Service Science and Management
Vol.
09
No.
01
(
2020
), Article ID:
33918
,
11
pages
10.12677/SSEM.2020.91008
Mining Method of Text Emotion Intensity Distribution for KANO Model
Biao Ma, Xiang Li
Donghua University, Shanghai

Received: Dec. 22nd, 2019; accepted: Jan. 6th, 2020; published: Jan. 13th, 2020

ABSTRACT
In the Web2.0 era, users are accustomed to freely sharing the feelings and evaluations during the experience process, which provides a more convenient and authentic data source for the KANO model than the classic method of questionnaire. However, mining the user’s emotional experience is a key prerequisite for building a KANO model using user-generated content. Based on the theory of emotion wheel, this paper proposes a text emotion intensity distribution prediction model by combining word vectors and long-term and short-term memory neural networks, and explores the model’s cross-domain capabilities through a universal text representation method, and finally provide a satisfactory mining method to predict the users’ emotion intensity distribution. This study provides a new emotion-based perspective for measuring the quality of user experience in the KANO model, and lays the foundation for constructing the KANO model from user-generated text content.
Keywords:Emotion Intensity Prediction, KANO Model, Emotion Wheel, Long and Short-Term Memory Neural Network

面向KANO模型的文本情绪强度分布 挖掘方法
马彪,李想
东华大学,上海
收稿日期:2019年12月22日;录用日期:2020年1月6日;发布日期:2020年1月13日

摘 要
Web2.0时代,用户习惯于在线上自由地分享体验过程中的感受和评价,这为KANO模型提供了比调查问卷更加便捷和真实的数据来源。然而挖掘用户的情绪体验是运用用户生成内容构建KANO模型的关键前提。本文以情绪轮理论为基础,结合了词向量和长短时记忆神经网络,提出了文本情绪强度分布预测模型,并且通过通用的文本表示方法,探索模型的跨领域能力,最终为预测用户的情绪强度分布提供一种满意的挖掘方法。本文研究为KANO模型中衡量用户体验质量提供了新的基于情绪的视角,并且为从用户生成文本内容中构建KANO模型奠定了基础。
关键词 :情绪强度预测,KANO模型,情绪轮,长短时记忆神经网络

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
体验经济时代已经来临,产品和服务都是围绕为顾客创造难以忘怀的体验而存在。在激烈的竞争环境下,企业需要全方位地持续提高顾客的体验质量来保持核心竞争力。KANO模型是用于产品改进、新产品设计过程中提高顾客满意度的经典方法。传统的KANO模型通过调查问卷收集数据建模,一方面问卷调查耗时费力,成本较高,另一方面受调查者通过回忆或根据假设情形想象被动地填写问卷,问卷调查结果不一定可以有效反应顾客真实的体验。
随着Web2.0的发展,用户越来越习惯通过线上的评论表达并分享其独特的消费体验。用户评论中的情绪内容可以客观地反应用户的真实感受及体验质量 [1] [2] [3]。如在对上海迪士尼的评论“检票耗时,把客人都当贼,进场/玩设施多次验票对照片让人很烦”中,顾客用“很烦”表达了检票环节给他带来的体验——烦躁的情绪。海量开放的评论内容为KANO模型提供了相比调查问卷更加直接、便捷且真实的数据来源方案,但如何从非结构化的自由文本内容中挖掘顾客的情绪体验,是利用评论构建KANO模型的障碍,解决这一问题是后续基于文本内容的KANO模型构建的基础。
用于KANO模型的情绪体验挖掘问题如果仅考虑情绪类别,忽略情绪之间的强度差异,后续KNAO模型将难以捕捉到不同产品特征/属性对用户体验影响的区别。比如,用户在使用产品时对特征A感受到有些愤怒,对特征B感受到非常愤怒,愤怒的强弱反映了不同水平的体验质量,仅做情绪分类就忽略了特征A和B的差异,对KANO模型而言,可能导致对特征分类错误。因此更具体来说,上述提取文本情绪的问题需要挖掘的是评论中的情绪强度预测,进而刻画不同用户体验间微妙的差别,为改进KANO模型做准备。
2. 文本情绪相关研究
围绕着文本情绪强度预测研究,首先需要了解成熟的情绪理论里,情绪有哪些种类,情绪之间的关系,接着是情绪强度的预测方法。
2.1. 情绪轮理论
情绪研究起源于心理学,心理学中存在诸多情绪分类方法,情绪轮理论自提出以后被广泛应用,本文依据的情绪理论是情绪轮理论。Plutchik基于情绪进化理论提出的情绪轮理论 [4],有效地刻画了情绪之间的微妙关系,不仅捕捉了情绪的强弱关系,而且蕴含了相邻情绪之间交互可以产生新情绪的理念。在Plutchik情绪轮(见图1)中,同类情绪有强度上的区别,比如生气、愤怒和暴怒;同时,8种基本情绪之间有相近和相反的关系,相邻位置的情绪相近可以产生新的情绪,相对位置的情绪则相反。
情绪轮理论作为一种经典的情绪分类理论被广泛应用于情感及情绪分析过程 [5] [6] [7] [8] 中,具体应用在在线评论、社交媒体、面部表情等研究领域。在在线评论的研究中,情绪轮理论可以作为评论有用性研究中情感内容的分类依据 [9] 、顾客评价可视化分析研究中情绪可视化 [10] [11] 的依据;在面向社交媒体的研究中,情绪轮理论支撑情绪词语生成 [12] 、文本分类 [13] 、情感及情绪分析 [5] [6] [8] [14] 、热点事件识别 [15] 和公司信用评级预测 [16] 等研究;在图像分类及3D建模领域,情绪轮理论用于面部表情识别和人脸3D建模过程 [17] [18] [19]。

Figure 1. Plutchik emotion wheel
图1. Plutchik情绪轮
2.2. 情绪分布相关研究
回顾现有对情绪强度的研究,存在着以人工标注为主的现状。中文领域,Quan等学者人工对1300多篇中文博客进行了文章、段落、句子级别的情绪强度标注 [20],这是作者所知范围内唯一标注了情绪强度的中文文本数据集。在英文领域,Saif等利用众包和BWS (best-worst scaling, BWS)方法对tweets进行了情绪的强度标注 [21],被称为EmoInt-2017,用做WASSA-2017情绪强度任务的官方数据集。人工标注的方法需要多个具备相关领域知识的标注者共同完成,标注质量受制于标注者的经验判断,而且面临着标注者意见不一致时需要解决整合的问题。因此,有学者提出了自动化的方法进行文本情绪强度的研究。
自动化提取情绪强度的方法一般是应用机器学习的方法,将问题视为为已知文本的情绪类别,预测其情绪强度的回归问题。基于Saif等人构建的EmoInt-2017数据集,除了基于人工特征的传统机器学习方法 [21],有一些学者将深度学习方法用于情绪强度的识别,如卷积神经网络 [22] 、循环神经网络 [23] [24] 、卷积神经网络拼接循环神经网络 [25] 以及集成学习方法 [26]。不过,广范应用的情绪分类理论 [4] [27] [28] 对情绪的分类都为6~8不等,而基于EmoInt-2017数据集的研究只考虑了4种情绪(愤怒、恐惧、高兴和悲伤),这4种情绪仅仅是经典情绪分类中的部分情绪。
综上所述,当前对情绪分类的研究还存在一些问题:一方面,现有情绪强度研究受限于人工标注的数据集,人工标注过程耗时长成本高,而且基于领域的数据集迁移性较差;另一方面,考虑到顾客在体验过程中情绪的丰富多样,比如期待、惊喜等情绪的存在,现有对部分情绪类别强度的研究还不足以完成对顾客体验情绪的完整刻画。因此,本文采用长短时记忆网络依据情绪轮理论对文本中的情绪强度分布进行挖掘。
3. 情绪强度分布模型
3.1. 问题描述
为了挖掘顾客在产品特征级别上的情绪体验,本文以句子级别的情绪为研究对象。一句话可能包含多种不同强度的情绪,比如一句对安徽屯溪老街的评价:“逛了中国很多老街,这个屯溪老街跟很多老街一样,很商业化,从头到尾走十几分钟,只有明信片店吸引到我,有消费”,句子中包含的情绪有惊喜和讨厌,讨厌强度相对惊喜更高。因此本文要预测句子级别的情绪强度分布,情绪强度分布不仅包含了有无情绪的信息,而且包含了情绪的强度大小。
文本句子的情绪强度分布可以视为一组回归预测问题。首先,根据情绪轮理论情绪的基本类别可以分为8种,分别是生气(anger)、紧张(anxiety)、期待(expect)、讨厌(hate)、喜欢(love)、开心(joy)、悲伤(sorrow)和惊讶(surprise)。文本的情绪强度分布可以表示为 ,其中, , 表示第i种情绪,它的取值表示第i种情绪的强度。模型的输入是文本的表示,输出即为情绪的强度分布。
3.2. 模型构建
考虑到文本情绪分布的不平衡,不同类别的情绪其分布的表达的习惯和方式有所不同,本文针对不同类别的情绪分别设计了模型用于预测情绪强度,最终将所有模型的结果整合在一起,即得到文本的情绪强度分布。
在解决情绪强度预测问题时,首先要解决的问题是文本的表示。传统的文本表示模型,如TF-IDF向量空间模型和词袋模型将文本表示为与文本集词典等长的稀疏向量,每一个维度对应一个独特的词语。这类方法忽视了词语上下文的关系,难以有效表示文本的语义。Google开源的词向量模型有效解决了上述问题,自然语言处理研究中越来越普遍地使用词向量作为文本的表示 [29] [30] [31]。在词向量模型中,相似的词语用相近的多维稠密向量表示,且词向量维度固定可以设置,因此本文采用Word2vec模型得到词语的向量表示,然后将文本表示为词语的向量序列,作为情绪强度预测模型的输入。
其次,根据问题的特点选择模型从文本中挖掘情绪的强度。循环神经网络的结构使其擅长捕捉序列信息,经常被用于文本等具有序列关系的问题建模中 [30] [32] [33] [34] [35]。循环神经网络相比一般的神经网络结构可以捕捉文本的上下文信息。传统的循环神经网络(RNN)在捕捉序列关系时由于梯度爆炸或梯度消失问题难以有效进行长时间的记忆,在处理远距离上下文关系时具有很大局限性。长短时记忆网络(LSTM)是循环神经网络的变体,有效解决了循环神经网络的长距离依赖问题。LSTM通过输入门、遗忘门和输出门结构来降低梯度爆炸或消失的风险。综上,采用LSTM来预测文本的情绪强度分布是非常适合的方法。
从整体上看,本文通过LSTM模型分别预测文本的各类情绪强度,进而得到句子级别文本的情绪强度分布,模型的流程见图2:

Figure 2. Text emotion intensity distribution prediction model
图2. 文本情绪强度分布预测模型
具体来看,每个LSTM预测器的网络结构如图3所示。在每一个LSTM预测器中,句子的输入形式如下:如果句子长度为N,句子中的第n个词用 表示, ,d为词向量的维度,句子S可以表示为:
(1)
对于第i个LSTM预测器,其中 ,如果最后一个LSTM层学习得到的句子向量表示为Xt,则输入句子的第i种情绪的强度值 应表示为:
(2)
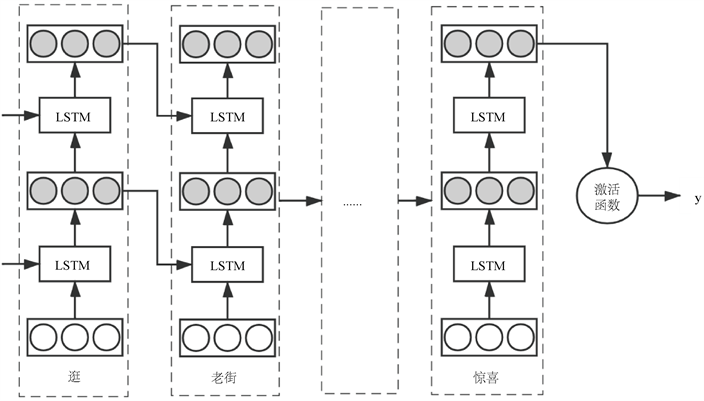
Figure 3. LSTM predictor network architecture diagram
图3. LSTM预测器网络架构图
4. 实验过程及结果
本实验在windows10操作系统下进行,CPU参数:Intel(R)Core(TM)i5-7200U CPU@2.50 GHz 2.71 GHz;内存为8.00 GB,采用python3.6编程。在搭建神经网络结构时使用了配置tensorflow后端的keras库。
4.1. 数据集介绍
本文采用的数据集为Ren_CECps 1.0 [20]。Ren_CECps 1.0共包含了1487篇中文博客文章,共计11255个段落,35786个句子,878164个词语。本文以句子作为粒度,分析文本的情绪强度分布。原始数据集Ren_CECps 1.0中存在着情绪分布不平衡的问题,Surprise和Anger强度为0的样本占据总体90%以上,Expect、Hate以及Joy强度为0的样本占比达到了80%以上,表1列出了Ren_CECps 1.0的文本情绪强度分布。
Ren_CECps 1.0中情绪分布不平衡,为了提高模型的学习效率,采用每个类别分开训练的方法。每个情绪类别的数据集构造时,排除了强度为0的句子,接下来按照20%的比例从数据集中随机抽取样本作为测试集,剩余80%作为训练集。从训练集的大小来看,Surprise、Anger和Hate这3类情绪训练集的样本数均不足3000条,是相对较少的情绪类别,其中Surprise类的情绪数目最少,仅有916条;Love、Anxiety和Sorrow这3类情绪数目超过6000条,相对较多,其中Love有9826条,是数据集中分布最广泛的情绪。各个情绪类别的训练集及测试集样本具体数量见表2。

Table 1. Ren_CECps 1.0 emotional intensity distribution of text
表1. Ren_CECps 1.0文本情绪强度分布
Table 2. Emotional intensity distribution of training set
表2. 训练集文本情绪强度分布
4.2. 评价标准
情绪强度预测模型本质上是一个回归问题,因此采用距离类指标平均绝对误差(mean absolute error, mae),通过计算预测值和人工标注值之间的距离绝对值来评估模型的预测效果。
距离类指标在反映模型效果上并没有一个绝对的标准,为了更加直观描述模型效果,本文构建了准确率指标。考虑到在后续应用于KANO模型时并不需要非常精确的情绪强度值,本文的计算准确率时将为百分比误差在0.3以内的样本视为预测准确,否则视为预测错误。将准确预测的样本数记为A,错误预测的样本数记为B,准确率的计算公式如下。
4.3. 实验流程及模型参数
本文采用的基本模型为LSTM模型。基本流程为,数据预处理、模型搭建和模型效果评估。在数据预处理环节,采用了分词和去停用词处理。分词采用了python流行的分词工具结巴分词。去停用词主要将英文字符、数字等去除。
本文首先采用了实验数据集自训练词向量。具体来说,采用gensim开源框架下的word2vec下的CBOW模型,将本文使用的数据集作为词向量训练的语料库进行训练,保存训练好的300维词向量用做后续建模过程中,自训练词向量时具体参数设置见表3。自训练词向量依赖于数据集,数据集不同训练出来的词向量也会不同。而基于通用的大型数据集(如中文维基百科)训练出来的词向量一定程度上可以看作词语的通用表示,降低甚至排除领域的影响。为了进一步探索模型的领域迁移性,本文尝试采用基于通用语料库训练的词向量进行建模。通用语料库的词向量直接采用Shen [36] 等在1.3 GB的中文维基百科数据集上训练好的词向量,该通用词向量包含共计2129000个词语的300维向量。
Table 3. Self-training word vector model parameter setting
表3. 自训练词向量模型参数设置
本实验主要的模型参数有损失函数、训练时的数据批量、初始训练轮次、提前停止训练的指标、dropout的比率。各个情绪类别的LSTM预测器,参数基本设置如表4所示。
Table 4. LSTM predictor basic parameter setting
表4. LSTM预测器基本参数设置
神经网络随着训练周期的增大,容易出现过拟合的现象。在训练过程中,根据测试集的损失表现确定停止训练的周期。图4展示了在训练Love情绪强度预测模型时,训练集以及测试集上损失和平均绝对误差的变化趋势。随着训练周期的增加,训练集的损失和平均绝对误差持续下降,但是在测试集上,前7个周期损失和平均绝对误差基本上处于下降状态,第7周期之后开始回升,说明出现了过拟合现象,因此第7个周期需要提前停止训练。
4.4. 实验结果
在8类情绪的训练集上,按照设计的实验流程(见4.3)训练模型,在测试集上根据前面所确定的评价标准(见4.2)对模型预测能力进行评估,评估结果如表5所示。
从实验结果来看,模型预测情绪强度的效果整体良好。自训练词向量的平均绝对误差在0.13左右,准确率达到了约75%,这反映了预测值和人工标注值之间的距离很近,误差较小,总体来看模型有比较好的预测效果。具体到情绪类别上,根据三个评价标准的表现发现预测效果最优的情绪是Love类别,平均绝对误差仅为0.12,准确率达到了83%,这很可能是因为整个数据集中Love类情绪分布最广泛,构造出来的训练集样本量最大。预测效果比较好的情绪是Anxiety、Joy、Anger、和Sorrow,准确率都达到了73%以上。预测效果相对较差的情绪是Surprise。Surprise训练集数目仅有916条,是训练集最少的情绪类别,因此模型效果不理想。
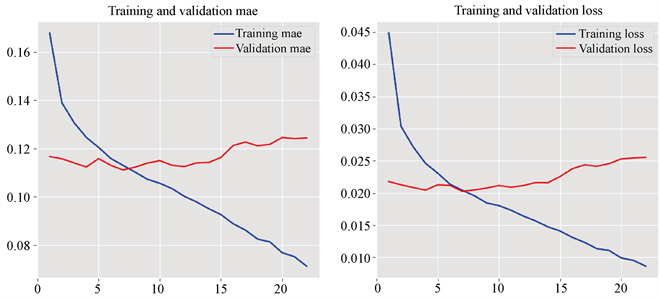
Figure 4. Errors and mae changes in training sets and test sets
图4. 训练集、测试集的误差及mae变化
Table 5. Self-trained word vector and Chinese Wikipedia word vector model experimental results
表5. 自训练词向量及向中文维基百科词量模型实验结果
如前所述,基于中文维基百科词向量的模型实验一定程度上排除了领域的影响。从中文维基百科词向量的实验结果来看,通用的词向量表现相对更好,一定程度上说明模型有着良好的领域适应性,也反映出情绪的表达可能是领域无关的。基于中文维基百科词向量模型比自训练词向量模型的平均绝对误差降低了0.003,提高了约2.4%,准确率提高了2.42%。值得注意的是,基于中文百科词向量的模型主要提升的是Sorrow,Surprise,Hate,Anger等自训练词向量模型表现较差的情绪类别,而对自训练词向量模型表现较好的情绪类别提升较小甚至没有提升。
5. 结论与展望
为了解决KANO模型在体验经济时代所面临的挑战,从海量UGC中自动挖掘用户的体验和感受,本文在情绪轮理论的基础上,提出了一种基于词向量和LSTM的文本情绪强度预测方法,从误差和准确率来看,方法对于预测情绪强度的任务表现良好。
本文从增强模型跨领域预测能力角度出发,进一步研究了两种不同的文本表示方法,基于数据集的自训练词向量和领域无关的通用词向量,发现在解决本文的问题上,通用词向量效果更优。相比于传统的机器学习方法需要人工构建特征,本文的方法省去了人工构建特征环节,可以实现对中文文本自动化、快速地情绪强度抽取,而且在领域扩展上更具灵活性。
利用词向量结合神经网络学习的方法挖掘顾客体验后反馈的情绪,为进一步衡量顾客体验质量做铺垫,比传统的调查问卷方法要更加真实、及时、低成本,对于KANO模型的进化和革新移除了关键的障碍,接下来可以研究基于情绪的KANO模型构建;另一方面,文本情绪强度预测不仅可以用于KANO模型,还可以用于个性化的推荐、垃圾评论识别、舆情监控等诸多方面。未来的研究工作可以从文本表示方法上入手,进一步提高模型对情绪强度预测的跨领域能力。
文章引用
马 彪,李 想. 面向KANO模型的文本情绪强度分布挖掘方法
Mining Method of Text Emotion Intensity Distribution for KANO Model[J]. 服务科学和管理, 2020, 09(01): 61-71. https://doi.org/10.12677/SSEM.2020.91008
参考文献
- 1. 谢彦君. 基础旅游学[M]. 北京: 商务印书馆, 2015.
- 2. 马天. 从满意度到愉悦度: 旅游体验评价的一体化转向[D]: [博士学位论文]. 大连: 东北财经大学, 2017.
- 3. Kao, Y., Huang, L. and Wu, C. (2008) Effects of Theatrical Elements on Experiential Quality and Loyalty Intentions for Theme Parks. Asia Pacific Journal of Tourism Research, 13, 163-174.
https://doi.org/10.1080/10941660802048480 - 4. Plutchik, R. (1962) The Emotions: Facts, Theories and a New Model. Random House, New York.
- 5. Yu, H.-Y., Kim, M.-H. and Bae, B.-C. (2017) Emotion and Sentiment Analysis from a Film Script: A Case Study. Journal of Digital Contents Society, 18, 1537-1542.
- 6. El-Naggar, N., El-Sonbaty, Y. and Abou El-Nasr, M. (2017) Sentiment Analysis of Modern Standard Arabic and Egyptian Dialectal Arabic Tweets. 2017 Computing Conference, London, 18-20 July 2017, 880-887.
https://doi.org/10.1109/SAI.2017.8252198 - 7. Yang, W., Chong, F. and Qian, L. (2018) Construction of a Mul-ti-Dimensional Vectorized Affective Lexicon. In: Zhang, M., Ng, V., Zhao, D., Li, S. and Zan, H., Eds., Natural Lan-guage Processing and Chinese Computing. NLPCC 2018. Lecture Notes in Computer Science, Springer, Cham, 319-329.
https://doi.org/10.1007/978-3-319-99501-4_28 - 8. 홍택은, 김정인, 신주현. (2016) A User Sentiment Classification Using Instagram Image and Text Analysis. Smart Media Journal, 5, 61-68.
- 9. Wang, X., Tang, L. and Kim, E. (2019) More than Words: Do Emotional Content and Linguistic Style Matching Matter on Restaurant Review Helpfulness? International Journal of Hospitality Management, 77, 438-447.
https://doi.org/10.1016/j.ijhm.2018.08.007 - 10. Arai, K., Sakurai, Y., Sakurai, E., Tsuruta, S. and Knauf, R. (2019) Visualization System for Analyzing Customer Comments in Marketing Research Support System. 2019 IEEE World Congress on Services, Milan, 8-13 July 2019, 141-146.
https://doi.org/10.1109/SERVICES.2019.00042 - 11. Chen, Y.S., Chen, L.H., Yamaguchi, T. and Takama, Y. (2015) Visualization System for Analyzing User Opinion. 2015 IEEE/SICE International Symposium on System Inte-gration, Nagoya, Japan, 11-13 December 2015, 646-649.
https://doi.org/10.1109/SII.2015.7405055 - 12. Hwa, L.J. (2018) A Study on Generalization of Emotion Words by Using SNS Hashtags. The Journal of Internet Electronic Commerce Research, 18, 53-63.
- 13. Zhang, L., Dong, W. and Mu, X.M. (2018) Analyzing the Features of Negative Sentiment Tweets. Electronic Library, 36, 782-799.
https://doi.org/10.1108/EL-05-2017-0120 - 14. Suttles, J. and Ide, N. (2013) Distant Supervision for Emotion Classification with Discrete Binary Values. In: Gelbukh, A., Ed., Computational Linguistics and Intelligent Text Processing. CICLing 2013. Lecture Notes in Computer Science, Springer, Berlin, Heidelberg, 121-136.
https://doi.org/10.1007/978-3-642-37256-8_11 - 15. Zou, X.M., Yang, J. and Zhang, J.P. (2018) Sentiment-Based and Hashtag-Based Chinese Online Bursty Event Detection. Multimedia Tools and Applications, 77, 21725-21750.
https://doi.org/10.1007/s11042-017-5531-y - 16. Yuan, H., Lau, R.Y.K., Wong, M.C.S. and Li, C.P. (2018) Mining Emotions of the Public from Social Media for Enhancing Corporate Credit Rating. 2018 IEEE 15th International Conference on e-Business Engineering, Xi’an, 12-14 October 2018, 25-30.
https://doi.org/10.1109/ICEBE.2018.00015 - 17. Ali, I.R., Kolivand, H. and Alkawaz, M.H. (2018) Lip Syncing Method for Realistic Expressive 3D Face Model. Multimedia Tools and Applications, 77, 5323-5366.
https://doi.org/10.1007/s11042-017-4437-z - 18. Magdin, M. and Prikler, F. (2018) Real Time Facial Expression Recognition Using Webcam and SDK Affectiva. The International Journal of Interactive Multimedia and Artificial Intelligence, 5, 7-15.
- 19. Karpouzis, K., Tsapatsoulis, N. and Kollias, S. (2000) Moving to Continuous Facial Ex-pression Space Using the MPEG-4 Facial Definition Parameter (FDP) Set. In: Rogowitz, B.E. and Pappas, T.N., Eds., Human Vision and Electronic Imaging V, Bellingham, 443-450.
https://doi.org/10.1117/12.387182 - 20. Quan, C. and Ren, F. (2010) A Blog Emotion Corpus for Emotional Expression Analysis in Chinese. Computer Speech & Lan-guage, 24, 726-749.
https://doi.org/10.1016/j.csl.2010.02.002 - 21. Mohammad, S.M. and Bravomarquez, F. (2017) Emotion Intensities in Tweets. Proceedings of the 6th Joint Conference on Lexical and Computational Semantics, Vancouver, Canada, August 2017, 65-77.
https://doi.org/10.18653/v1/S17-1007 - 22. Xie, H., Feng, S., Wang, D. and Zhang, Y. (2018) A Novel Attention Based CNN Model for Emotion Intensity Prediction. In: Zhang, M., Ng, V., Zhao, D., Li, S. and Zan, H., Eds., Natural Language Processing and Chinese Computing. NLPCC 2018. Lecture Notes in Computer Science, Springer, Cham, 365-377.
https://doi.org/10.1007/978-3-319-99495-6_31 - 23. Marrese-Taylor, E. and Matsuo, Y. (2017) EmoAtt at EmoInt-2017: Inner Attention Sentence Embedding for Emotion Intensity. Proceedings of the 8th Workshop on Com-putational Approaches to Subjectivity, Sentiment and Social Media Analysis, Copenhagen, September 2017, 233-237.
https://doi.org/10.18653/v1/W17-5232 - 24. Lakomkin, E., Bothe, C. and Wermter, S. (2018) GradAscent at EmoInt-2017: Character- and Word-Level Recurrent Neural Network Models for Tweet Emotion Intensity Detection. Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Copenhagen, September 2017, 169-174.
https://doi.org/10.18653/v1/W17-5222 - 25. Köper, M., Kim, E. and Klinger, R. (2017) IMS at EmoInt-2017: Emotion Intensity Prediction with Affective Norms, Automatically Extended Resources and Deep Learning. Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Copenhagen, Denmark, 50-57.
https://doi.org/10.18653/v1/W17-5206 - 26. Akhtar, M.S., Ghosal, D., Ekbal, A., Bhattacharyya, P. and Kurohashi, S. (2018) A Multi-Task Ensemble Framework for Emotion, Sentiment and Intensity Prediction.
- 27. Ekman, P. (1992) An Argument for Basic Emotions. Cognition & Emotion, 6, 169-200.
https://doi.org/10.1080/02699939208411068 - 28. Plutchik, R. (2001) The Nature of Emotions. American Scientist, 89, 344.
- 29. 张真练, 刘茂福, 胡慧君. 基于联合特征与Bi-LSTM模型的英汉双语文本情绪预测[J]. 武汉大学学报(理学版), 2019(3): 269-275.
- 30. 於雯, 周武能. 基于LSTM的商品评论情感分析[J]. 计算机系统应用, 2018, 27(8): 163-167.
- 31. 张琦, 彭志平. 融合注意力机制和CNN-GRNN模型的读者情绪预测[J]. 计算机工程与应用, 2018, 54(13): 174-180.
- 32. 李松如. 基于循环神经网络的网络舆情文本情感分析技术研究[D]: [硕士学位论文]. 泉州: 华侨大学, 2017.
- 33. 余传明. 基于深度循环神经网络的跨领域文本情感分析[J]. 图书情报工作, 2018, 62(11): 23-34.
- 34. 徐新峰. 基于循环神经网络的中文人名识别的研究[D]: [硕士学位论文]. 大连: 大连理工大学, 2016.
- 35. 龚千健. 基于循环神经网络模型的文本分类[D]: [硕士学位论文]. 武汉: 华中科技大学, 2016.
- 36. Shen, L., Zhe, Z., Hu, R., et al. (2018) Analogical Reasoning on Chinese Morphological and Semantic Re-lations. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Short Papers), Melbourne, Australia, 15-20 July 2018, 138-143.