Computer Science and Application
Vol.
08
No.
10
(
2018
), Article ID:
27238
,
7
pages
10.12677/CSA.2018.810170
Video Pedestrian Detection Based on Deep Learning
Xiaomin Tong, Xiang Ji, Yin Tong
China Academy of Electronics and Information Technology, Beijing

Received: Oct. 6th, 2018; accepted: Oct. 17th, 2018; published: Oct. 24th, 2018

ABSTRACT
In recent years, with the extensive application of depth learning in the field of computer vision, video moving target detection based on deep learning has been favored by many scholars. The basic principle of this method is to train a classifier based on deep neural network using a large number of target sample data, and then detect the target online through the classifier. Since the depth neural network can describe the target features more deeply through multi-layer representation, the detection method based on deep learning has the advantage of being able to accurately detect targets with features from training data. For this particular application of moving target detection, the limitation of this method lies in that it does not use the target motion information and the detection results are prone to false alarm targets. In this paper, GMM method is combined with deep neural network to make full use of the target appearance and motion information in order to obtain more accurate detection results. The experimental verification was carried out on the monitoring data collected from the exhibition booth of the State-owned Enterprise Exhibition in 2017. The results show that compared with the detection method without fusion of motion information, the accuracy of pedestrian detection is improved by 3.8%.
Keywords:Pedestrian Detection, Motion Detection, Deep Learning, GMM Modeling
基于深度学习的视频行人目标检测
仝小敏,吉祥,仝茵
中国电子科学研究院,北京
收稿日期:2018年10月6日;录用日期:2018年10月17日;发布日期:2018年10月24日

摘 要
近年来,随着深度学习在计算机视觉领域的广泛应用,基于深度学习的视频运动目标检测受到广大学者的青睐。这种方法的基本原理是利用大量目标样本数据训练一个基于深度神经网络的分类器,然后通过分类器在线检测目标。由于深度神经网络能够通过多层表示的方式更加深刻的描述目标特征,基于深度学习的检测方法优点在于能够准确检测具有训练数据中目标特征的目标。针对视频运动目标检测这个特定的应用,这种方法的局限性在于没有利用目标运动信息,检测结果容易出现虚警目标。本文将GMM建模方法与深度神经网络相结合,充分利用目标外观特征和运动信息,以期获得更准确的检测结果。在2017年央企双创展实地采集的展台监控数据上进行了实验验证。结果表明,本文方法相比于不融合运动信息的检测方法,行人检测准确率提高3.8%。
关键词 :行人检测,运动检测,深度学习,GMM建模

Copyright © 2018 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
随着计算机计算技术和存储技术的快速发展,视频信息占人们接受信息的比重越来越大,对视频的智能分析也越来越重要。其中视频目标检测是对视频分析的重要切入点,因此不管是在学术界还是在商业界,目标检测都是研究和应用的一个热点。传统的视频运动目标检测方法包括背景差法、帧差法、光流法,这类方法 [1] [2] [3] 的主要原理是基于像素级分析来确定运动目标相对于背景图像的差异,检测运动目标所在的位置。尽管学者们在这类方法基础上进行了很多创新改进 [4] [5] [6] ,但是这类自底向上的方法并未利用目标外观等宏观信息,检测结果容易受光照变化、目标交叉遮挡、目标与背景相似、阴影等因素影响。此外,针对视频行人检测这个特定的应用,仅仅利用目标运动信息并不能精确定位行人目标,尤其是目标之间有交叠、部分遮挡等情况下,无法区分不同的目标。
深度学习是目前机器学习在实际应用中最成功的一种方法,在自然图像分类、通用目标检测、语义分割等视觉领域取得了突破性的成绩。将深度学习用于视频运动目标检测的方法 [7] [8] [9] ,能够有效描述目标外观、结构、色彩等视觉特征,从而检测定位目标。这类方法的局限性在于没有利用目标运动信息,导致与目标外观相似的虚警目标被误检。
本文致力于复杂场景下的视频行人目标检测,将深度学习方法引入传统视频运动目标检测方法,利用深度学习方法对行人目标准确、全面的外观描述的同时,挖掘行人目标运动信息,克服传统运动检测出现空洞、易受阴影、光照变化影响等难题,提高行人检测准确率。运动检测采用背景建模法中比较成熟的混合高斯建模法GMM [6] ,有效克服光照变化,深度学习采用YOLOv3深度神经网络模型 [10] ,实现行人与背景的二分类,解决目标与背景相似的问题,二者充分融合,准确检测行人目标。
2. 本文算法
2.1. 算法流程
本文算法流程如图1所示。首先利用公开数据集离线训练YOLOv3行人检测模型参数,利用不同
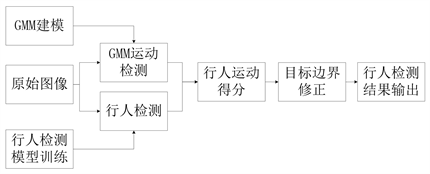
Figure 1. Algorithm flow chart of our detection
图1. 本文检测流程图
光照下采集的背景图像进行GMM背景建模。然后将原始图像分别输入GMM模型和行人检测模型,分别获得GMM运动检测结果和行人目标检测结果,并利用运动检测结果对GMM模型进行及时更新。根据运动检测结果计算每个检测到的行人的运动得分,最终获得行人检测结果。该方法的好处在于利用运动信息去除场景中检测到的虚警目标,提高检测精度。
2.2. GMM运动检测
采用基于混合高斯模型的背景差算法对当前帧图像进行运动前景提取,得到的前景图记为I。 表示一个权重为w的单高斯模型,假设对图像中坐标为 的点处混合高斯模型为 (num表示混合高斯模型所包含的单高斯模型的数目),那么前景提取公式如下:
(1)
式(1)中, 为当前输入原始图像, 为前景提取阈值,可以为固定阈值,也可取为自适应的(如取所有权重中的次小值)。
依据检测结果,按照如下公式对混合高斯模型进行及时更新。
(2)
(3)
(4)
其中 为第i个高斯模型 的均值, 为第i个高斯模型的方差。 为混合高斯模型的学习率,且 ,背景模型的更新速度取决于 的取值。 表示像素点与 匹配与否,匹配则为1,否则为0。当不匹配时,不对高斯模型的均值和方差进行更新。
(5)
(6)
模型更新后对权重进行归一化处理,并对多个高斯模型按照权重高低重新排序。
2.3. YOLO行人检测
YOLO是一个全新的方法,把一整张图片一下子应用到一个神经网络中去。网络把图片分成不同的区域,然后给出每个区域的边框预测和概率,并依据概率大小对所有边框分配权重。最后,设置阈值,只输出得分(概率值)超过阈值的检测结果。YOLOv3是YOLO最新版本,无论从速度和准确率方面来讲,都是最实用的。其检测过程主要包括如下几个步骤:
1) 边界框预测
YOLOv3的anchor boxes通过聚类的方法得到。对每个bounding box预测四个坐标值(tx, ty, tw, th),对于预测的cell (一幅图划分成S × S个网格cell)根据图像左上角的偏移(cx, cy),以及之前得到bounding box的宽pw和高ph可以对bounding box进行预测。在训练bounding box几个坐标值的时候采用了sum of squared error loss (平方和距离误差损失),因为这种方式的误差可以很快的计算出来。YOLOv3对每个bounding box通过逻辑回归预测一个物体的得分,如果预测的这个bounding box与真实的边框值大部分重合且比其他所有预测的要好,那么这个值就为1。如果overlap没有达到一个阈值(这里设定的阈值是0.5),那么这个预测的bounding box将会被忽略,也就是会显示成没有损失值。
2) 分类
每个框预测分类,bounding box使用多标签分类(multi-label classification)。没有使用softmax分类,只是使用了简单的逻辑回归进行分类,采用的二值交叉熵损失(binary cross-entropy loss)。
3) 跨尺度的预测
YOLOv3在三个不同的尺度预测boxes,使用的特征提取模型通过FPN (feature pyramid network)网络上进行改变,最后预测得到一个3d tensor,包含bounding box信息,对象信息以及多少个类的预测信息。使用这样的方式使得模型可以获取到更多的语义信息,模型得到了更好的表现。YOLOv3依然使用k-Means聚类来得到bounding box的先验,选择9个簇以及3个尺度,然后将这9个簇均匀的分布在这几个尺度上。
4) 特征提取
yolov3的特征提取模型是一个杂交的模型,它使用了yolov2,Darknet-19以及Resnet,这个模型使用了很多有良好表现的3 × 3和1 × 1的卷积层,也在后边增加了一些shortcut connection结构。最终有53个卷积层,因此被称作Darknet-53 (图2)。
2.4. 行人运动打分
记行人检测结果中第i个目标为 ,在当前图像中对应的区域为 ,那么行人 的运动得分 计算方式如下:
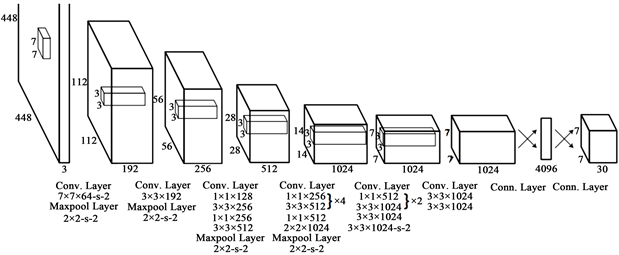
Figure 2. Network structure for object detection
图2. 目标检测网络结构
(7)
(8)
(9)
若 大于给定阈值,则认为 为正确检测到的行人目标,反之,则认为 为虚警目标,从检测结果中去除。此处所用阈值的含义为前景面积占目标区域面积的比例,本文实验中取0.5。若为正确检测的行人目标,则用当前前景区域边界作为目标检测结果输出,实现对目标检测边界的修正,并将修正后的检测结果进行输出。
3. 实验结果
本文方法在2017年央企双创展中实地应用,主要通过统计各个展台前参观人数检测分析各个展台热度。数据源为187路海康网络摄像头,通过对每一路摄像头轮流访问获取并处理当前捕获的图像帧,统计当前展厅前参观人数。在Intel(R) Core(TM) i5-3470 CPU@3.20GHz的处理器上每帧图像处理耗时越3秒,这样每个展台前摄像头的两次访问间隔约为10分钟,能够满足展台热度分析需求。图3所示为行人检测结果,(a)~(f)分别表示不同区域检测结果。橘色框为YOLOv3 [10] 检测结果,可以看出,检测结果中有许多外观与行人特征相像的虚假目标,并且正确检测的目标区域比真实目标区域偏大。红色框为本文方法检测结果,利用运动检测信息,去除了检测结果中的虚警目标,同时,使得检测到的行人区域更加精确。
对双创展举办期间的行人检测准确率进行统计,并与GMM和yolov3方法从检测率、漏检率、虚警率等三方面进行对比分析,如表1所示。可以看出,由于受到阴影的影响,GMM方法 [6] 检测结果中存在较多虚警目标,yolov3方法 [10] 未利用目标运动信息,容易检测到外观与行人特征相像的虚假目标。相比与GMM和yolov3,本文方法融合外观特征和运动特征,能够有效降低虚警率,从而提高检测准确率。本文方法的检测准确率相比于YOLO,提高了3.8%。

Figure 3. Pedestrian detection result
图3. 行人检测结果

Table 1. Detection result statistics and comparison by different algorithms
表1. 不同方法的检测结果统计对比
检测率P、漏检率M、虚警率W的计算公式如下。
(10)
(11)
(12)
其中 表示检测到目标的个数, 表示检测到的目标中真实目标的个数, 表示场景中真实目标的个数, 表示未被检测到目标的个数。
4. 结论
本文提出了一种融合运动检测信息和深度学习的视频行人检测方法,利用运动检测信息去除深度学习检测目标中的虚警目标。相比于只利用深度学习模型检测行人的方法,本文方法有效的去除了虚警目标,提高了行人目标的检测准确率。本文方法的局限性在于对于深度学习检测结果中的漏检没有做相应的处理,如何利用运动检测结果降低漏检率是下一步研究方向。
致谢
对本文的创作给予指导和帮助的同事朋友,在此一并感谢。
基金项目
本文受到中电科集团创新项目“面向国家治理体系和治理能力的XX云平台”资助。
文章引用
仝小敏,吉 祥,仝 茵. 基于深度学习的视频行人目标检测
Video Pedestrian Detection Based on Deep Learning[J]. 计算机科学与应用, 2018, 08(10): 1558-1564. https://doi.org/10.12677/CSA.2018.810170
参考文献
- 1. 陈海永, 郄丽忠, 杨德东, 等. 基于超像素信息反馈的视觉背景提取算法[J]. 光学学报, 2017, 37(7): 0715001.
- 2. 宋涛, 李鸥, 崔弘亮. 基于场景感知的运动目标检测方法[J]. 电子学报, 2016, 44(11): 2625-2632.
- 3. 张应辉, 刘养硕. 基于帧差法和背景差法的运动目标检测[J]. 计算机技术与发展, 2017, 27(2): 25-28.
- 4. Prashant, D., Pratik, S. and Suman, K.M. (2015) Fast and Accurate Foreground Background Separation for Video Surveillance. Lec-ture Notes in Computer Science, 9124, 96-103.
- 5. Zhu, W.J., Wang, G.L., Tian, J., Qiao, Z.T. and Gao, F.Q. (2018) Detection of Moving Objects in Complex Scenes Based on Multiple Features. Acta Optica Sinica, 38, 0612004. https://doi.org/10.3788/AOS201838.0612004
- 6. 唐洪良, 黄颖, 黄淮, 杨成顺, 黄宵宁. 改进的自适应高斯混合模型运动目标检测算法[J]. 现代电子技术, 2017(11): 65-67.
- 7. Dai, J., Li, Y., He, K. and Sun, J. (2016) R-FCN: Object Detection via Region-Based Fully Convolutional Networks. CVPR.
- 8. Redmon, J., Divvala, S., Girshick, R. and Farhadi, A. (2016) You Only Look Once: Unified, Real-Time Object Detection. CVPR.
- 9. Redmon, J. and Farhadi, A. (2016) YOLO9000: Better, Faster, Stronger. CoRR, abs-1612-08242.
- 10. Redmon, J. and Farhadi, A. (2018) YOLOv3: An Incremental Improvement. CoRR, abs-1804-02767.