Computer Science and Application
Vol.
10
No.
02
(
2020
), Article ID:
34215
,
10
pages
10.12677/CSA.2020.102027
Design of Intelligent Voice Customer Service System Based on Knowledge Graph
Chao Li1, Zhao Qiu1*, Xiangsheng Huang2, Jianzheng Hu3, Jinye Cai1
1School of Computer and Cyberspace Security, Hainan University, Haikou Hainan
2Institute of Automation, Chinese Academy of Sciences, Beijing
3China Communications Second Survey and Design Institute of Navigation Engineering, Wuhan Hubei

Received: Jan. 27th, 2020; accepted: Feb. 11th, 2020; published: Feb. 18th, 2020

ABSTRACT
This article introduces mainstream smart customer service implementation schemes, and proposes a design scheme of a voice recognition intelligent customer service system based on knowledge graph. Voice recognition is used to obtain the content of the questions raised by users, various natural language processing technologies are used to model the questions and extract key information, the knowledge map is combined in the field, and the answer is retrieved to the questions that meet the requirements. The results are fed back to the user to complete the Q & A interaction. The cost of manual customer service is reduced and the efficiency of the customer service system is improved.
Keywords:Intelligent Customer Service System, Voice Recognition, Knowledge Graph

基于知识图谱的智能语音客服系统设计
李超1,邱钊1*,黄向生2,胡建政3,蔡金晔1
1海南大学计算机与网络空间安全学院,海南 海口
2中国科学院自动化研究所,北京
3中交第二航务工程勘察设计院,湖北 武汉

收稿日期:2020年1月27日;录用日期:2020年2月11日;发布日期:2020年2月18日

摘 要
本文介绍了主流的智能客服实现方案,并提出了一种基于知识图谱的语音识别智能客服系统的设计方案。通过语音识别的方式获取用户提出的问题内容,利用各项自然语言处理技术对问题进行建模并提取关键信息,结合该领域的知识图谱,检索出符合要求的问题答案,最后把消除歧义的最终结果反馈给用户,完成问答交互。能够有效削减人工传统客服的各类成本开销,并利用智能客服系统提高工作效率。
关键词 :智能客服,语音识别,知识图谱

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
目前,人工客服已成为企业运营中的一项庞大的经费支出 [1]。随着信息智能化飞速发展,智能客服系统逐渐出现在人们的视野中,它本质上是一种问答系统,但是结合各个领域的专业知识库,以及多种自然语言处理技术的运用下,智能客服系统由于自身的诸多优点,正在快速地发展成为代替人工客服的一种优良的解决方案 [2]。
2. 传统客服与智能客服
2.1. 传统客服的问题与缺点
传统客服模式使用客服人员,通过接听电话和即时聊天等方式接收用户提出的问题信息以及咨询信息,根据客服人员对问题的理解给出问题的答案 [3]。但传统客服存在以下突出的问题:
1) 运行成本高。传统客服消耗大量人力资源,硬件资源开销非常大,且需要定期升级更换;在互联网的快速发展下,客服人员需要掌握的专业知识量将会迅速增长,培训客服人员的费用也会变高。这都增加了系统的运行成本。
2) 工作效率低。人工服务人员的专业知识素养,以及工作经验,会影响客服系统的工作效率,用户数量的增加会导致客服人员工作量变大,将会降低系统工作的效率。在晚间闲时段,用户咨询量减少,仍占据着工作人员的工作时间。
3)用户体验差。由于人员限制等因素的限制,会出现系统满负荷高强度运行的情况,此时,用户在进行咨询的时候,就有可能会遇到“占线”的情况;由于人员自身专业知识素养,以及工作经验的约束,无法完成用户提出的请求,严重影响用户的使用体验。
2.2. 智能客服系统简介
由于人工智能技术的兴起,人们开始尝试使用计算机模型来代替人类的一些具体工作,在提高工作效率的同时,节约了大量的人力资源,以及其他的大量硬件资源。客服系统中也开始逐渐有了计算机模型的使用 [4]。智能客服系统,即一种人机交互对话系统。该类系统有很多的应用,譬如,智能聊天机器人,手机语音助手,电商平台智能客服系统等等 [5]。
智能客服系统的分类方式多种多样,其中使用的关键技术也是各有优势,有根据接收用户信息的方式的不同来分类的。在本文中,主要依据该系统中使用的数据库类型来进行分类:
1) 基于专家规则的智能客服系统
在一个特定的领域中,客服工作通常具有一定的可预知性,而一个该领域的资深专家更是非常了解客服工作中可能遇到的问题以及应对措施,由此,专家系统孕育而生,由该领域的专业人士书写客服问题以及答案的相关规则,精准的定位问题,并依据规则解决问题。此类智能客服系统需要人工不断更新规则,且对规则以外的问题无计可施。
2) 基于互联网信息的智能客服系统
互联网中存在着大量的知识,比如维基百科,百度百科等等,借助这些庞大的信息搜索引擎,在整个互联网范围内寻求答案,最大化的利用海量的信息资源。此外,网络用户群体会根据个人兴趣,依附于某个网络社区,并对该网络社区的主题领域是非常熟悉,包括雅虎,天涯论坛,知乎等等,用户群体具有一定的领域专业素养,能够利用他们的提出或回答的问题,来解决智能客服系统中的很多问题。
3) 基于领域知识库的智能客服系统
当一个领域所拥有的知识数据量达到一定程度时,可以根据历史数据构建该领域专业的知识库,即领域知识图谱。这能够最大化的精准利用该领域的专业知识,智能客服系统可以检索该知识图谱,获取问题答案集合,优选答案返回给用户,完成客服任务。该类智能客服系统的工作质量依赖于知识库的数据结构以及信息完备程度,但最大的优势在于不断的进行自我更新与学习。
这些系统都有着基本相同的特征:
1) 接收用户输入。智能客服系统可以通过各种渠道获取用户提出的问题,语音电话,网上即时聊天,留言等方式,并将用户问题的内容保存到计算机中,等待下一步的处理 [6]。
2) 语义理解与关键信息提取。这一步骤负责将前面记录得到的问题内容(一般是非结构化的自然语言),通过自认语言处理方法,进行语义理解,并提取出问题中的关键信息。
3) 检索相关数据库。通过前面提取到的关键信息,检索该领域的数据库,得到可选的答案集合 [7]。
4) 优选答案并回答用户。筛选前面得到的答案集合,经过对比与计算,优选出最终答案,最后将答案返回给用户,完成交互工作。
3. 智能客服系统架构
本文提出的基于知识图谱的智能语音客服系统主要包括如图1所示的几个部分。
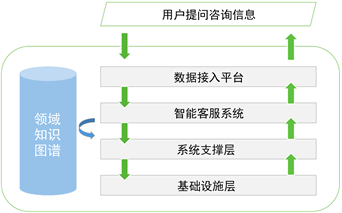
Figure 1. Intelligent customer service system architecture diagram
图1. 智能客服系统架构图
1) 数据接入平台
该部分的工作为接收用户的提问咨询信息,用户有多种方式提出问题咨询,在本文中语音方式是主要考虑的接入方式,这也是最贴切用户使用习惯的一种交流方式。但是对于计算机系统而言,语音是很抽象的一种数据形式,为了便于系统处理数据信息,我们需要将用户的语音信息转写为纯文本数据保存 [8]。
2) 智能客服系统
该部分是整个系统的核心,首先,我们需要对用户录入的纯文本文件进行中文分词,词性标注,关键信息提取等一系列自然语言处理操作,我们可以把这些工作统称为数据预处理过程;然后,该部分需要进一步检索领域知识谱图,对比得到的答案集合,优选出最佳的答案;最后,该部分还需要即时的更新领域知识图谱,使整个系统保持最佳的工作状态和最完整的知识储备量。
3) 系统支撑层
该部分主要负责用户权限管理,各项数据的统计记录,系统安全性检查等工作,为核心工作流提供各方面的支持与保障,是整个系统正常运行必不可少的一部分。
4)基础设施层
该部分主要是指系统运行 所需的各种软硬件基础设施,包括:语音的录制设备,系统服务器,支撑知识图谱的基础数据库等。
4. 系统模块功能说明
本文提出了一种基于知识图谱的智能语音客服系统设计方案,通过语音识别的方式,获取用户提出的问题内容,让后通过自然语言处理方法理解问题语义,并提取关键信息,再通过检索该领域的知识图谱,得到答案集合,经过消除歧义和优选得到最终答案。该系统可以分为如图2所示的几个模块。
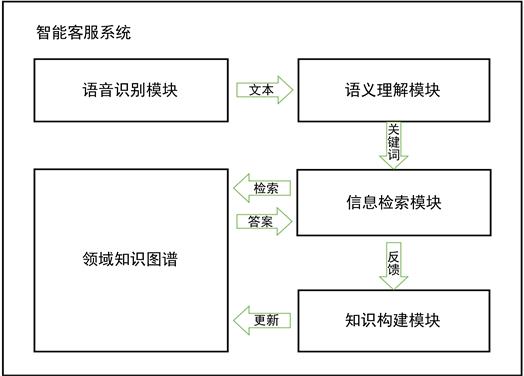
Figure 2. Intelligent customer service system module division
图2. 智能客服系统模块划分
4.1. 语音识别模块
1) 语音识别模块
该模块主要负责接收用户语音信息,将其转化为纯文本。语音识别是人工智能技术中重要的一个环节,人类的许多交互行为都是通过语音的方式进行的,所以,当计算机需要完成人机交互工作时,如何为语音识别建立模型就变得非常关键 [9],这将为信息数据的后续处理打下良好的工作基础。近年来,基于深度学习的语音识别建模变得非常流行 [10]。
科大讯飞平台专注语音识别,是一个非常开放的智能交互服务平台,它能在几乎任何场景下帮助你完成“读写听说”的任务。在本文中我们使用科大讯飞主要完成语音识别的功能,下面介绍讯飞平台有关语音识别的相关API调用说明。
语音转写即语音识别,将语音转写为文字,它是一种基于全序列卷积神经网络的一种方法:将一段较长的音频数据转换为文本数据,为后续的数据处理提供基础。语音识别(语音转写) API包括以下接口:预处理(/prepare:)、文件分片上传(/upload:)、合并文件(/merge:)、查询处理进度(/getProgress:)、获取结果(/getResult:)。图3为语音识别API调用的流程图:
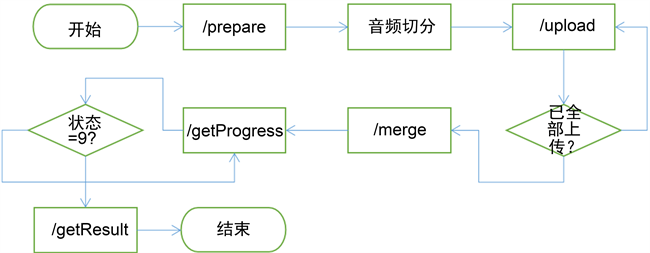
Figure 3. Voice Recognition API Call
图3. 语音识别API调用的流程图
4.2. 语义理解模块
该模块主要负责完成对用户提问的语义理解,借助多种自然语言处理技术,力图最完整,最精准的理解用户的问题。在本文提出的智能语音客服系统中,我们选取了优秀的中文分词方法,并提出state-BIL陈述域标记方法,domain-BILO领域标记方法,消除用户提问信息的模糊性,进一步明确用户提问信息中的关键信息,确定提问信息的领域范围。对问题文本做预处理,使之成为结构化数据。
1) ICTCLAS分词
该模块利用中文分词,关键词提取等技术,理解问题语义,对问题文本做预处理,使之成为结构化数据。中文分词的过程,就是将一段连续的中文纯文本,按照汉语词语和语句的构成规则,划分为符合中文构词逻辑的词语序列文本,本质上是纯文本的一种序列标记任务 [11]。中文不同于英文文本,在分词上具有得天独厚的优势,因为英语本身就含有词语间的分隔符号“空格”,所以,选择合适的中文分词方法至关重要。
现今有很多中文分词方法以及系统可供选择,其中有一些大家常用的方法,譬如:ICTCLAS分词,结巴分词,盘古分词等 [12]。本文采用的是来自中科院的ICTCLAS分词系统,它的优势在于:功能丰富,在应对中文分词,中文词性标注,中文命名实体识别,中文停用词识别以及中文关键词提取等任务上有着优秀的表现,准确率高达98%。并支持多种编码、多种操作系统、多种开发语言与平台。图4为ICTCLAS系统的组织结构图:
在进行中文分词的过程,我们得到的每一个独立词语必然有它自己的词性属性,词性标注也是分词任务当中重要的一部分,ICTCLAS系统也提供中文词性标注的功能。
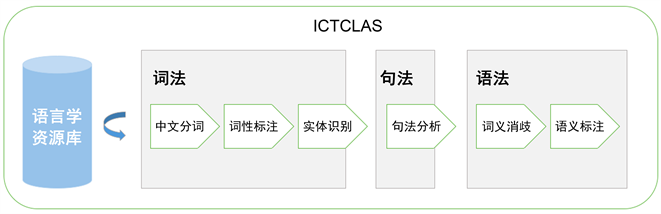
Figure 4. Organization chart of ICTCLAS system
图4. ICTCLAS系统的组织结构图
2) state-BIL陈述域标记
对于智能客服这个特有的领域,市民用户向客服询问的文本内容是有规律可循的,可以根据用户的问题陈述将其划分为问题陈述、建议、措施、投诉等确定的范围。为了进一步优化该智能客服系统的文本标注能力,本文提出一种文本陈述域的文本标注方法:state-BIL陈述域标记。只有在正确的划分用户文本信息的陈述域的前提下,才能对用户做出对应的回应。
在给文本中的词语在加上基本词性标签的同时,还可以加上陈述域标签,标签(state)即为文段中该词语所属的陈述域,标签(state-B)记为该陈述域的起始标记,标签(state-I)记为该陈述域的内部标记,标签(state-L)记为该陈述域的末尾标记。图5为state-BIL标记的举例说明:
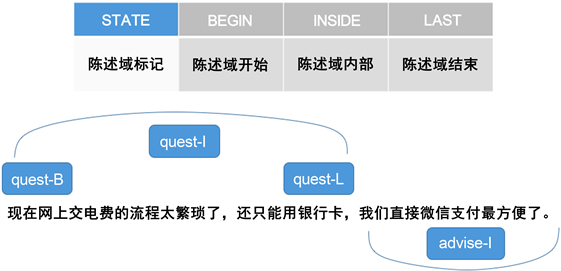
Figure 5. An example of state-BIL tag
图5. state-BIL标记的举例说明
3) domain-BILO领域标记
为了进一步优化该智能客服系统的文本标注能力,本文提出一种领域特征的文本标注方法:domain-BILO标记。在用户的一次提问信息中,有可能是单独针对某一个领域,也有可能是多个,只要是民生热点问题,都会有各自所在的领域,确定一段文字的领域信息就对智能客服系统非常有意义,可以更加精准的定位用户问题的方向。
在给文本中的词语在加上基本词性标签和陈述域的同时,还可以加上领域标签,标签(domain)即为文段中该词语所属的领域,标签(domain-B)记为该领域的起始标记,标签(domain-I)记为该领域的内部标记,标签(domain-L)记为该领域的末尾标记,标签(domain-O)记为该领域的外部标记。通过上述标签,即可为一个连续的文段加上领域信息,方便数据的后续处理,提高问题检索的效率以及精确程度。图6为domain-BILO标记的举例说明:

Figure 6. An example of domain-BILO tag
图6. domain-BILO标记的举例说明
4.3. 领域知识图谱模块
该模块主要负责保存领域专业知识,建立该领域的完整知识库。知识图谱KG (Knowledge Graph)本质为用实体节点和关系所组成的图,它能够为真实世界里的各种应用场景构建模型,知识图谱概念的概念早在2012年就已经确定,概念最早由谷歌提出 [13]。知识图谱的出现,表现了人工智能技术在发展过程中对于知识的需求,知识图谱可以广泛运用于各个方面,譬如:专家系统,语义网络,知识工程等。人们在构建知识图谱的过程,对于计算机而言,就是在利用知识,建立认知,理解世界,理解人类 [14]。图7为知识图谱可视化效果图:

Figure 7. Visual effect map of knowledge graph
图7. 知识图谱可视化效果图
在本文提出的系统中,我们利用知识图谱存储智能客服领域的各种专业知识,让计算机拥有客服人员所具备的专业素养,利用大量的历史客服数据,构建一个庞大的知识库,以应对用户提出的各种问题以及咨询。
1) 知识图谱的领域特征
传统的知识图谱是一种典型的纯文本三元组,图谱中的所有数据信息皆来自于每个节点的纯文本信息,这不利于存储知识的领域信息,特别是在面向市民热线的客服系统中,用户的提问与咨询可能来自多个不同的领域,为了更佳合理的存储知识数据的领域信息,本文提出了知识图谱中节点的领域特征表示方法:定义一个领域特征实值向量组,它的维度即为可能涉及的领域数量,每个向量值即为该知识数据与该领域的关联程度。这样不同的知识数据就可以在领域空间中得到定位,它们距离也就直观的展现了他们在领域中的关联程度。一个具体的领域组合也会在这个领域空间中得到定位,这将有效的避免对知识库的全图搜索,提高检索效率与精准度。图8为知识图谱的一个领域特征举例:

Figure 8. An example of domain features of knowledge graphs
图8. 知识图谱的领域特征举例
4.4. 信息检索模块
该模块主要负责检索知识库,获得答案集合,并通过算法优选出问题的最佳答案,完成最终的客服交互任务。领域专业知识库,它的表现形式是知识图谱,能够以非常直观的可视化界面展示知识数据信息,从底层基础结构来看,他的数据承载方式是数据库,如同其他数据库一样,在面对海量数据时,又快又准的检索数据,是该模块的主要内容。
1) 启发式规则检索
检索知识和检索数据有着很大的区别,知识的数据结构比较复杂,需要对检索出的数据进行优选,客服系统需要精准地回答问题,而不是做模糊查询。为了避免对庞大的领域知识库进行全图检索,本文提出了一系列启发式规则,用于指导智能客服系统进行合理高效的图搜索任务。
a) 问题答案的优选计数规则
随着智能客服系统的领域知识库数据量不断的扩大,在面对一个用户问题时,进行全面的图搜索,效率是非常低的,往往还会陷入局部最优点,偏离问题的最佳答案。但是经过数据分析可知,被越多次优选为最终答案的知识数据,往往是智能客服系统最需要的数据,也就是说,用户提出的问题或咨询信息具有相聚性,优选答案在知识图谱中也具有相聚性。因此,将知识库中的每条数据都进行优选计数,并以此作为答案最优检索的一个重要参数依据。
b) 问题答案的领域相似性规则
在问答系统中有一条重要的准则,问题所在的知识领域和答案所在的知识领域通常具有相当高的相似性。在智能客服系统中也是如此,可以计算每个候选答文本的领域信息与问题文本本身的领域信息的余弦相似度,并也以此作为答案最优检索的一个重要参数依据。
4.5. 知识构建模块
该模块主要负责通过外部数据构建领域知识图谱,或在每次系统与用户交互的过程中,记录产生的新知识,并更新知识图谱。智能客服系统也是需要不断学习新的知识,以便提高自身的业务能力。而学习的来源主要是通过用户的反馈信息,在用户与系统交互的过程中,可能会遇到系统未曾接触过的新知识,这是就需要该模块更新领域专业知识库。另外,用户也可能指出系统的错误,之前的某些知识数据可能就需要被清洗掉,以达到不断自我更新的状态。
1) KG定期更新策略
领域知识库需要定期更新知识数据,以最大化的适应现价段的客服需求,但是过于频繁的知识库更新,会严重影响系统的工作效率,因此,本文提出一种自适应的知识库定期更新策略:
定义系统进行启发式检索的耗时为T-query,系统容忍的最低响应时间为T-threshold,系统进行更新定期更新的判断窗口时间为T-window,系统在判断窗口内的检索计数为C-query,系统容忍的检索计数为C-threshold。由此,系统可以在每一次完成用户交互任务之后,记录本次任务的T-query,并在该判断窗口的时间内,加权平均所有的检索耗时,得到T-query在该T-window下的平均值,再与之前设定的系统响应阈值T-threshold做比较,一旦满足:avg(T-query) > T-threshold & C-query > C-thershold,即可在系统闲时进行知识库更新。图9为KG定期更新策略的图示说明:
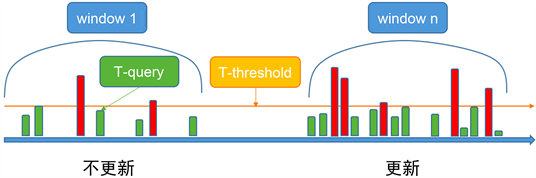
Figure 9. An example of regular updating strategy
图9. 定期更新策略的举例说明
2) 用户反馈策略
在智能客服系统的工作任务中,最能够判定工作质量的就是用户,因此,本文加入用户对客服系统的打分评价机制,以此来激励一次优秀的交互任务,与前面提到的诸多启发式规则一样,用户的反馈信息也是一个作为答案最优检索的一个重要参数依据。用户评价高的交互,该次交互所涉及的知识数据也会在领域知识库中有相应的优选回报。这也是知识库主动自我更新的一种策略。
5. 结束语
客服工作是当前企业运营中重要的一环,客服质量与效率将会直接影响到企业的发展,在本文提出的基于知识图谱的智能语音智能客服系统中,领域知识图谱的加入将有效地提高智能客服系统在该领域内的专业知识素养,领域特征实值向量组能够更加准确地刻画知识数据的领域特征;state-BIL陈述域标记、domain-BILO领域标记方法能够有效地定位为用户问题的领域信息,并给出更加对应的回应;一系列启发式检索规则能够避免效率低下的全图搜索,提高领域知识库的响应速度;KG定期更新策略能够选择更佳的知识库更新时机,用户评价机制更佳合理地运用用户的反馈信息完成知识库的更新;上述改进将使智能语音客服系统功能更加完善,以更高的效率完成客服工作。
致谢
本文的撰写要非常感谢我的研究生导师邱钊教授的悉心指导,感谢相关研发计划项目使我有幸参与到智能客服系统的研发工作,同时,本文的完成离不开胡建政师兄智能客服领域的论文支持。本文提出的系统架构以及模块的划分都是在师兄师姐,师弟师妹共同帮助下努力的结果,在此,感谢以上提到了每一个人为本文所做出的贡献。
基金项目
海南省重点研发计划项目“基于深度学习的智能客服系统研发(No. ZDYF2018017)”;国家自然科学基金项目“复杂物体表面纹理获取和三维重建的关键技术研究(No. 61573356)”;海南省自然科学基金项目“基于YOLOv2的监控视频人数统计研究(No. 618MS028)”。
文章引用
李 超,邱 钊,黄向生,胡建政,蔡金晔. 基于知识图谱的智能语音客服系统设计
Design of Intelligent Voice Customer Service System Based on Knowledge Graph[J]. 计算机科学与应用, 2020, 10(02): 255-264. https://doi.org/10.12677/CSA.2020.102027
参考文献
- 1. 侯佳腾, 常薇, 林冠峰. 基于自然语言理解技术的智能客服机器人的设计与实现[J]. 电子技术与软件工程, 2019(23): 238-240[2020-01-05].
- 2. 梁婧芸. 在线客服系统的微观建模与优化[J]. 工业工程与管理, 2018(3): 92-99.
- 3. 王海茹. 互联网企业客服外包风险分析与对策研究[D]: [硕士学位论文]. 武汉: 华中师范大学, 2019.
- 4. 黄翊. 基于智能语音分析的客服智慧运营管理系统解决方案[J]. 科技传播. 2018, 10(3).
- 5. 杨彭智. 基于移动端与大数据并行的现代企业客服系统浅谈[J]. 信息通信. 2017, 168(12): 68-71.
- 6. 蔡傲霄. 支持音视频的综合接入智能客服系统的设计与实现[D]: [硕士学位论文]. 北京: 北京邮电大学, 2019.
- 7. 杨海天, 王健, 林鸿飞. 一种基于主题类别信息问句检索的新方法[J]. 计算机应用与软件. 2015(2): 24-27.
- 8. 毛先领, 李晓明. 问答系统研究综述[J]. 计算机科学与探索. 2012, 6(3): 193-207.
- 9. 饶竹一, 张云翔. 智能语音识别技术在信息通信客服系统中的应用[J]. 通信电源技术. 2018, 81(6): 45-47.
- 10. 杨洋, 汪毓铎. 深度学习在语音识别声学建模中的应用[J]. 电脑知识与技术. 2018, 14(18): 196-198.
- 11. 张丹. 中文分词算法综述[J]. 黑龙江科技信息. 2012(8): 206.
- 12. 邹佳伦, 文汉云, 王同喜. 基于统计的中文分词算法研究[J]. 电脑知识与技术. 2019, 15(4): 155-156+159.
- 13. 王勇超, 罗胜文, 杨英宝, 张宏鑫. 知识图谱可视化综述[J]. 计算机辅助设计与图形学学报, 2019, 31(10): 1666-1676.
- 14. 符山, 吕艾临, 闫树. 知识图谱的概念与应用[J]. 信息通信技术与政策, 2019(5): 10-13.
NOTES
*通讯作者。