Operations Research and Fuzziology
Vol.
13
No.
02
(
2023
), Article ID:
64627
,
16
pages
10.12677/ORF.2023.132127
有限理性下不确定参数多目标博弈平衡的 稳定性
陈聪利1,汤卫1,2*,王春1
1贵州大学数学与统计学院,贵州 贵阳
2贵州开放大学信息工程学院,贵州 贵阳
收稿日期:2023年3月6日;录用日期:2023年4月20日;发布日期:2023年4月27日

摘要
本文从有限理性的角度,建立了不确定参数下多目标博弈的有限理性模型,并通过构造特殊的理性函数,证明了在支付函数发生扰动的情况下,该有限理性模型是结构稳定的,并且对弱
-Pareto-NS平衡也是鲁棒的。进一步,我们通过具体算例对其平衡的稳定性进行更加直观的验证分析。
关键词
有限理性,多目标博弈,不确定参数,弱Pareto-NS平衡,稳定性

Stability of Equilibria for Multiobjective Games with Uncertain Parameters under Bounded Rationality
Congli Chen1, Wei Tang1,2*, Chun Wang1
1School of Mathematics and Statistics, Guizhou University, Guiyang Guizhou
2School of Information Engineering, Guizhou Open University, Guiyang Guizhou
Received: Mar. 6th, 2023; accepted: Apr. 20th, 2023; published: Apr. 27th, 2023

ABSTRACT
From the perspective of bounded rationality, this paper establishes a bounded rationality model of multiobjective games with uncertain parameters, and proves that the bounded rationality model is structurally stable and weak
-Pareto-NS equilibria is robust when the payoff function is disturbed by constructing a special rationality function. Further, the stability of equilibria for the game is verified and analyzed more intuitively by a specific example.
Keywords:Bounded Rationality, Multiobjective Games, Uncertain Parameters, Weak Pareto-NS Equilibria, Stability

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
在经典的博弈模型中,局中人被假定为完全理性的,即每个局中人在一定的约束条件下总是能够选出使自己利益最大的策略。然而现实生活中的人并不是完美的,致使这一假设过于理想化。1978年Nobel经济学奖获得者Simon [1] 对该假设提出质疑和批判。Anderlini和Canning [2] 于2001年建立了有限理性抽象模型
:
为问题空间,
表示一个博弈;X表示行为空间,
是一个策略;
是可行映射,由T诱导出集值映射
,其中
,
;集值映射
的图
,
为理性函数;
,
,
表示博弈
的
-平衡点集,它对应有限理性,
表示博弈
的平衡点集,它对应于完全理性。同时假设
和
均是紧度量空间,集值映射
紧值且是连续的,
连续,而
,
。此外,给出该模型
-平衡鲁棒和结构稳定的定义,并证明模型
对
-平衡是鲁棒的当且仅当模型
是结构稳定的。由于该模型的假设条件过于苛刻,n人非合作博弈和广义博弈等博弈模型无法满足,导致其应用受到了很大的限制。
俞建等 [3] [4] 将模型
的假设条件减弱为:
是完备度量空间,
是紧度量空间,集值映射
是上半连续的,
是下半连续的,而
,
。这样,
,
,
必是X中的闭集,从而是紧集。进而减弱了
-平衡鲁棒和结构稳定成立的条件,并得到相关稳定性与鲁棒性结论。在博弈平衡存在的前提下,俞建等 [5] [6] [7] [8] 对n人非合作博弈、广义博弈、多目标博弈、广义多目标博弈等博弈问题构造了有限理性模型,并得到相应的稳定性结论。此外,王红蕾等 [9] [10] 通过定义理性函数,证明了大多数的最优化问题及多目标最优化问题都是结构稳定的和鲁棒的。
由于现实生活中存在许多的不确定因素,如信息的不完全、气候环境等,在一定程度上影响着策略的选取。1994年,在不确定参数变化范围是已知的假设下,Zhukovskii [11] 首先提出不确定参数下非合作博弈Nash-Slater平衡(简称NS平衡)的概念,并证明了该平衡的存在性。在此基础上,许多学者将不确定参数引入到经典的博弈模型中,提出相应的平衡概念,并得到其存在性及通有稳定性等结论 [12] [13] [14] [15] 。而在博弈过程中,策略选取不仅受到决策环境的影响,还受到局中人有限理性程度的影响,将不确定性和有限理性结合建立的数学模型会更加贴近实际生活。
近年来,已有部分学者从有限理性的角度研究不确定参数下博弈平衡的稳定性,他们基于不确定参数下的博弈模型及其平衡的定义,建立对应的有限理性模型与理性函数,得到其稳定性等结论 [16] [17] [18] 。然而现实生活中局中人的支付函数往往是多目标的,而这方面的研究目前还比较少。因此,我们将建立带有特殊理性函数的不确定参数下多目标博弈有限理性模型,研究不确定参数下多目标博弈平衡的稳定性。进一步,通过算例写出理性函数的具体表达式,同时借助Matlab软件画图来直观体现不确定参数及扰动参数对其平衡稳定性的影响。
2. 预备知识
本文记
为实数集或1维实空间,
为实k维欧氏空间,
为全体正实数构成的集合。
首先介绍不确定参数下多目标博弈模型及其该博弈的弱Pareto-NS平衡的定义,可参见文献 [14] 。
不确定参数下多目标博弈的一般模型
,其中
是局中人集合,
为目标集,
,
是局中人i的策略集,Y是不确定参数集合,
,
,
是局中人i的向量值支付函数,记
,
,
,
。在该博弈中每个局中人选择各自的策略,最大化自己的支付函数。
定义2.1
称为不确定参数下多目标博弈
的弱Pareto-NS平衡,若满足
1)
,
,
;
2)
,
,其中
,
。
定义2.2设X,Z是两个度量空间,集值映射
,
。
1) 如果对Z中的任意开集U,
(或
),存在x的开邻域
,使
,有
(或
),则称集值映射
在x上是上半连续的(或下半连续的);
2) 如果集值映射
在x即上半连续又下半连续,则称集值映射
在x是连续的;
3) 如果
,集值映射
在x是连续的(或上半连续的,或下半连续的),则称集值映射
在X上是连续的(或上半连续的,或下半连续的)。
Yu和Yu在文献 [3] 中给出如下定义和稳定性结论。
定义2.3
,若
,
,当
,
时,有
,则称
在
对
-平衡是鲁棒的,其中h是X上的Hausdorff距离。
定义2.4如果平衡映射
在
是连续的,则称
在
是结构稳定的。
引理2.1设
为完备度量空间,
为紧度量空间,
是上半连续的且
,
是非空紧集,
是下半连续的且
,
,则
1) 平衡映射
是一个usco映射,即
,E在
是上半连续的,且
是紧集;
2) 存在
中的一个稠密剩余集Q,使
,
在
是结构稳定的;
3) 如果
在
是结构稳定的,则
在
对
-平衡是鲁棒的;
4)
,
,
,有
,其中h是X上的Hausdorff距离;
5) 如果
,且
是单点集,则
在
是结构稳定的,在
对
-平衡也是鲁棒的。
引理2.2设X,C,Z是三个度量空间,其中Z是紧的,
是X中的一列非空紧集,
,其中h是X上的Hausdorff距离,A是X中的一个非空紧集,
,
连续,
,其中
为
上一连续函数,
是C中的一个序列,
,则
。
3. 不确定参数下多目标博弈平衡的稳定性
在本节中,假设
和
为非空紧度量空间,函数空间
定义如下:
是连续的,存在
,使
,
,有
;
,
。
,用
表示不确定参数下多目标博弈
的所有弱Pareto-NS平衡的集合,由
的定义知,
。
,
,定义距离如下
。
引理3.1
是一个完备度量空间。
证明设
是
中的任意一个Cauchy列,即
,存在正整数
,使
,有
。
从而,
,
,都有
,
这说明
是
中的Cauchy列,由
的完备性知,存在
,使
。
令
,由上式得
,
,
且易知
在
连续,故
,进而有
。
对
,有
因此,
。
因
,
,使
,
,
;
,
。
又因
是紧集,不妨设
。
,因
由于
在
上是连续的,可得
。
同理可得,
,进而
,有
。又
在
上是连续的,且
,得
。
从而,
,
,
;
,
。综上可得
,
是一个完备度量空间。 □
下面,我们构造不确定参数下多目标博弈的有限理性模型
,其中
是博弈空间,
每个
表示不确定参数下多目标博弈,
为策略集,Y是不确定参数集,
为可行映射,由J诱导出行为映射
。定义
,则对
,有
。
显然,
连续且
为非空紧集。定义理性函数
为
,
其中,
,
分别表示k维和
维欧氏空间中的曼哈顿距离,即
,
分别为
向量和z向量各个元素绝对值之和。
以下我们给出理性函数
的一些相关结果。
引理3.2 (1)
,
,有
;
(2)
当且仅当
。
证明(1)
,
,
。
(2) 如果
,那么
, (3.1)
。 (3.2)
由(3.1)式,
,
,有
。 (3.3)
如果
不满足定义2.1条件(1),则
,
,使
。
对
,有
,
由于
是紧的,则
,
这与(3.3)式矛盾,故
满足定义2.1条件(1)。
另一方面,如果
不满足定义2.1条件(2),则
,使
。
对
,有
。
由于
是紧的,则有
,
这与(3.2)式矛盾,故
满足定义2.1条件(2)。从而
。
反之,如果
,则有
,
,
; (3.4)
,
。 (3.5)
由(3.4)式,
,令
,则
。此时,取
,令
,其中
,
,则
,有
故
。
由结论(1),得
。
从而,得
。
由(3.5)式,
,令
,则
。取
,令
,其中
,则
,有
故
。
又由结论(1),得
。
进而有
。
综上可得,
。 □
引理3.3
在
上是连续的。
证明
,
,
,且
,我们要证
。
,
,令
,
,
,
,
则
,
在
上是连续的,
,
在
上是连续的,其中
,
都是紧集。
,
,由于
,则对
,存在正整数
,使
,有
得
。
因
,
是紧集,且
,由引理2.2,可得
,
进而有,
。
另一方面,
,由于
,则对
,存在正整数
,
,有
和
同时成立。
又
在
是连续的,且
,
,存在正整数
,
,有
和
同时成立。
取
,
,有
因Y,
是紧集,由引理2.2,可得
。
从而,
。 □
注3.1
,
,
定义为不确定参数下多目标博弈
的弱
-Pareto-NS平衡集,它描述了不确定参数下多目标博弈中的有限理性。特别地,由引理3.2 (2)可知,当
时,
为博弈
的弱Pareto-NS平衡集,它刻画了不确定参数下多目标博弈中的完全理性。
定理3.1对不确定参数下多目标博弈的有限理性模型
,以下结论成立。
1) 博弈
的弱Pareto-NS平衡映射
是一个usco映射;
2) 存在
中的一个稠密剩余集Q,使
,
在
是结构稳定的;
3) 如果
在
是结构稳定的,则
在
对弱
-Pareto-NS平衡是鲁棒的;
4)
,
,
,有
,其中
是
上的Hausdorff距离;
5) 如果
,且
是单点集,则
在
是结构稳定的,在
对弱
-Pareto-NS平衡也是鲁棒的。
证明
是完备度量空间,
是紧集,
是上半连续的,
,
,且
是非空紧集。由引理3.3知,
是下半连续的,故
满足引理2.1的所有假设条件,因此引理2.1的结论对
也全成立。 □
4. 算例
下面,我们通过算例进一步详细说明本文主要结果定理3.1,即有限理性下不确定参数多目标博弈平衡的稳定性。
例4.1我们考虑二人二策略不确定参数下双目标博弈
,局中人集合
,纯策略集
,局中人1和2的混合策略集分别为
,
,其中
表示局中人1选择策略1的概率,
表示局中人2选择策略1的概率,记
,
,目标集
,目标1和2对应的支付矩阵分别为
和
,且
,
,
,
为严格对角占优对称矩阵,且
。不确定参数集
,
,则局中人1,2的期望支付函数分别为
;
。
设
为博弈
的弱Pareto-NS平衡,那么
,
;
,
;
,
。
不妨设
,可得该博弈的弱Pareto-NS平衡集为
。
理性函数
,记
,
,有
,其中
;
,其中
;
。
令
,
,
得博弈
的弱Pareto-NS平衡集为
。
因
,有
1) 当
时,
使
取最小,得
;
2) 当
时,
使
取最小,得
。
对1)式,当
时,
使
取最大,得
;当
时,
使
取最大,得
;
对2)式,当
时,
使
取最大,得
;当
时,
使
取最大,得
。
从而,得
(4.1)
又
,由对称性得,
(4.2)
又
,有
3) 当
时,
使
取最小,得
;
4) 当
时,
使
取最小,得
。
对3)式,
使
取最大,得
,
;对4)式,
使
取最大,得
,而当
时,
恒小于0,故舍去。
从而,得
,
。 (4.3)
综上,由(4.1),(4.2),(4.3)式可得理性函数为
接下来考虑对博弈
的期望支付函数进行扰动,令
,
,
其中,
,
。
记期望支付函数发生扰动后的博弈为
,设
为博弈
的弱Pareto-NS平衡,那么
;
;
解得
。
可得博弈
的弱Pareto-NS平衡集为
。
扰动后理性函数
,其中
;
;
。
同理可得,
(4.4)
(4.5)
,
。 (4.6)
进而有,
接下来我们通过理性函数图对上述例子进行直观说明,记
。
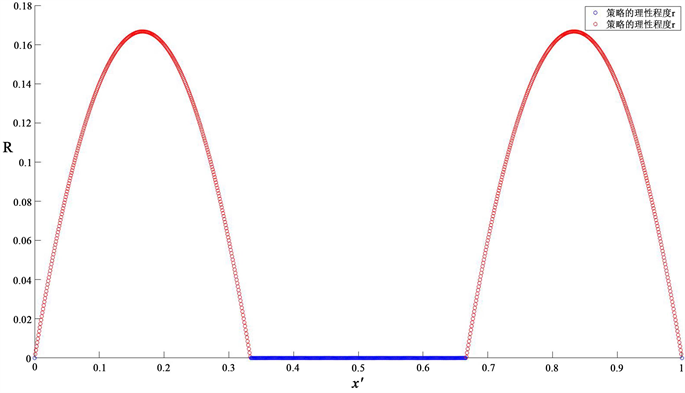
Figure 1.
and players 1 and 2 choose the same strategy
图1.
且局中人1和2选择相同的策略
图1表明,若局中人1和2选择相同的策略,即
时,有
,对应于完全理性。
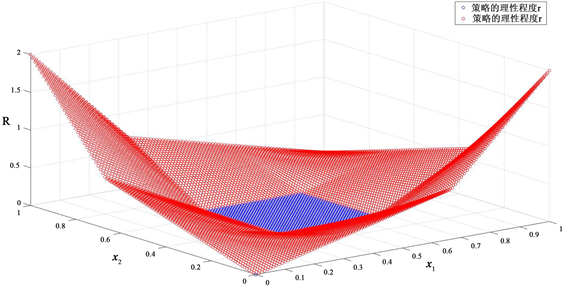
Figure 2.
and players 1 and 2 choose all strategies
图2.
且局中人1和2选择所有策略
图2表明,若
,则
,对应于完全理性;若
,则
。当
时,
,对应于有限理性,且越偏离平衡集对应的理性函数值越大,表明局中人的理性程度越低,且当
时,
达到最大值,此时局中人的理性程度是最低的。其中图1只是图2的一部分。
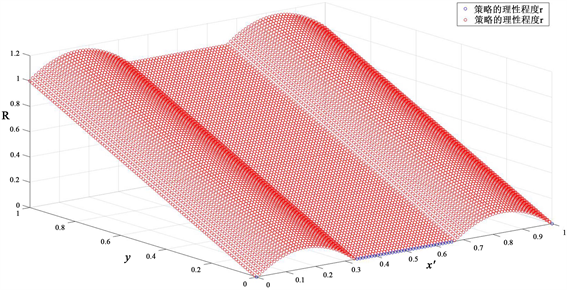
Figure 3.
and players 1 and 2 choose the same strategy
图3.
且局中人1和2选择相同的策略
图3表明,当
时,
,此时局中人是完全理性的;当
时,
,且选取的
越偏离平衡集
,
越大。当
时,随着y值增大,对应的理性函数值
逐渐增大,体现了不确定参数对局中人理性程度的影响,即表明局中人对不确定参数的态度是悲观的和保守的。
当对期望支付函数进行扰动时,我们进一步观察扰动参数
对理性函数值的影响。为了作图方便,接下来我们只考虑局中人1和2选择相同策略的情形。
图4.
且
图4表明,当
时,扰动参数
越大,对应的
越小,说明局中人的理性程度越来越高;当
时,无论扰动参数
如何变化,
,说明局中人处于完全理性状态;当
时,扰动参数
越大,对应的
越大,说明局中人的理性程度越来越低。即若
,则
;若
,则
。当
时,图4与图1一致。
图5.
且
图6.
且
图7.
且
图5~7表明,当
时,有
;当
时,扰动参数
越大,对应的理性函数值
越大;反之,随着扰动参数
逐渐减小,
对局中人的理性程度扰动也越来越小;当
时,有
,此时局中人的理性程度非常高,趋近于完全理性。
显然,该算例满足引理3.1~3.3,进而满足引理2.1的所有条件,故定理3.1成立。即当博弈
的期望支付函数
发生扰动时,有限理性模型
在
是结构稳定的,且对弱
-Pareto-NS平衡是鲁棒的。进而,有限理性下该不确定参数多目标博弈
的弱Pareto-NS平衡是稳定的。
5. 总结
本文建立了不确定参数下多目标博弈的有限理性模型,并基于弱Pareto-NS平衡的定义构造理性函数,得到了该有限理性模型的稳定性结论。进一步,我们通过算例4.1对不确定参数下多目标博弈平衡的稳定性进行了直观的刻画和分析。
基金项目
本文获得贵州省科技计划项目(黔科合基础-ZK[2022]一般168);国家自然科学基金项目(No. 11271098);贵州大学引进人才科研项目(No. [2017]59)。
文章引用
陈聪利,汤 卫,王 春. 有限理性下不确定参数多目标博弈平衡的稳定性
Stability of Equilibria for Multiobjective Games with Uncertain Parameters under Bounded Rationality[J]. 运筹与模糊学, 2023, 13(02): 1242-1257. https://doi.org/10.12677/ORF.2023.132127
参考文献
- 1. Simon, H.A. 管理行为[M]. 杨硕, 等, 译. 北京: 北京经济学院出版社, 1991.
- 2. Anderlini, L. and Canning, D. (2001) Structural Stability Implies Robustness to Bounded Rationality. Journal of Economic Theory, 101, 395-422. https://doi.org/10.1006/jeth.2000.2784
- 3. Yu, C. and Yu, J. (2006) On Structural Stability and Robustness to Bounded Rationality. Nonlinear Analysis, 65, 583-592. https://doi.org/10.1016/j.na.2005.09.039
- 4. Yu, C. and Yu, J. (2007) Bounded Rationality in Multiobjective Games. Nonlinear Analysis, 67, 930-937.
https://doi.org/10.1016/j.na.2006.06.050
- 5. 俞建. 博弈论与非线性分析[M]. 北京: 科学出版社, 2008.
- 6. 俞建. 有限理性与博弈论中平衡点集的稳定性[M]. 北京: 科学出版社, 2017.
- 7. 俞建. 几类考虑有限理性平衡问题解的稳定性[J]. 系统科学与数学, 2009, 29(7): 999-1008.
- 8. 俞建, 贾文生. 有限理性研究的博弈论模型[J]. 中国科学: 数学, 2020, 50(9): 1375-1386.
- 9. 王红蕾, 俞建. 有限理性与多目标问题解的稳定性[J]. 运筹学学报, 2008, 12(1): 104-108.
- 10. 王红蕾, 俞建. 有限理性与多目标最优化问题弱有效解集的稳定性[J]. 中国管理科学, 2008, 16(4): 155-158.
- 11. Zhukovskii, V.I. (1994) Linear Quadratic Differential Games. Naoukova Doumka, Kiev.
- 12. 杨哲, 蒲勇健. 广义不确定下广义多目标博弈弱Pareto-Nash均衡点集的存在性与本质连通区[J]. 系统科学与数学, 2011, 31(12): 1613-1621.
- 13. 杨哲, 蒲勇健. 不确定性下多主从博弈中均衡的存在性[J]. 控制与决策, 2012, 27(5): 736-740.
- 14. 杨哲, 蒲勇健, 郭心毅. 不确定性下多目标博弈中弱Pareto-NS均衡的存在性[J]. 系统工程理论与实践, 2013, 33(3): 660-665.
- 15. 赵薇, 杨辉, 吴隽永. 不确定参数下群体博弈均衡的存在性与通有稳定性[J]. 应用数学学报, 2020, 43(4): 627-638.
- 16. 陆辰超, 邬冬华. 不确定性下非合作博弈的有限理性模型及良定性[J]. 应用数学与计算数学学报, 2016, 30(3): 339-348.
- 17. 王能发. 有限理性下不确定性博弈均衡的稳定性[J]. 应用数学学报, 2017, 40(4): 562-572.
- 18. Zhao, W., Yang, H., Deng, X.C. and Zhong, C.Y. (2021) Stability of Equilibria for Population Games with Uncertain Parameters under Bounded Rationality. Journal of Inequalities and Applications, 2021, Article No. 15.
https://doi.org/10.1186/s13660-020-02544-0
NOTES
*通讯作者。












