始映射规则集上,实际上模式映射就是一系列从源表到目标表的对应关系的声明性规范,通常采用一阶逻辑。它们构成了关键的数据可编程原语,也使数据库用户能够在大型的共享数据库上使用编程工具来设计映射规则。与此同时,在大多数研究异构或者异源的数据集成问题中,数据库管理专家不可避免的会在考虑这些数据集的不同的映射规则集的前提下对这些不同来源且异构的数据集进行设计、实现以及运用来达到数据集成的目的。此外映射规则还通常在企业IT和一些其他的大数据领域得到广泛的运用。例如在企业IT中,数据分析师(也叫工程映射的开发人员)需要预先定义要访问或集成的不同来源的数据的模式之间的工程映射(数据转换模式) [5]。通过这种预定义,也就意味着对于每个不同的应用来说,这些映射规则都是被精确定义和测试的。目前已经有许多文献对工程映射相关问题进行了研究,首先能想到的就是使用可视化的图形界面来让使用者设计映射规则。就如文献 [6] [7] 中提到的一样,该文献提出了几个基于图形界面的映射设计器,这些映射设计工具能帮助数据分析师以通俗易懂的符号设计不同模式的数据库表之间的映射规则。然而以上提到的解决方法的一个主要的缺点就是,依靠图形语言生成的可编程语言或查询语言中的映射规则都依赖于特定的映射生成工具。因此,同样的图形语言规范可能会被两个或多个不同的映射生成工具转换为不同的、无法比较的声明性映射规范,从而使得两边数据库不一致。为了解决这种数据不匹配问题,在文献 [5] 中提出了模型管理操作符,以提供一种通用的映射设计器,该设计器可以适用于多种数据可编程性的工具,然而该模型管理系统仍然仅仅适用与专家用户。其次就是依靠具有代表性的数据实例 [8] [9] [10] 来生成用户心目中所想的映射规则。即先由熟悉模式映射语义的专家用户提供一组源和目标实例。再通过对这些实例进行分析来生成规则集。但是,这些数据实例通常被预先假定为当前映射的解决方案和所有其他解决方案的典型代表。尽管由于上述方法在映射生成方面取得了一定的进展,但它们都有一个共同的特点,即它们都是面向专家用户的。这些用户通常都熟悉映射生成工具,并拥有完备的数据转换领域、映射的基本语义及其解决方案的知识。最终使得他们能够独立的设计较好的数据库查询代码或编写定制的代码。
正如文献 [5] 所讲述的一样,映射规则集的另一端通常是终端用户,他们通过挖掘异类数据源、Web大数据、科学数据管理以及某些特定领域中各类型数据之间的关系来构建映射实例。一方面,构建映射实例的关键在于设计查询规范,然而查询规范对于非专业用户来说具有挑战性,并且比执行查询本身 [11] 更耗时。我们认为设计映射规范对这样的用户来说更加困难,这是因为映射包含了许多复杂的查询之间的语义关系。尽管近年来在非专业用户的查询规范方面做了很多努力 [12] [13] [14],但这些文献的研究成果对非专业用户来说并不适用。另一方面,越来越多的普通用户每天都要面对基于用户驱动的数据探索场景,例如文献 [15] 里面提到的几个具有代表性的数据空间项目。因此,针对这类用户相关的映射规则的设计就变得十分有必要了。
最后,为了解决上述已有研究存在的部分问题以及结合实际的地产大数据项目需要。本文在结合原有的文献的研究基础上提出了一种改进的基于数据实例(后文也叫做范例)的用户交互式映射设计方法。该方法使用范例元组做引导,对应于非专家用户提供的数量有限的元组。通过用户与这些元组之间简单的布尔交互来挑战用户,这些布尔查询问题旨在驱动用户所想到且事先未知的映射的推理过程。
2. 例子
结合实际的房地产项目数据,具体考虑如下几个Web源数据和目标数据表格,表1~表3代表由非专家用户提供的源范例元组,同理表4和表5代表目标范例元组。
针对以上范例元组,对于房地产领域的数据分析师用户而言他们很容易会想到的初始映射规则集M如下:
LAT(Idin1, Idin2, Idli) Ù LT(Idli, Name, L)
ÙDT(Idk1, Name', L) Ù BT(Idin1, St1, L, Idk1)
ÙBT(Idin2, St2, L', Idk1)
→ $idS0, idS1, idS3, idS2, idS4 : T3(idS0, Name, L)
ÙT1(St1, Idin1, idS1) Ù T3(idS1, Name', L)
ÙT2(L, Idin1, idS3) Ù T3(idS3, Name', L)
ÙT1(St2, Idin2, idS2) Ù T3(idS2, Name', L)
ÙT2(L', Idin2, idS4) Ù T3(idS4, Name', L)

Table 1. Source instance ES
表1. 源实例ES
Table 2. Source instance ES
表2. 源实例ES
Table 3. Source instance ES
表3. 源实例ES
Table 4. Target instance ET
表4. 目标实例ET
Table 5. Target instance ET
表5. 目标实例ET
首先通过以上的映射场景,我们可以观察到用户提供的范例元组可能没有被很好地选择,甚至与用户所想的映射M不一致。此外,用户提供的范例元组往往也不会是需要推断的映射规则集的解决方案或通用解决方案。在文献 [16] 的开创性工作的基础之上,学者们开始广泛研究关于映射规则集的生成和优化的问题例如文献 [17] [18],但以上文献都假设了非常复杂的输入或更复杂的用户交互,显然这些文献里面的研究成果有待进一步改进。另外虽然本文中的目标元组回忆了数据实例,但它们与以上文献里面的实例相比,根本不同在于本文给出的目标解决方案并不是通用解决方案。
其次以上示例演示了本文部分的运行场景,其中一个非专业用户需要在显示城市房地产信息的两个数据库之间建立映射。源数据库模式由License Association Table、License Table、Developer Table和Building Parcel Association Table (分别缩写为LAT、LT、DT和BT)四个关系表组成,目标数据库模式由State Table、Address Table、Developer License Association Table (分别抽象为T1、T2、T3和T4)三个关系表组成。以上示例中用户为源和目标数据库提供的范例元组又可分别记为ES和ET。
通过以上示例我们还可以观察到每个表所包含的元组数量都非常少,且用户并不打算提供完整的实例,而只是提供一小组具有代表性的元组。我们也可以很容易地观察到以上示例元组中的一些固有的歧义,比如常量沈阳市和平区既代表预售许可表项目地址(在关系LT中),也代表具体的楼栋地址(在相应的关系BT中),此外以上示例中的具体楼栋地址和宗地地址恰好与开发商总部的地址在同一城市的同一个行政区。如果我们将这些示例元组视为基础事实,我们将会把它们翻译为如上所示的映射规则集M。然而,这样的映射并没有很好地解释范例元组,因为首先它假设所有的解决方案都必须包含同一家房地产开发商,且此开发商的总部地址与所开发的楼盘的详细楼栋地址和其所获得的宗地地址恰好与位于同一个城市。其次是预售楼盘的项目地址必须和地产开发公司的总部在同一城市的同一行政区。因此,从逻辑的角度来看,这样的映射方式太过于具体。此外,这种映射在真实的映射场景中可能会非常庞大并且不利于后续映射设计人员理解,因为它完全嵌入了所有的范例元组正如前文所说,我们的映射规范过程是建立在最终用户示例元组之上,这就可能导致我们设计的映射规则集不能够很好的解释原始数据。因此,本文的研究目的旨在构建一个能够为非专家用户提供映射规则集设计服务的通用框架系统,同时将以上由非专家用户提供的初始范例元组抽象为形如(ES, ET)这样的输入对作为系统的输入,则交互式映射规范问题就是通过与用户进行布尔交互来发现映射M',使得(ES, ET)满足M'并且M'逻辑蕴含M,并最终导出更小的或者更加接近用户心目中的可控的映射规则集。本文的主要贡献总结如下:
1) 映射通常在企业IT和其他一些领域例如数据架构师(也称为工程映射的开发人员)中被指定和测试。本文仔细分析了以往用于帮助工程映射人员设计映射规则的一些范例通过大量的文献查阅发现其中的不足之处,在借鉴别人的研究方法的基础上提出了一个更适用于非专家用户的模式映射规范设计框架系统,并适用于一般的GLAV [19] 映射。其中每优化一条映射规则,系统都会就布尔查询问题自动的与用户进行交互。
2) 经过本文方法(即初始规则预处理、原子优化、连接优化)处理后所生成的映射具有不可约的右边。再结合冗余映射消除这就保证了经过优化后的映射是标准形式的映射 [20]。直观地说就是与庞大的初始映射规则集相比,优化后的映射规则对于非专家用户来说更容易理解。
3) 本文提出并实验测量了与可能映射空间相对应的类树形结构的两种映射空间探索策略(即自上而下探索策略和自下而上探索策略),并最终确定了自上而下的探索策略的效率比自下而上的探索策略效率高。
4) 结合具体的项目在实际的地产数据集上进行了实验,验证了本文方法的可行性。
3. 相关概念
本节简单介绍了本文中所使用的各种概念,具体定义如下:
概念1. 数据模型
给定两个可数的不相交的有限的常量集合C和变量集合V,另外假设一个双射函数 ,假如 且 是与变量 相关的常量,那么 。以及一组属性 和一组关系 ,每个关系R都有对应于属性的关系模式 。模式S可以由若干关系构成,即 。关系 的实例表示为一个有限元组 ,其中 可以是常量也可以是不确定值即变量。模式S的实例是该模式包含的所有关系实例的集合。在一个关系R上的元组有如下的形式, ,其中 。同理原子有如下形式, ,其中 。
概念2. 依赖关系(模式映射关系)
一个映射是一个形如 这样的三元组,其中S是源模式,T是和源模式S不相交的目标模式。Σ是一组建立在源模式S和目标模式T上的候选映射规则集tuple-generating dependency (简称tgd)。tgd是形如 这种形式的一阶逻辑公式,其中 代表含有变量的向量, 和 是原子公式的合取式且 只含有 中的变量,此外, 和 还可包含形式为 的等式, 和 都是变量。
若 和 分别为源模式S和目标模式T上的公式,则该依赖关系为源到目标依赖关系(source-to-target tgd)。若 和 均为目标模式T上的公式,则该依赖关系为目标依赖关系(target tgd)。需要说明的是本文只考虑source-to-target tgd (简称s-t tgds),其中φ中的原子来源于关系S,ψ中的原子来源于关系T。另外本文也只研究GLAV [17] 映射,其中的tgd可以包含多个在φ和ψ中的原子。
概念3. 范例元组
通常范例元组是由非专家用户提供的一对输入对其形式如下:(ES, ET),ES代表源实例,ET代表目标实例。并且请注意,用户提供的范例元组可能跟最初的映射规则不是特别匹配,甚至与用户所想的的映射场景M不一致。此外,范例元组不应该是需要推断的映射规则的解决方案或通用解决方案。
概念4. 初始映射规则
本文中需要被优化的初始映射规则是建立在非专家用户提供的初始范例元组的基础上的,假设与(ES, ET)相关的初始映射规则tgd是形如 这样的形式,其中 , 也就是说左侧φ是由ES构成,其方法是通过φ里面的原子配对物取代ES里面的所有元组,并且用变量取代常量。同理右侧ψ也可以通过类似的原理得到。
概念5. 同态和通用解决方案
假设ES和 是同一个模式上的两个实例,实例之间的同态 需要同时满足以下两个条件:
1) 对于每个每一个属于 中的常量c,有 。
2) 对于每一个在实例ES中的 , 在ES中。
对于一个映射M和一个实例ES,如果ET是一个通用解决方案那么其必须满足以下条件:
1) ET首先必须是实例ES的一个解决方案。
2) 对于每个别的方案 ,存在一个同态 ( , )。
概念6. 分裂减少映射(split-reduced)和σ冗余映射(σ-redundant)
将一个tgd拆分为多个逻辑上等价的tgd并且这些tgd的右边不存在相同的存在量词,那么这就满足了分裂减少映射的定义。标准的定义如下:
1) 假设σ是形如 这样的一阶逻辑。
2) 不存在形如 , 这样的tgds使其满足 且
σ冗余映射的主要目的就是排除映射规则集中多余的重复定义的规则,其标准定义如下:
1) 假设 , 。
2) 。
概念7. Chase算法
Chase算法的核心思想可以归纳为以下两个步骤:
首先,依次查看每条映射规则并将约束条件依次应用到初始的源数据实例上。其次,根据相应的映射规则计算出源数据实例的解决方案并使其能够满足规则所有的约束条件。
4. 映射优化
本节将详细描述交互式映射设计方法的关键部分首先是预处理,其目的是将一个看起来非常庞大的tgd划分为一组逻辑上等效的较小的tgd (本文称之为标准映射)。其次是通过原子优化和连接优化对标准映射进行改进从而简化tgds的左侧。后续本文将在一小节详细解释第一步、二小节详细介绍本文所研究系统的两个核心步骤、而映射优化相关的算法将在三、四小节进行详细的描述。
4.1. 规则的预处理
为了便于后续对规则的优化处理,将初始的映射规则分割为较小的规范化的tgd,这对于映射优化是很有必要的。因为它可以让映射设计人员只关注每个简化的tgd左边所隐含的必要原子。同时本小节还结合前面提到的split-reduced mappings和σ-redundant mappings的概念提出了一个评价映射好坏的标准定义,即每一个在Σ中的tgd都应该具有最小的右边并且在Σ中没有冗余的tgd。
然而在对规则进行分解的时候,我们可能会在集合Σ中得到冗余的tgds。这些冗余的tgd是不必要的,需要删除它们以避免后面系统与映射设计人员无用的交互。最后,我们说(S,T,Σ)是规范化的,当且仅当每一个在Σ中的tgd是split-reduced并且在Σ中没有冗余的tgd。结合前面的实例具体的预处理过程如下:
假设φ = LAT(Idin1, Idin2, Idli) Ù LT(Idli, Name, L)
ÙDT(Idk1, Name', L) Ù BT(Idin1, St1, L, Idk1)
ÙBT(Idin2, St2, L', Idk1)
由以上定义可以导出Σnorm = {
φ→$idS0, T3(idS0, Name, L) (1)
φ→$idS1, T1(St1, Idin1, idS1) Ù T3(idS1, Name', L) (2)
φ→$idS3, T2(L, Idin1, idS3) Ù T3(idS3, Name', L) (3)
φ→$idS2, T1(St2, Idin2, idS2) Ù T3(idS2, Name', L) (4)
φ→$idS4, T2(L', Idin2, idS4) Ù T3(idS4, Name', L) (5)
}
4.2. 交互式映射设计执行过程
上一小节定义了生成规范化映射的预处理步骤。本小节将介绍交互式映射框架的两个核心优化步骤。首先,本文方法所基于的假设是非专家用户提供一对具体实例(ES, ET),其中ET不是通用解决方案。其次,对由以上实例导出的初始映射规则进行规范化处理。最后,在映射优化步骤中通过与用户进行简单的布尔交互从而得出最终的映射规则集。但同时我们也注意到对于给定的输入对(ES, ET),满足它的映射的数量可能很庞大。因此,要想提高本文所述框架的效率,最重要的是提供有效的映射空间探索策略,以减少向系统与用户的交互次数。在本节的其余部分中为了便于说明,本文假设用户只提供了一对范例元组(ES, ET))。但是在实际的映射场景中,用户更可能提供的是一组小的实例,例如 。由于系统每次向用户提出的问题都集中在一个tgd上,并且由于我们不假定每个( , )中的ET都是通用解决方案,因此本文的方法完全适用于实例对的集合。结合上面的阐述这里正式的定义交互式映射设计的具体过程:
a. 首先计算和每对( , )相关的初始映射规则σi;
b. 将上一步的每个σi分解为 ;
c. 删除上述结果中冗余的tgds;
d. 对上一步的结果集中的每个 执行原子优化和连接优化。
4.3. 原子优化
正如4.1节中所讨论的,规则预处理就是将初始映射规则集转换为符合split-reduced定义的映射规则集,其中每个tgd的左边都包含多个原子,如φ。然而就实际的映射场景而言,φ中的一些原子可能是多余的并且还可能进一步导致歧义。为了缓和以上歧义和简化规则,本文以前人的研究结果为基础提出如下算法:
这里首先对上述算法1进行简单介绍,更详细的讲解将在下面小节通过具体的例子来说明。首先上述算法第4行根据每个待优化的tgd的左边原子构造候选映射空间,其次算法1第6到15行递归地遍历候选映射空间直到该空间不存在任何原子,最后再将每个优化后的tgd存储到Σ' (16~17行)。
4.3.1. 原子优化中树的应用
算法1采用类树的数据结构来处理数据主要是基于树是一种非线性的数据结构其叶子节点可以存储各种类型的数据元素,并且算法1需要处理的数据类型也并非常规的数据类型。
例1. 考虑4.1节中Σnorm中的规则集,可以看出它们都具有同一个特征那就是具有相同的左边即集合{LAT(Idin1, Idin2, Idli);LT(Idli, Name, L);DT(Idk1, Name', L);BT(Idin1, St1, L, Idk1);BT(Idin2, St2, L', Idk1)},对于Σnorm中的每条规则来说以上原子的集合的子集,即为需要探索的全部映射空间同时也代表了树的叶子节点。
接下来将以树为数据载体结合4.1节中的规则3来解释算法1中的第4行代码是如何构造出一棵完整的候选映射空间树的,当然对于4.1节Σnorm中的其它规则来说也有类似处理过程。首先,通过观察我们可以注意到Σnorm中的规则3的右边的是形如∃idS3,T2(L, Idin1, idS3) Ù T3(idS3, Name', L)这样的逻辑表达式,并且其中的原子T2和T3所包含的全部普通变量的集合为{L, Idin1, Name'}。
其次,一个优化后的tgd必须满足一个基本条件,即其左边应该至少包含以上普通变量,就例1中给出的原子的集合来说,假设满足以上条件的最小的子集为如下两个集合:
{BT(Idin1, St1, L, Idk1),DT(Idk1, Name', L)}和{LAT(Idin1, Idin2, Idli),DT(Idk1, Name', L)}并且所有不是以上任意一个集合的超集的集合都将被剪枝。
最后综合上述原理构造出的候选映射空间树图1所示:
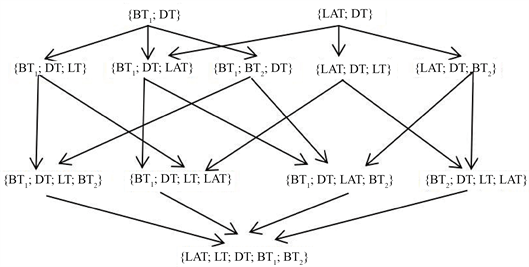
Figure 1. Candidate mapping space tree for examples 1 and 2
图1. 例1和例2的候选映射空间树
以上空间树中的原子集:LAT = LAT(Idin1, Idin2, Idli), LT= LT(Idli, Name, L), DT = DT(Idk1, Name', L), BT1 = BT(Idin1, St1, L, Idk1),BT2 = BT(Idin2, St2, L', Idk1)
4.3.2. 候选映射空间树的遍历
在探索可能的映射空间(也就是对映射空间树进行遍历)的过程中,每经过一个叶子结点系统都会和非专家用户进行一次交互(算法1第8行),同时选择叶子结点的方式将由算法1的第7行给出的探索策略决定。
例2. 假设这里采用自顶向下宽度优先的探索策略对图1的映射空间树进行遍历。显然依据上一节的描述对图1的遍历就是对4.1节中的规则3进行优化,具体的优化过程如下:
首先当遍历节点{BT1; DT}的时候,系统对用户提出如下问题:
“通过BT(1Z#,已发证,沈阳市和平区,K1)和DT(k1,沈阳万科中山置业有限公司,沈阳市和平区)能否导出T2(沈阳市和平区,1Z#,a3)和T3(a3,沈阳万科中山置业有限公司,沈阳市和平区)?”假如用户对这个问题回答为能,那么{BT1; DT}的所有超集都将会被剪枝(也就是图1中的蓝色节点)。系统随后将输出如下规则:
BT(Idin1, St1, L, Idk1) Ù DT(Idk1, Name', L) → $idS3, T2(L, Idin1, idS3) Ù T3(idS3, Name', L) (6)
接下来就是遍历节点{LAT; DT},此时系统对用户提出如下问题:
“通过LAT(1Z#,2016-001,16357)和DT(k1,沈阳万科中山置业有限公司,沈阳市和平区)能否导出T2(沈阳市和平区,1Z#,a3)和T3(a3,沈阳万科中山置业有限公司,沈阳市和平区)?”用户很可能对这个问题回答不能,因为这里存在一定的歧义,即开发商的总部地址必须和其负责开发的楼盘里面的具体住宅楼栋地址相同,显然这样的约束与现实的情况并不相同。
再接下来系统会继续遍历其下层的叶子节点,也就是集合{LAT; DT; LT}和{LAT; DT; BT2}。针对这两个集合系统与用户最终的交互结果都是不能,最后对于集合{LAT; DT; LT; BT2}采用同样的交互流程所得到的结果显然还是不能。最后算法1将输出最终的结果(6)。
4.4. 连接优化
在关系数据库中,相同值的多次出现并不一定意味着包含该值的属性之间存在相关的语义关系。本文的运行场景中的一个例子是常量“沈阳市和平区”的出现。它既是楼盘项目所在地也是开发商总部所在地,同时还是具体的住宅楼栋所在地。然而,初始映射规则强化了这种可能由于虚假使用同一变量而导致的以上共存现象。因此,初始映射规则可能会在tgds的左侧引入不相关的连接。要想最终生成既满足用户心中所想又没有歧义的相对完美的映射,我们首先需要从这些不相关的连接中区分相关的连接。在正式介绍连接优化之前不得不先引用两个数学概念:
集合的覆盖:若把一个集合A划分成若干叫做块的非空子集使得A中的每个元素至少属于一个分块,则这些分块的全体叫做A的一个覆盖。
集合的划分:给定一个集合A的一个覆盖S,若A中的每个元素属于且仅属于S的一个分块。则将这样的S称作A的一个划分。
在以上概念的基础之上本文又给出了如下两个简单的定义:
定义1:假设集合A的一个划分被表示为P,那么表达式: 指示集合A中的任意两个不同的元素在一个划分P的同一个块中。
定义2:在定义1的基础上定义偏序 。
在数据库的连接查询中,连接通常由变量的多次出现来编码,我们将这些多次重复出现的变量称为连接变量。连接优化的主要原理就是用新的变量取代那些旧的被误用的变量以此来排除不相关的连接。综合以上背景和实际的房地产项目需要本文提出如下算法:
上述算法2的简要执行步骤如下:
1) 对将要进行连接优化的规则初始化为标准的一阶逻辑表达式: (算法第3行)。
2) 对每一个属于 的普通变量,只要其满足在φ中的出现次数大于2就对包含该变量的连接进行优化,直到遍历完所有在 的普通变量(5~11行)。
3) 最后就是将结果赋值给Σ'并进行返回(12~15行)。
接下来本文将结合具体的例子进一步解释以上算法的详细执行过程考虑如下例子:
例3. 回顾例2的tgd(6)如下:
BT(Idin1, St1, L, Idk1) Ù DT(Idk1, Name', L) → ∃idS3, T2(L, Idin1, idS3) Ù T3(idS3, Name', L)
通过观察以上tgd可以很容易注意到它存在歧义,那就是在变量L的使用上即它既代表楼盘项目所在地也代表开发商总部所在地,同时还代表具体的住宅楼栋所在地。之所以出现这样的歧义是因为变量L的多次重复使用而造成的。算法2中第9行所包含的子程序VarJoinsRefinemen就完美的解决了这样的歧义。具体的伪代码如下所示:
在介绍算法3的执行原理之前,需要先介绍与之相关的两个定义具体如下:
定义1:合格的划分P
考虑前文例2中的tgd(6):BT(Idin1, St1, L, Idk1) Ù DT(Idk1, Name', L) → $idS3, T2(L, Idin1, idS3) Ù T3(idS3, Name', L),将其中的变量L根据其在规则中多次出现的位置分别用新的变量取代(即L1,L2,L3,L4)得到如下规则:
BT(Idin1, St1, L1, Idk1) Ù DT(Idk1, Name', L2)
→∃idS3, T2(L3, Idin1, idS3) Ù T3(idS3, Name', L4)
由于本文不考虑在tgd中引入新的存在量词,因此每个出现在ψ中的变量都必须满足至少与一个出现在φ中的变量相绑定。如划分{{L1; L2}; {L3; L4}}为变量L的一个合格的划分,划分{{L3}; {L1; L2; L4}}为不合格的划分。综上更正式的定义如下:
考虑一个形如 的tgd,存在一个变量 且在该tgd中多次出现。我们将变量x的所有划分集合里面,那些满足其所有块里面都至少包含一个在φ中的变量的划分称为一个合格的划分。
定义2:数据的存储结构
算法3和算法1一样同样采用类树的结构来存储数据,唯一不同的就是剪枝叶子节点的理论标准不一样。算法3的主要灵感来自于集合的划分,即给出任意两个不同的划分P和P',如果P ≤ P'且P是一个合格的划分,那么P'也是一个合格的划分。这些合格的划分的不同的集合构成了树的不同节点最终构成了算法3的探索空间。
接下来本文正式开始讲解算法3:
1) 对每个出现在s中的x都使用一个新的变量去取代它,从而产生σ' (算法第1行)。
2) 参照上面的定义1和定义2初始化树的叶子节点,保留合格划分的节点排除不合格划分的节点。(算法第3行)
3) 算法第6行主要是探索合适的遍历方式,任何有助于提高搜索效率的策略都可以运用在这里。
4) 算法的第7行和17行主要是统一变量,即存在于一个划分的同一个块里的不同名字的变量将被统一为相同名字的变量。
5) 算法第8到13行主要实现系统与用户之间的交互,通过交互的结果来决定后续系统的输出。
下面本文将通过一个具体例子来模拟以其执行过程:
例3. 再次回顾例2中的tgd(6):
BT(Idin1, St1, L, Idk1) Ù DT(Idk1, Name', L)
→$idS3, T2(L, Idin1, idS3) Ù T3(idS3, Name', L)
以上tgd所含的普通变量为 = {Idin1, St1, L, Idk1, Name'}根据算法2这里只考虑在φ中出现次数大于2的变量即L和Idk1。首先考虑Idk1依据算法3将其分别重命名为t1和t2,则可推导出如下的tgd:
BT(Idin1, St1, L,t1) Ù DT(t2, Name', L)
→$idS3, T2(L, Idin1, idS3) Ù T3(idS3, Name', L)
正如前文所讲此时树中存在两个节点,一个是{{t1}; {t2}}另外一个是{{t1; t2}}。接下来就是遍历这两个节点并且与用户进行交互,判断新引进的变量是否存在相关性。对于节点{{t1}; {t2}}用户可能会回答不相关此节点将被剪枝,因为此时开发商拥有与其所开发楼盘不相关的标识符。最后显然只剩下节点{{t1; t2}},此tgd不做任何的改变。
然后考虑变量L,经过重命名后导出如下tgd:
BT(Idin1, St1, L1, Idk1) Ù DT(Idk1, Name', L2)
→$idS3, T2(L3, Idin1, idS3) Ù T3(idS3, Name', L4)
可以观察到这里存在如下5个合格的划分:
{{L1; L3}; {L2; L4}}, {{L1; L4}; {L2; L3}}, {{L1; L3; L4}; {L2}}, {{L1}; {L2; L3; L4}}, {{L1; L2; L3; L4}}同时以上划分组成了四颗不同的树具体如下图2所示:
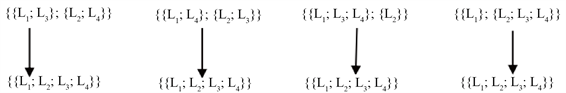
Figure 2. Diagram of example 3
图2. 例3的划分图
首先遍历第一颗树,对于节点{{L1; L3}; {L2; L4}}来讲系统将对用户提出如下问题:
“通过BT(1Z#,已发证,沈阳市和平区1,K1)和DT(k1,沈阳万科中山置业有限公司,沈阳市和平区2)是否足够导出T2(沈阳市和平区1,1Z#,a3)和T3(a3,沈阳万科中山置业有限公司,沈阳市和平区2)?”显然以上划分对用户来说是可以接受的,即这些新引进的变量之间存在相关性。此时节点{{L1; L3}; {L2; L4}}的叶子节点将被剪枝,最后经过变量的统一得出如下tgd:
BT(Idin1, St1, L1, Idk1) Ù DT(Idk1, Name', L2) → $idS3, T2(L1, Idin1, idS3) Ù T3(idS3, Name', L2) (7)
接下来同理遍历后面的树,然而剩下的划分无一例外全都将楼栋的具体地址与开发商的总部地址关联起来,这在现实环境中太过于具体了。因此用户将持续回答不相关最后系统输出最终结果tgd(7)。
4.5. 最终的映射
最后对于本文所给定的一对范例元组来说,经过初始规则的生成、规则的预处理、原子优化、连接优化后得出的最终映射规则如下:
LT(Idli, Name, L) →$idS0, T3(idS0, Name, L)
BT(Idin1, St1, L1, Idk1) Ù DT(Idk1, Name', L2) → $idS1, T1(St2, Idin2, idS1) Ù T3(idS1, Name', L2)
BT(Idin1, St1, L1, Idk1) Ù DT(Idk1, Name', L2) → $idS3, T2(L1, Idin1, idS3) Ù T3(idS3, Name', L2)
BT(Idin2, St2, L', Idk1) Ù DT(Idk1, Name', L) → $idS2, T1(St2, Idin2, idS2) Ù T3(idS2, Name', L)
BT(Idin2, St2, L', Idk1) Ù DT(Idk1, Name', L) → $idS4, T2(L', Idin2, idS4) Ù T3(idS4, Name', L)
5. 实验验证
5.1. 数据集
本文首先,将从中国土地网、安居客、房天下等房产信息网站爬取的300多万条数据,经过垃圾清理、冗余信息删除两个预处理过程后得到的数据集作为本文实验的基本数据集。其次,为了更好的验证本文所提出的映射系统的有效性和可行性,我们又从以上数据集中筛选出部分典型的房产信息数据构建实验数据集。最后,借助映射设计工具iBench [21] 人工模拟了几个映射场景,这些映射场景能够基本满足本文对范例元组的要求。
5.2. 实验设置
本文的实验目标主要有两个:第一实验评估出与最终用户交互较少的映射空间探索策略。第二实验评估出本文方法的可行性。
为了实现以上实验目的本文首先人为模拟了5个映射场景,并且以这5个场景为基础来构建范例元组。此时的范例元组可以看成是由一个完美的用户所提供即这些范例元组所包含的映射规则就是用户心中所想的完美映射规则。
其次,针对以上范例元组人为引入歧义或者错误,以此来模拟非专家用户所提供的范例元组的情况。本文将此操作定义为两次退化具体方法可以通过如下例子来说明:
例4. 假设任意一条规则s所产生的实例如下:
= {J(f1, f2, f3, a1); K(a1, f4, f5)}和 = {J1(A6, f3, f1, a2); K1(a2, f4, f5)}
第一次退化首先在 中随机选择一个元组进行复制,然后在该元组内随机选择一个常量并且用一个新的常量代替它,最后将这个新的元组加入到 中。第二次退化主要是针对连接的即首先随机选择两个出现在 中的常量,然后在 和 的范围内找到其中一个常量出现的所有位置并且用另一个常量代替这些位置上的常量值。综上最后得到退化后的实例如下:
= {J(f1, f3, f3, a1); K(a1, f4, f5); J(f1, f3, f3, a1)}; = {J1(A6, f3, f1, a2); K1(a2, f4, f5)}
其中黑色下划线表示退化的地方。
最后以上面的阐述为基础给出如下表6。
Table 6. Experimental mapping scenario
表6. 实验映射场景
其中|Σ|代表每个映射场景所包含的tgds的总的数量。 ,其中Nv是tgds中每个不同变量v出现的次数总和且 ,V是tgds中不同的变量的集合。同时随着退化的持续进行 会发生改变。 ,其中P代表系统处理一个映射场景时与用户交互的总次数,S代表该映射场景所包含的全部tgd的数量。
5.3. 实验结果
图3中横轴表示 ,纵轴表示 。从实验结果图3我们可以观察到除了场景A3以外,在其它的场景中都能观察到系统与用户之间的交互次数与 存在很强的线性相关性,换句话说就是本文提出的方法在实际的映射场景中具有可行性,因为系统与用户的问题交互次数并不会因为范例元组的增加而剧烈增长,而这也保证了本文方法的高效性。
其次还可以观察到在每个场景中,自上而下广度优先的映射空间探索策略所表现出的线性相关性要强于自下而上广度优先的映射空间探索策略。也就是说在实际的运用中我们应当采用自上而下广度优先的映射空间探索策略,因为此时算法的效率最高。

Figure 3. Diagram of experimental results
图3. 实验结果图
6. 结论
首先,本文分析了目前存在的一些适用于普通用户的映射设计工具,从中发现其不足并在已有研究的基础之上设计了一个适用于非专家用户使用的映射设计系统。同时本文所设计的系统的主要工作原理就是,对由非专家用户提供的范例元组先进行规则的预处理,然后再将预处理后的规则输入到本文所设计的系统里面,经过原子优化(即原子的分解与选择)和连接优化(排除tgd中变量之间不相关的连接)两个步骤后最终输出更符合用户心中所想的映射规则。
其次,本文以Web地产数据集为实验数据,通过对数据的简单预处理和集成后人为的模拟了5个映射场景对本文提出的方法进行了实验,验证了本文方法的可行性。当然本文也存在不足的地方,比如在设计探索空间策略的时候可以考虑使用机器学习的方法,或者在用户交互阶段可以设计出相关的错误接受机制而不是简单的回答不能。
文章引用
李 静,李 贵,李征宇,韩子扬,曹科研. 带有范例元组的交互式数据转换映射方法研究
Research on Interactive Data Conversion Mapping Method with Example Tuples[J]. 数据挖掘, 2021, 11(02): 84-99. https://doi.org/10.12677/HJDM.2021.112009
参考文献
- 1. 纪宇航, 李贵, 李征宇, 韩子扬, 曹科研. Web数据转换模式映射优化方法[J]. 数据挖掘, 2020, 10(1): 76-89. https://doi.org/10.12677/HJDM.2020.101008
- 2. Fagin, R., Kolaitis, P.G., Miller, R.J. and Popa, L. (2005) Data Exchange: Semantics and Query Answering. Theoretical Computer Science, 336, 89-124. https://doi.org/10.1016/j.tcs.2004.10.033
- 3. 杨雪梅, 董逸生, 王永利, 钱江波, 钱刚. 异构数据源集成中的模式映射技术[J]. 计算机科学, 2006, 11(7): 1-5.
- 4. Kimmig, A., Memory, A., Miller, R.J. and Getoor, L. (2017) A Collective, Probabilistic Approach to Schema Mapping. 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, 19-22 April 2017, 915-932. https://doi.org/10.1109/ICDE.2017.140
- 5. Bernstein, P.A. and Melnik, S. (2007) Model Management 2.0: Ma-nipulating Richer Mappings. SIGMOD’07: Proceedings of the 2007 ACM SIGMOD International Conference on Man-agement of Data, June 2007, 1-12. https://doi.org/10.1145/1247480.1247482
- 6. Shvaiko, P. and Euzenat, J. (2005) A Survey of Schema-Based Matching Approaches. In: Spaccapietra, S., Ed., Journal on Data Semantics IV. Lecture Notes in Computer Science, Vol. 3730, Springer, Berlin, Heidelberg, 140-171. https://doi.org/10.1007/11603412_5
- 7. Bonifati, A., Bellahsene, Z. and Rahm, E., Eds. (2011) Schema Matching and Mapping. Data-Centric Systems and Applications. Springer, Berlin. https://doi.org/10.1007/978-3-642-16518-4
- 8. Alexe, B., Chiticariu, L., Miller, R.J. and Tan, W.C. (2008) Muse: Mapping Understanding and Design by Example. In 2008 IEEE 24th International Conference on Data Engineering, Cancun, 7-12 April 2008, 10-19. https://doi.org/10.1109/ICDE.2008.4497409
- 9. Alexe, B., ten Cate, B., Kolaitis, P.G. and Tan, W.C. (2011) De-signing and Refifining Schema Mappings via Data Examples. SIGMOD’11: Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, June 2011, 130-135. https://doi.org/10.1145/1989323.1989338
- 10. Gottlob, G. and Senellart, P. (2010) Schema Mapping Discovery from Data Instances. Journal of the ACM, 57, 6. https://doi.org/10.1145/1667053.1667055
- 11. Jagadish, H.V., Chapman, A., Elkiss, A., Jayapandian, M., Li, Y., Nandi, A. and Yu, C. (2007) Making Database Systems Usable. SIGMOD’07: Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, June 2007, 13-24. https://doi.org/10.1145/1247480.1247483
- 12. Abouzied, A., Hellerstein, J.M. and Silberschatz, A. (2012) Playful Query Specification with Dataplay. Proceedings of the VLDB Endowment, 5, 1938-1941. https://doi.org/10.14778/2367502.2367542
- 13. Papadimitriou, C.H., Abouzied, A., Angluin, D., Hellerstein, J.M. and Silberschatz, A. (2013) Learning and Verifying Quantified Boolean Queries by Example. PODS’13: Proceedings of the 32nd ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, June 2013, 49-60.
- 14. Diaz, G.I., Arenas, M. and Benedikt, M. (2016) Sparqlbye: Querying RDF Data by Example. Proceedings of the VLDB En-dowment, 9, 1530-1535. https://doi.org/10.14778/3007263.3007302
- 15. Franklin, M.J., Halevy, A.Y. and Maier, D. (2008) A First Tutorial on Dataspaces. Proceedings of the VLDB Endowment, 1, 1516-1519. https://doi.org/10.14778/1454159.1454217
- 16. Popa, L., Velegrakis, Y., Miller, R.J., Hernández, M.A. and Fagin, R. (2002) Translating Web Data. VLDB’02: Proceedings of the 28th International Conference on Very Large Databases, Hong Kong, 20-23 August 2002, 598-609. https://doi.org/10.1016/B978-155860869-6/50059-7
- 17. Francis, N. and Libkin, L. (2017) Schema Mappings for Data Graphs. Proceedings of the 36th ACM SIGMOD- SIGACT-SIGAI Symposium on Principles of Database Systems, May 2017, 389-401. https://doi.org/10.1145/3034786.3056113
- 18. Deutch, D., Gilad, A. and Moskovitch, Y. (2018) Efficient Prove-nance Tracking for Datalog Using Top-K Queries. The VLDB Journal, 27, 245-269. https://doi.org/10.1007/s00778-018-0496-7
- 19. 赵雨蒙. 基于模式映射的异构数据集成模型研究[D]: [硕士学位论文]. 济南: 山东大学, 2010.
- 20. Gottlob, G., Pichler, R. and Savenkov, V. (2011) Normalization and Optimiza-tion of Schema Mappings. The VLDB Journal, 20, 277-302. https://doi.org/10.1007/s00778-011-0226-x
- 21. Glavic, B., Arocena, P.C., Ciucanu, R. and Miller, R.J. (2015) The iBench Integration Metadata Generator. Proceedings of VLDB, 9, 108-120. https://doi.org/10.14778/2850583.2850586