Operations Research and Fuzziology
Vol.
09
No.
01
(
2019
), Article ID:
28809
,
8
pages
10.12677/ORF.2019.91009
The Unknown Unequal Variance Model of Bivariate Meta-Analysis Based on the Difference Mean
Pengfei Guo1,2,3, Gang Li4*, Xiangru Sun5
1College of Computational Science, Zhongkai University of Agriculture and Engineering, Guangzhou Guangdong
2Intelligent Agriculture Engineering Research Center of Guangdong Higher Education Institute, Zhongkai University of Agriculture and Engineering, Guangzhou Guangdong
3Guangdong Province Key Laboratory of Waterfowl Healthy Breeding, Zhongkai University of Agriculture and Engineering, Guangzhou Guangdong
4Guangzhou E-Government Center, Guangzhou Guangdong
5Institute of Reproductive Medicine, Panyu Hexian Memorial Hospital of Guangzhou, Guangzhou Guangdong

Received: Jan. 15th, 2019; accepted: Feb. 5th, 2019; published: Feb. 12th, 2019

ABSTRACT
This paper introduces the unknown unequal variance model of bivariate meta-analysis based on the difference mean; we obtain the maximum likelihood estimator of the difference mean effect and unknown variances. Then we find the combining overall difference mean effect by the fixed-effect model of bivariate Meta-analysis based on the difference mean. Moreover, we obtain the corresponding covariance matrix and the confidence interval for the overall difference mean effect .
Keywords:Meta-Analysis, The Unknown Unequal Variance Model, Maximum Likelihood Estimate

基于均差估计二变量Meta-分析的未知不相等方差模型
郭鹏飞1,2,3,李刚4*,孙向茹5
1仲恺农业工程学院,计算科学学院,广东 广州
2仲恺农业工程学院,广东省高校智慧农业工程研究中心,广东 广州
3仲恺农业工程学院,广东省水禽健康养殖重点实验室,广东 广州
4广州市电子政务服务中心,广东 广州
5番禺何贤纪念医院,生殖医学科,广东 广州

收稿日期:2019年1月15日;录用日期:2019年2月5日;发布日期:2019年2月12日

摘 要
本文介绍基于均差估值的二变量Meta-分析的未知不相等方差模型,通过极大似然估计法给出效应量及方差估计,进而得到各研究均值效应量协方差矩阵的估计量。然后,通过基于均差效应量二变量Meta-分析的固定效应模型给出了合并均差统计量 的具体形式和权重。进而得到了 的协方差矩阵和两个变量的 置信区间。
关键词 :Meta-分析,未知不相等方差模型,极大似然估计

Copyright © 2019 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
Meta-分析回答了一个非常广为接受的问题和设计。即什么是研究的目标?在一个广泛的整体中研究的目标是否能够得到确认?什么是研究结果的可操作定义:试验样本组还是研究对象的总体?什么样类型的设计在搜索过程中是需要包括的?只有检验研究假设的随机试验可以作为纳入文献?非试验的研究是否可以作为纳入文献?上述这些问题的答案影响了一般综述的方法,统计推断的模式和研究结果的解释。
Meta-分析是一种对同一问题的不同研究进行定量合并的一种方法。针对具体问题的Meta-分析及其统计方法研究已持续了一个世纪之久。最早是在1904年Karl Pearson针对伤寒疫苗效果进行了合并研究 [1] ;但是在过去的四十年中,人们逐渐意识到医学实验和临床操作需要基于整体的相关性和可靠证据,Meta-分析的影响得到极大的扩展 [2] 。
尽管Meta-分析在很多领域都有较好的应用,但针对Meta-分析本身的统计方法研究与其应用研究相比较少。从应用的意义上来讲,Meta-分析是以估计量的标准误差为权重的点估计加权平均。通过选择 Meta-分析两个合理假设(该假设对于每一个研究作为独立先验信息存在)中的一个来合并公共定量信息估计,从而选择合并共同定量信息的估计模型:固定效应模型和随机效应模型。固定效应模型的Meta-分析依赖于假设各个研究具有相等效应量,具体是以估计量方差的逆作为权重给出的加权平均效应量 [3] 。
在具体应用中,建立统计模型解决上述挑战中的问题是非常重要的事情。例如:在临床医学中,目前对于流行病学的Meta-分析研究主要集中在单变量Meta-分析。由于流行病(例如:非霍其因淋巴瘤,乙/丙肝等)本身的致病原因很复杂、致病原因之间具有相关性,且前期检查也是多指标检验,因此单变量Meta-分析给出的效应量并不能完全地描述流行病的致病机理。由此,希望展开对流行病学的多变量Meta-分析研究。多变量Meta-分析有很多优点:第一,可以在一个模型框架下得到所有效应量的估计量;第二,可以通过所有效应量的估计量的协方差矩阵描述多效应量之间的关系。第三,我们可以获得具有更好统计特性的参数估计量;第四,可以获得区别于单变量Meta-分析的潜在机理原因;第五,多变量分析的方法可以在一定程度上降低纳入文献的偏倚性。
由于多变量Meta-分析的诸多优点,针对多变量Meta-分析的理论研究也在不断深入。1988年,Raudenbush SW等人为了研究教练在SAT中的作用,通过广义最小二乘法建立了多效应量合并的模型 [4] ;1993年,van Houwelingen HC等人在文献 [5] 中首次给出了基于比值比的二变量Meta-分析模型,讨论了该模型的异质性检验和敏感性分析;2002年,van Houwelingen HC等人通过似然估计方法建立了在广义多元混合线性模型的框架下的多元Meta-回归模型,并将此模型扩展到了非正态分布情形 [6] 。2008年,Riley RD等人在文献 [7] 中通过极大似然估计法给出了一些特殊相关系数情形下的二变量Meta-分析的协方差矩阵估计;2008年,Ritz J等人在协方差矩阵已知情形下,通过极大似然估计和估计方程给出了多元效应量回归参数,并将此模型应用到肺癌发病率的临床诊断中 [8] 。2010年,Paul M等人通过可积嵌套拉普拉斯近似贝叶斯方法给出了多变量Meta-分析的合并效应量估计,这种方法得到的方差估计偏移量更小且稳定 [9] 。
本文通过极大似然估计法给出效应量及方差估计且得到各研究均值效应量协方差矩阵的估计量;然后,通过基于均差效应量二变量Meta-分析的固定效应模型给出了合并均差统计量 的具体形式和权重。建立了基于均差估值的二变量Meta-分析的未知不相等方差模型并给出了 的协方差矩阵和两个变量的 置信区间。
2. 问题描述
在协方差矩阵的基于均差估值的二变量Meta-分析的未知不相等方差模型中,假设个体量 , , 和 是独立的并且是正态分布,其均值分别为 , , 和 。假设两个变量研究的方差分别为 , , , 。因此 , , 和 是独立的且服从正态分布,其均值分别为 , , 和 ,方差分别为 , , , 。假设两个变量之间的关系是相互独立的。
由上述假设,可以得到均差效应量 的分布为:
其中 为均值, 是非随机的。一般地, , 为未知参数。接下来通过极大似然估计法来估计 , , , 。假设操作组和对照组是相互独立的,记 ,其中 , 。
3. 均值效应量的极大似然估计
根据之前的假设效应量 服从正态分布且每个研究的操作组和对照组是独立的,因此关于 , , , , , 的似然函数为:
其中 , , , 。由操作组和对照组的独立性,可以分别计算其极大似然估计。操作组和对照组所对应的对数似然函数分别为:
因为操作组和对照组所对应的对数似然函数与基于均差估计二变量Meta-分析的未知相等方差模型中的似然函数相同,因此通过类似的计算可以给出参数 , , , , , 的极大似然估计量及其部分性质;
定理3.1:设效应量 服从 的正态分布,则
1) 的极大似然估计量的分量为:
2) , 的极大似然估计量分别为:
由上述知,效应量满足正态分布合并效应量均值估计量分量的具体形式,可以得到合并效应量均值估计量的如下性质:
性质3.1:设效应量 服从 的正态分布,那么 的极大似然估计量的分量为:
则 对于 是无偏的。
证明:要证明估计量的无偏性,需证等式 成立。根据我们给出的效应量 服从正态分布的合并效应量均值估计量分量的具体形式,我们需要证明 , 。因为 , , , ,所以
综上所述, 对于 是无偏的。
4. 均值效应量极大似然估计量的协方差矩阵
假设所以的研究都提供所有的均值效应。由多变量统计学的大数定理,合并效应量均值估计量可以近似为一个多元正态分布,其对应的协方差矩阵可由下面的定理给出:
定理4.1:设效应量 服从 的正态分布,那么 的合并均值效应量极大似然估计量为:
则 所对应的协方差矩阵 为:
通过合并均值效应量极大似然估计量 所对应的协方差矩阵 可以给出 的如下性质:
性质4.1:设效应量 服从 的正态分布, 的合并均值效应量极大似然估计量为:
则 对于 是一致的。
5. 整体均值合并统计量的估计
在上述研究中,效应量用的是均差。因此可以给出均值效应量 的协方差估计为: 。
在Meta-分析中,合并统计量是由具体研究表现统计量的加权平均给出的。根据均差估计二变量Meta-分析的固定效应模型可知,通过 可以给出每一个研究的权重及均差合并统计量。具体如下:
1) 对于均值合并统计量,每个研究均差的权重为:
注意到权重 只与个体研究的样本量有关并且是非随机的。
2) 整体均值合并统计量的估计量为:
通过 ,可以得到 的协方差阵的估计量为:
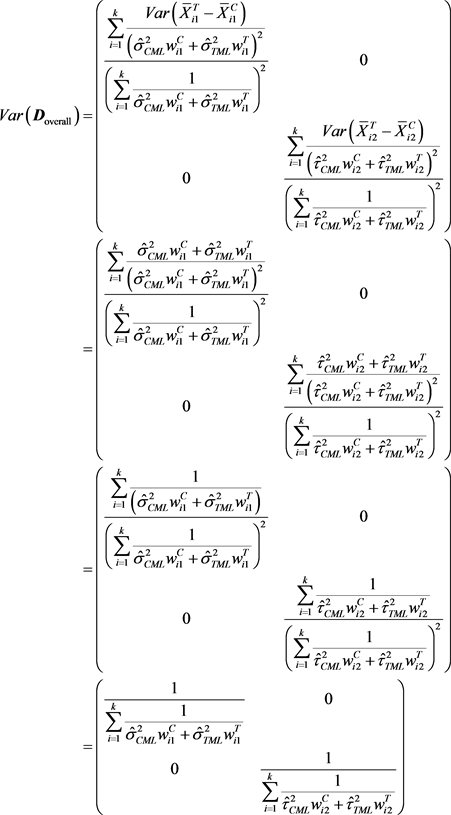
通过 所对应的协方差矩阵 可以给出单变量和联合变量的置信区域,其具体形式为:
性质5.1:设效应量 服从 的正态分布, 的合并均值效应量极大似然估计量为:
则合并均值效应量 所对应各个分量的 置信区间为: 和 ,其中 表示正态分布的 分位数, 表示矩阵 第i行第j列的分量。
6. 结束语
本文通过极大似然估计法给出效应量及方差估计,进而得到各研究均值效应量协方差矩阵的估计量。然后,由基于均差效应量二变量Meta-分析的固定效应模型给出了合并均差统计量 的具体形式和权重,构建了基于均差估值的二变量Meta-分析的未知不相等方差模型,进而得到了 的协方差矩阵和两个变量的 置信区间。本文的结果对流行病学的研究有着重要的统计学意义。
基金项目
本项目由如下基金支持:国家自然科学基金(61871475, 61471133, 61571444, 61473331),广东省科技计划(2017B010126001, 2017A070712019, 2016A040402043, 2015A070709015, 2015A020209171, 2016B010125004, 2014B040404070, 2015A040405014, 2016A070712020),广东省教育厅科技计划 (2017GCZX001, 2016GCZX001, 2017KTSCX094, 2017KTSCX095, 2017KQNCX098),广州市科技计划 (201707010221)。
文章引用
郭鹏飞,李刚,孙向茹. 基于均差估计二变量Meta-分析的未知不相等方差模型
The Unknown Unequal Variance Model of Bivariate Meta-Analysis Based on the Difference Mean[J]. 运筹与模糊学, 2019, 09(01): 72-79. https://doi.org/10.12677/ORF.2019.91009
参考文献
- 1. Pearson, K. (1904) Report on Certain Enteric Fever Inoculation Statistics. British Medical Journal, 3, 1243-1246.
- 2. Lee, W.L., Bausell, R.B. and Berman, B.M. (2001) The Growth of Health-Related Meta-Analyses Published from 1980 to 2000. Evaluation and the Health Professions, 24, 327-335. https://doi.org/10.1177/01632780122034948
- 3. Stijnen, T. (1999) Tutorial in Biostatistics. Meta-Analysis: Formulating, Evaluating, Combining, and Reporting by S-L. Normand. Statistics in Medicine, 18, 321-359.
- 4. Raudenbush, S.W., Becker, B.J. and Kalaian, H. (1988) Modeling Multivariate Effect Sizes. Psychological Bulletin, 103, 111-120. https://doi.org/10.1037/0033-2909.103.1.111
- 5. van Houwelingen, H.C., Zwinderman, K.H. and Stijnen, T. (1993) A Bivariate Approach to Meta-Analysis. Statistics in Medicine, 12, 2273-2284. https://doi.org/10.1002/sim.4780122405
- 6. van Houwelingen, H.C., Arends, L.R. and Stijnen, T. (2002) Advanced Methods in Meta-Analysis: Multivariate Approach and Metaregression. Statistics in Medicine, 21, 589-624. https://doi.org/10.1002/sim.1040
- 7. Riley, R.D., Abrams, K.R., Lambert, P.C., Sutton, A.J. and Thompson, J.R. (2007) Bivariate Random Effects Meta-Analysis and the Estimation of Between-Study Correlation. BMC Medical Research Methodology, 7, 3. https://doi.org/10.1186/1471-2288-7-3
- 8. Ritz, J., Demidenko, E. and Spiegelman, D. (2008) Multivariate Meta-Analysis for Data Consortia, Individual Patient Meta-Analysis, and Pooling Projects. Journal of Statistical Planning and Inference, 138, 1919-1933. https://doi.org/10.1016/j.jspi.2007.07.004
- 9. Paul, M., Riebler, A., Bachmann, L.M., Rue, H. and Held, L. (2010) Bayesian Bivariate Meta-Analysis of Diagnostic Test Studies Using Integrated Nested Laplace Approximations. Statistics in Medicine, 29, 1325-1339. https://doi.org/10.1002/sim.3858
NOTES
*通讯作者。