Artificial Intelligence and Robotics Research
Vol.
12
No.
02
(
2023
), Article ID:
66463
,
10
pages
10.12677/AIRR.2023.122013
基于语言知识的神经机器翻译研究进展
张津一*,郭聪,高忠辉
沈阳理工大学,信息科学与工程学院,辽宁 沈阳
收稿日期:2023年4月7日;录用日期:2023年5月23日;发布日期:2023年5月31日

摘要
在本论文中,我们全面回顾了基于语言知识的神经机器翻译(Neural Machine Translation, NMT)方法,重点关注了如何将语言学特征和知识融入NMT系统中。首先,我们介绍了神经机器翻译的基本概念和发展背景,然后详细讨论了基于语言知识的神经机器翻译数据增强方面、翻译模型结构改进与外部语言知识的融合方面的各种方法。最后,我们总结了基于语言知识的神经机器翻译在实践中的优势与挑战,并展望了未来的研究方向。
关键词
语言知识,神经机器翻译,数据增强,翻译模型改进,外部知识融入

Advancements in Neural Machine Translation Research Based on Language Knowledge
Jinyi Zhang*, Cong Guo, Zhonghui Gao
School of Information Science and Engineering, Shenyang Ligong University, Shenyang Liaoning
Received: Apr. 7th, 2023; accepted: May 23rd, 2023; published: May 31st, 2023

ABSTRACT
In this paper, we provide a comprehensive review of neural machine translation (Neural Machine Translation, NMT) methods based on language knowledge, with a focus on how to incorporate linguistic features and knowledge into NMT systems. First, we introduce the basic concepts and developmental background of neural machine translation. Then, we discuss in detail various approaches in the areas of data augmentation for NMT based on language knowledge, and improvements to translation model structures and the integration of external language knowledge. Finally, we summarize the advantages and challenges of NMT based on language knowledge in practice and look forward to future research directions.
Keywords:Language Knowledge, Neural Machine Translation, Data Augmentation, Translation Model Improvement, Integration of External Knowledge

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
神经机器翻译(Neural Machine Translation, NMT)是近年来自然语言处理领域的一大研究热点,NMT已经在很多语言对的翻译任务中取得了显著的性能提升。然而,NMT系统在很多方面仍然面临挑战,尤其是对于语言结构复杂或资源有限的语言对。为了克服这些挑战,许多研究人员开始探索如何将语言学特征和知识融入NMT系统中,从而提高翻译质量和泛化能力。
本文旨在对基于语言知识的神经机器翻译方法进行全面的回顾。在接下来的章节中,我们将首先介绍神经机器翻译的基本概念和发展背景(第2节)。接着,我们将详细讨论基于语言知识的神经机器翻译数据增强方面、翻译模型改进方面及融合外部语言知识方面的各种方法(第3节至第4节)。最后,我们将总结基于语言知识的神经机器翻译在实践中的优势与挑战,并展望未来的研究方向(第5节)。
2. 神经机器翻译的基本概念和发展背景
神经网络机器翻译(Neural Machine Translation, NMT)是近年来提出的一种基于序列到序列模型的翻译框架:利用大型神经网络将源语言序列翻译成目标语言序列 [1] [2] 。如图1所示,将X1~X4输入编码器(Encoder)中,然后经过注意力机制产生的上下文向量C1~C3的相关处理,最后从解码器(Decoder)来输出翻译结果Y1~Y3。经过多年的发展,NMT在各种语言对上产生了比以往任何框架都更好的翻译结果,成为一种具有巨大潜力的新型机器翻译模型。这种方法只需要双语对译平行语料,训练大规模翻译模型,这不仅具有很高的研究价值,同时也有很强的产业化前景,成为了当前机器翻译研究的前沿热点。
Google的团队在之后提出了完全基于注意力机制的Transformer结构 [3] 。该团队将Transformer概括为一句话:“Attention is All You Need. (注意力就是你需要的全部)”注意力机制可以解决长距离依赖问题,可以有更好的记忆力,能够记住更长距离的信息,另外最重要的就是注意力机制支持并行化计算。如图2所示,Transformer结构的输入是一句话的单词向量表示和其对应的位置编码信息,模型的核心层是一个多头注意力机制。多头注意力机制就是使用多个注意力机制进行单独计算,以获取更多层面的语义信息,然后将各个注意力机制获取的结果进行拼接组合,得到最终的结果。Transformer结构的神经网络机器翻译模型在多个语种的翻译实验上取得了比以往更好的翻译结果,现在已经成为了机器翻译任务的主流模型。Transformer已经逐步渗透到了各个领域。不仅在语言处理相关任务上大获全胜,也在计算机视觉的图像分类和目标检测等相关研究中取得了不错的效果,给予了计算机视觉领域新的想象空间。
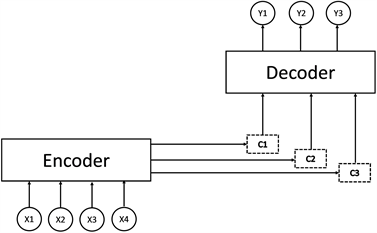
Figure 1. The basic framework of neural network machine translation
图1. 神经网络机器翻译的基本框架

Figure 2. The basic framework of transformer
图2. Transformer的基本框架
3. 基于语言知识的神经机器翻译数据增强
李洪政等人在2021年对稀缺资源语言神经网络机器翻译研究进行了综述,其中有大量数据增强研究 [4] 。在神经机器翻译的数据增强方向,对数据不仅要求“量”,还追求“质”的智能筛选已经被证明是一种成功的技术。Marlies等人探索了数据筛选在NMT上的效果,利用动态数据筛选方法有效提升了模型性能 [5] 。Zhang等人也对NMT的数据选择进行了研究并提出了在主动学习框架下选择知识信息量大的源句子来构建平行语料库,以尽可能降低人工翻译成本 [6] 。Wang等人则是针对特定领域的翻译进行了数据筛选的研究 [7] 。他们针对NMT提出了一种多域平衡方法,以平衡训练数据的域分布,此方法可以显著提高NMT的性能。宜年等人在数据筛选的基础之上用知识蒸馏的方法得到鲁棒性更强的汉维翻译模型 [8] 。刘欢等人提出了面向低资源俄汉机器翻译的领域适应方法,对俄汉语料进行了多种过滤筛选 [9] 。
单语语料是一种非常重要的资源,具有数量大、获取方便的优势,可以从单语语料中提取知识并增强语料数据。单语语料的主流利用方法是Sennrich等人提出的训练数据构造方法:回翻译(Back-Translation) [10] 。利用目标语言单语语料构造伪双语数据,并加入到训练语料。这种直接利用单语语料知识信息的融合方法不改变神经机器翻译模型,方法简单有效,大幅提高了翻译效果。在此基础上,Caswell等人提出一种更简单的在回翻译中添加噪声的方法 [11] 。Khatri等人在无监督NMT中使用了回翻译 [12] ,Wei等人提出了反向翻译迭代框架 [13] ,Abdulmumin等人提出了迭代式自训练方法来改进回翻译 [14] ,Hieu等人针对回翻译提出了一种专属的Meta学习框架 [15] ,都取得了不错的翻译结果。Jiao等人引入了真实数据作为指导,以防止NMT模型的训练受到嘈杂的合成数据的干扰 [16] 。Zhang等人提出了一种语料数据增强的方法,该方法有两种变化,一种是针对所有语言对,另一种是针对汉日语言对。该方法利用现有平行语料库的源句和目标句,对包含标点符号的长句对进行切割并通过回翻译生成多个伪句对。针对汉日语言对,使用了“共通汉字率”来修改句对的分段,有效提升了汉日长句分割的精度。提出的方法和过去的只使用回翻译的方法相比,取得了更显著的翻译效果 [17] 。
针对词汇替换的数据增强研究中,尤丛丛等人提出一种基于低频词的同义词替换的数据增强方法 [18] 。贾承勋等人对基于更大粒度的单词替换进行了研究,提出了一种基于短语替换的汉越伪平行句对生成方法 [19] 。Song等人通过目标语言的目标词语对相应的源语言进行了替换,增强数据进而提高翻译精度 [20] 。朱俊国等人提出了一种低频词表示增强的低资源神经机器翻译方法 [21] 。张一鸣等人提出一种融合数据增强技术和多样化解码策略方法来提高机器翻译性能 [22] 。
使用语言知识模型也可以进行数据增强。Zhao等人提出了一种从双语平行语料库中提取意译模式的支点方法,即用另一种语言的模式作为支点来提取当前语言的意译模式,这种模式在数据增强中可以得到应用 [23] 。Baziotis等人提出了一种新的方法,将从语料训练的语言模型作为先验知识信息融入神经网络翻译模型之中。在资源稀缺的机器翻译数据集上的结果有明显的改进 [24] 。朱志国等人提出了一种简单有效的Mask交互融合BERT预训练知识的低资源神经机器翻译方法 [25] 。王可超等人构建基于比例抽取的孪生网络筛选模型,通过训练使得模型可以识别平行句对和伪平行句对,在同一语义空间上对回译得到的伪平行语料进行筛选去噪,进而得到更优的汉越平行语料 [26] 。Ji等人基于噪声的预处理操作和面向对抗性训练的轻微修改可以帮助模型在低资源NMT任务中更好地提升BLEU (Bilingual Evaluation Understudy)分数和代词序列的准确性 [27] 。
综上,现在的数据增强研究主要集中在数据筛选、利用单语语料与低频词替换、使用语言模型知识等内容,还没有充分利用语言本身的知识。
4. 翻译模型结构改进与融合外部语言知识方面
Transformer结构的神经机器翻译模型已经在多个语种的翻译实验上取得了比以往更好的翻译结果,从而成为了当前机器翻译任务的主流模型。Song等人提出了一种针对俄语后缀翻译的NMT模型改进方法 [28] 。Xiao等人提出了基于双语文本填充任务的交互式机器翻译方法 [29] 。Zhang等人提出了一种频率感知token级对比学习方法,其中每个解码步骤的隐藏状态都以基于相应词频的软对比方式推理其他目标词的对应物,不仅可以显著提高翻译质量,还可以增强词汇多样性并优化单词表示空间 [30] 。Currey等人利用源训练句子的线性化解析方法在不修改Transformer架构的情况下将语法解析信息注入其中,在资源稀缺的语言对上有效果,但是在资源丰富的语言对上质量反而下降 [31] 。Li等人提出了提示驱动的神经机器翻译,以纳入提示知识来加强翻译控制和丰富灵活性,在提示反应和翻译质量方面都很有效 [32] 。
通过编码器、解码器融合更多语言信息是利用语言学知识的一种方式。最早是由Sennrich等人将编码器表示为特征组合,即将不同的特征向量拼接在一起 [33] 。该方法融合特征有词根特征、亚词标记特征、形态特征、词性标注和依存标记特征等。另外,Chen等人将源语言的依存特征也融合到神经机器翻译 [34] ;Qing-dao-er-ji等人研究了蒙汉双语语料库的预处理和蒙古语语素编码的LSTM模型的构建 [35] 。在汉日特征信息的融合方面,Zhang等人尝试在字级别的NMT上加入额外特征“部首”。因为汉语和日语中的汉字无法拆成Subword,所以基于字符级别选择了汉字的部首当作外部特征来融合到字向量中。翻译结果展示了把部首当作特征能有效提升翻译效能,甚至可以翻译出参考译文没有翻译成功的单词 [36] 。这类方法扩展了编码器和解码器的结构,并融合更多的语言学特征,同时也提高了源语言表示质量与目标语言生成质量。
句法树包含丰富的语言结构信息,Eriguchi等人提出了树到序列(Tree-to-Sequence)神经机器翻译模型,采用一个基于句法树的编码器,自底向上获得源语言句子的短语结构信息 [37] 。接下来Chen等人对Eriguchi等人提出的基于句法树的编码器进行了强化,提出了双向的句法树编码器,可以同时融合语言的序列表示和树状表示特征 [38] 。Gū等人提出了新型句法树结构模型,该模型将编码器与增强了感知能力的句法树结构相结合 [39] 。Pham等人揭示Transformer模型可以非常容易地掌握句法结构,但即使使用琐碎的“线性树”而不是真正的依赖关系,也可以获得相同的翻译效果 [40] 。Chang等人对神经机器翻译的编码器进行了研究,无论目标语言是什么,编码器都可以提取源语言的句法信息,在句法标签预测任务上优于RNN [41] 。Zhang等人将句法感知表征与普通的词向量连结起来,增强了神经机器翻译模型的表现 [42] 。Wang等人尝试将句法信息融入到Transformer中,用来赋予注意力更好的解释性。同时可以无监督的预测出句子的句法树,并且相比于一般的Transformer,语言模型的性能有所提高 [43] 。
除了上述句法知识,还有其他语言知识可以利用。Moussallem等人提出将语料的知识图谱融入神经机器翻译模型中的方法,可以增强模型的语义特征提取,从而优化文本中实体和术语表达的翻译,带来更好的翻译质量 [44] 。潘一荣等人提出了一种层次化融合词干、词性、词缀、词缀形态等维语语法特征的神经机器翻译模型 [45] 。Duan等人受查询双语词典学习翻译的能力的启发,提出了没有平行句子但可以参考真实的双语词典的建模方法,以了解机器翻译在使用双语词典和大规模单语语料库时能达到多大的潜力 [46] 。满志博等人提出一种基于多语言联合训练的汉英缅神经机器翻译方法,在Transformer框架下将丰富的汉英平行语料与较少的汉缅、英缅语料进行联合训练以利用汉英平行语料蕴含的知识信息 [47] 。Chen等人以一种与神经网络兼容的通用方式将先前的翻译知识整合到神经机器翻译中,从而充分利用先前的翻译知识来提高NMT的性能 [48] 。Lu等人提出一个多源NMT模型,在编码阶段进行语义信息交互,在训练阶段,引入了一个基于相互提炼的训练框架 [49] 。亢晓勉等人提出了一种篇章翻译模型,能够有效地建模和利用篇章单元间的依存结构信息,从而达到提升译文质量的目的 [50] 。Leong等人利用多语言Transformer翻译模型为平行语料库挖掘产生富有表现力的句子表示,可以增强低资源机器翻译 [51] 。
外部知识是事先准备的单语言、双语言、标注数据等等,不仅可以指导神经网络机器翻译的学习过程,还可以提供神经网络机器翻译的可解释性。在融合对齐信息方面,Li等人提出了两种独立于注意力机制的对齐信息获取方法。其中EAM模型(Explicit Alignment Model)需要一个权重矩阵W,并计算源单词对应到目标单词概率。由于W比较大,因此需要大量带标注的对齐数据,这些数据由fast_align自动生成。另一种方法称为预测差法(Prediction Difference),即将源句中单词的词向量替换为0向量,看预测的概率变化。最终证明了提高源句贡献大的单词的对齐成功率,有助于机器翻译质量的提升 [52] 。邹翔等人采用统计对齐的方法对汉越之间结构差异进行建模,提取汉语与越南语之间的语言差异化特征,以提升汉越译文质量估计的效果 [53] 。Song等人提出了一种融合对齐信息的NMT框架 [54] 。Wang等人研究了在平行语料库上的多语言句子转换方法并进行微调,得到了论文发表时最好的对齐效果以提升翻译效果 [55] 。
在融合语言本身知识方面,Zhang等人提出了对汉日两种语言中的汉字进行分解等预处理的方法,提升了汉日翻译的精度 [56] [57] 。Zhang等人还在汉日无监督神经网络机器翻译上也使用了汉字分解后的亚字符信息,提升了汉日无监督神经网络机器翻译的质量 [58] 。Du等人以拼音(Pinyin)为添加的输入特征,在以汉语为源语言的神经网络机器翻译中提高了翻译质量 [59] 。Tan等人和Zhang等人专注于使用五笔(Wubi)编码方案将汉字分解为类似于印欧语系的语言单位,实现了中文的亚字符级NMT系统 [60] [61] 。Halpern等人讨论了汉日翻译中的一些主要问题,例如专有名词和技术术语的翻译问题等等,提出了一个由数百万个命名实体组成的超大规模词汇资源,并认为通过整合词汇,可以显著提高NMT系统的翻译质量 [62] 。Saunders等人针对未知字的翻译问题,提出了一种对汉日两种语言中的汉字进行分解等预处理的新方法 [63] 。中澤敏明等人通过对日中共同汉字的整理与利用,提高了日汉机器翻译的质量 [64] 。卜朝晖的博士论文中研究了とりたて表现与否定表现为中心的日汉机器翻译 [65] 。罗雯涛提出了使用Subword,替换低频词,利用外部词典,采用领域自适应训练模型等多个针对日汉神经网络机器翻译的改进方案 [66] 。
5. 结语
根据本文的相关研究进展调查,可以得知基于语言知识的神经机器翻译具有以下优势:
1) 提高翻译质量:通过结合语言知识,例如语法、句法、语义和词汇等方面的知识,可以改善机器翻译的准确性和流畅性,从而提高翻译质量。
2) 鲁棒性更强:语言知识可以帮助机器翻译系统处理更复杂的句子结构和语言现象,从而提高系统的鲁棒性,使其更加适用于不同领域和语言对的翻译任务。
3) 可解释性更好:基于语言知识的神经机器翻译方法通常可以提供更好的可解释性,因为它们利用了人类对语言结构和规则的理解,这有助于更好地理解模型如何进行翻译。
随之而来的挑战有以下几点:
1) 数据稀缺性:基于语言知识的神经机器翻译方法通常需要更多的数据来训练,因为它们需要对语言结构和规则进行建模。在一些语言对中,特别是较为小众的语言对中,可能很难获取足够的高质量的训练数据,这会影响翻译系统的性能。
2) 语言多样性:不同语言之间存在巨大的差异,这些差异不仅体现在词汇、语法和语义方面,还包括文化、习惯和表达方式等方面。因此,基于语言知识的神经机器翻译方法需要考虑不同语言之间的多样性,以提高翻译的准确性和流畅性。
3) 模型复杂度:基于语言知识的神经机器翻译方法通常需要使用更复杂的模型,这会增加训练和推理的计算成本,使得模型更难以训练和调优。
那么,对于未来研究方向有以下几点展望:
1) 端到端的语言知识表示学习:如何将语言知识更好地集成到端到端的神经机器翻译系统中,以提高翻译质量和效率。
2) 多模态机器翻译:如何将不同模态的语言知识信息,例如文本、图像和语音等,结合起来进行翻译,以更好地满足实际应用需求。
3) 零样本机器翻译:如何在缺少某些语言对的训练数据时,利用已有的语言知识和语言模型进行零样本机器翻译,从而实现跨语言翻译的低成本化。
4) 解释性机器翻译:如何让机器翻译系统的翻译过程更加透明和可解释,使得用户可以更好地理解翻译的过程和结果,以便进行更好的交互和反馈。
从机器翻译领域的现状来看,基于语言知识的翻译模型、算法及实现技术已经在过去的十年中得到了快速发展,甚至有些观点认为基于语言知识的机器翻译已经“走到头”,一些研究者也转向了新一代框架的研究。但另一方面,基于语言知识的机器翻译仍然没有被系统实践者所广泛使用,而基于注意力机制的翻译模型在真实系统中仍一统天下。这里面体现了一种矛盾:研究者已经深入研究了传统的基于语言知识的机器翻译中的各种问题,但是这类框架还很难服务于真正可用的机器翻译系统。因此机器翻译领域仍期待着深层语言知识信息的引入。
基金项目
辽宁省教育厅高等学校基本科研项目(面上青年人才项目) (Grant No.LJKZ0267),沈阳理工大学引进高层次人才科研支持计划(Grant No.1010147001004),沈阳理工大学科研创新团队建设计划资助项目(Grant No.SYLUTD202105)。
文章引用
张津一,郭 聪,高忠辉. 基于语言知识的神经机器翻译研究进展
Advancements in Neural Machine Translation Research Based on Language Knowledge[J]. 人工智能与机器人研究, 2023, 12(02): 97-106. https://doi.org/10.12677/AIRR.2023.122013
参考文献
- 1. Zhang, J. and Matsumoto, T. (2019) Character Decomposition for Japanese-Chinese Character-Level Neural Machine Translation. Proceedings of the 2019 International Conference on Asian Language Processing (IALP), Shanghai, 15-17 November 2019, 35-40. https://doi.org/10.1109/IALP48816.2019.9037677
- 2. Bahdanau, D., Cho, K. and Bengio, Y. (2014) Neural Machine Translation by Jointly Learning to Align and Translate. https://arxiv.org/abs/1409.0473
- 3. Luong, M.T., Pham, H. and Manning, C.D. (2015) Effective Approaches to Attentionbased Neural Machine Translation. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, 17-21 September 2015, 1412-1421. https://doi.org/10.18653/v1/D15-1166
- 4. Zhang, L. and Komachi, M. (2019) Chinese-Japanese Unsupervised Neural Machine Translation Using Sub-character Level Information. The 33rd Pacific Asia Conference on Language, Information and Computation (PACLIC 33), Hakodate, 13-15 September 2019, 309-315.
- 5. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L. and Polosukhin, I. (2017) Attention Is All You Need. 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, 4-9 December 2017, 5998-6008.
- 6. Du, J. and Way, A. (2017) Pinyin as Subword Unit for Chinese-Sourced Neural Machine Translation. Proceedings of the 2017 International Conference on Artificial Intelligence and Computer Science, Las Vegas, 14-16 December 2017, 89-101.
- 7. 李洪政, 冯冲, 黄河燕. 稀缺资源语言神经网络机器翻译研究综述[J]. 自动化学报, 2021, 47(6): 1217-1231.
- 8. Tan, M., Hu, Y., Nikolov, N.I. and Hahnloser, R. (2018) Wubi2en: Character-Level Chinese-English Translation through ASCII Encoding. Proceedings of the Third Conference on Machine Translation: Research Papers, Brussels, 31 October-1 November 2018, 10-16.
- 9. Marlies, W., Bisazza, A. and Monz, C. (2017) Dynamic Data Selection for Neural Machine Translation. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP), Copenhagen, 7-11 September 2017, 1400-1410.
- 10. Zhang, W., Lin, F., Wang, X., Liang, Z. and Huang, Z. (2019) SubCharacter Chinese-English Neural Machine Translation with Wubi Encoding. https://arxiv.org/abs/1911.02737
- 11. Zhang, P., Xu, X. and Xiong, D. (2018) Active Learning for Neural Machine Translation. 2018 International Conference on Asian Language Processing, Bandung, 15-17 November 2018, 153-158. https://doi.org/10.1109/IALP.2018.8629116
- 12. Halpern, J. (2018) Very Large-Scale Lexical Resources to Enhance Chinese and Japanese Machine Translation. Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, 7-12 May 2018, 857-861.
- 13. Wang, R., Utiyama, M., Finch, A.M., Liu, L., Chen, K. and Sumita, E. (2018) Sentence Selection and Weighting for Neural Machine Translation Domain Adaptation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26, 1727-1741. https://doi.org/10.1109/TASLP.2018.2837223
- 14. Saunders, D., Feely, W. and Byrne, B. (2020) Inference-Only Sub-Character Decomposition Improves Translation of Unseen Logographic Characters. Proceedings of the 7th Workshop on Asian Translation, Suzhou, December 2020, 170-177.
- 15. 宜年, 艾山∙吾买尔, 买合木提∙买买提, 等. 基于多种数据筛选的维汉神经机器翻译[J]. 厦门大学学报(自然科学版), 2022, 61(4): 660-666.
- 16. 中澤敏明, Chu, C., 黒橋禎夫. 日中共通漢字の整理とこれを利用した日中機械翻訳の高度化[EB/OL]. Japio Year Book, 258-261. https://cir.nii.ac.jp/crid/1523669555917032960, 2023-05-30.
- 17. ト朝暉. 日中機械翻訳に関する研究~とりたて表現, 否定表現の翻訳規則を中心に~[D]: [博士学位论文]. 岐阜: 岐阜大学, 2004.
- 18. 刘欢, 刘俊鹏, 黄锴宇, 等. 面向低资源俄汉机器翻译的领域适应方法[J]. 厦门大学学报(自然科学版), 2022, 61(4): 654-659.
- 19. Sennrich, R., Haddow, B. and Birch, A. (2016) Improving Neural Machine Translation Models with Monolingual Data. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, 7-12 August 2016, 86-96. https://doi.org/10.18653/v1/P16-1009
- 20. Caswell, I., Chelba, C. and Grangier, D. (2019) Tagged Back-Translation. Proceedings of the 4th Conference on Machine Translation, Florence, 1-2 August 2019, 53-63. https://doi.org/10.18653/v1/W19-5206
- 21. Khatri, J. and Bhattacharyya, P. (2020) Filtering Back-Translated Data in Unsupervised Neural Machine Translation. Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, 8-13 December 2020, 4334-4339. https://doi.org/10.18653/v1/2020.coling-main.383
- 22. Wei, H., Zhang, Z., Chen, B. and Luo, W. (2020) Iterative Domain-Repaired Back-Translation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16-20 November 2020, 5884-5893. https://doi.org/10.18653/v1/2020.emnlp-main.474
- 23. Abdulmumin, I., Galadanci, B.S. and Sinan, I.I. (2020) Iterative Self-Learning for Enhanced Back-Translation in Low Resource Neural Machine Translation. Proceedings of the 7th Workshop on Asian Translation, Suzhou, December 2020, 170-178.
- 24. Pham, H., Wang, X., Yang, Y. and Neubig, G. (2021) Meta Back-Translation. arXiv: 2102.07847.
- 25. Jiao, R., Yang, Z., Sun, M. and Liu, Y. (2021) Alternated Training with Synthetic and Authentic Data for Neural Machine Translation. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1-6 August 2021, 1828-1834. https://doi.org/10.18653/v1/2021.findings-acl.160
- 26. Zhang, J. and Matsumoto, T. (2019) Corpus Augmentation for Neural Machine Translation with Chinese-Japanese Parallel Corpora. Applied Sciences, 9, Article 2036. https://doi.org/10.3390/app9102036
- 27. 尤丛丛, 高盛祥, 余正涛, 等. 基于同义词数据增强的汉越神经机器翻译方法[J]. 计算机工程与科学, 2021, 43(8): 1497-1502.
- 28. 贾承勋, 赖华, 余正涛, 等. 基于短语替换的汉越伪平行句对生成[J]. 中文信息学报, 2021, 35(8): 47-55.
- 29. Song, K., Zhang, Y., Yu, H., Luo, W., Wang, K. and Zhang, M. (2019) Code-Switching for Enhancing NMT with Pre-Specified Translation. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, 2-7 June 2019, 449-459.
- 30. 朱俊国, 杨福岸, 余正涛, 等. 低频词表示增强的低资源神经机器翻译[J]. 中文信息学报, 2022, 36(6): 44-51.
- 31. 张一鸣, 刘俊鹏, 宋鼎新, 等. 融合数据增强与多样化解码的神经机器翻译[J]. 厦门大学学报(自然科学版), 2021, 60(4): 670-674.
- 32. Zhao, S., Wang, H., Liu, T. and Li, S. (2009) Extracting Paraphrase Patterns from Bilingual Parallel Corpora. Natural Language Engineering, 15, 503-526. https://doi.org/10.1017/S1351324909990155
- 33. Baziotis, C., Haddow, B. and Birch, A. (2020) Language Model Prior for Low-Resource Neural Machine Translation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16-20 November 2020, 7622-7634. https://doi.org/10.18653/v1/2020.emnlp-main.615
- 34. 朱志国, 郭军军, 余正涛. 一种Mask交互融合预训练知识的低资源神经机器翻译方法[J/OL]. 小型微型计算机系统: 1-8. http://kns.cnki.net/kcms/detail/21.1106.tp.20221123.1125.022.html
- 35. 王可超, 郭军军, 张亚飞, 高盛祥, 余正涛. 基于回译和比例抽取孪生网络筛选的汉越平行语料扩充方法[J]. 计算机工程与科学, 2022, 44(10): 1861-1868.
- 36. Ji, Y., Shi, L., Su, Y.L., Ren, Q., Wu, N. and Wang, H. (2021) A Strategy for Referential Problem in Low-Resource Neural Machine Translation. In: Farkaš, I., Masulli, P., Otte, S. and Wermter, S., Eds., Artificial Neural Networks and Machine Learning—ICANN 2021, Springer, Cham, 321-332. https://doi.org/10.1007/978-3-030-86383-8_26
- 37. Song, K., Zhang, Y., Zhang, M. and Luo, W. (2018) Improved English to Russian Translation by Neural Suffix Prediction. Thirty-Second AAAI Conference on Artificial Intelligence, Riverside, 2-7 February 2018, 410-417.
- 38. Xiao, Y.L., Liu, L.M., Huang, G.P., Qu, C., Huang, S.J., Shi, S.M. and Chen, J.J. (2022) BiTIIMT: A Bilingual Text-Infilling Method for Interactive Machine Translation. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, 22-27 May 2022, 1958-1969. https://doi.org/10.18653/v1/2022.acl-long.138
- 39. Zhang, T., Ye, W., Yang, B.S., Zhang, L., Ren, X.Z., Liu, D., Sun, J., Zhang, S.K., Zhang, H.B. and Zhao, W. (2022) Frequency-Aware Contrastive Learning for Neural Machine Translation. Proceedings of the AAAI Conference on Artificial Intelligence, 36, 11712-11720. https://doi.org/10.1609/aaai.v36i10.21426
- 40. Currey, A. and Heafield, K. (2019) Incorporating Source Syntax into Transformer-Based Neural Machine Translation. Proceedings of the 4th Conference on Machine Translation, Florence, 1-2 August 2019, 24-33. https://doi.org/10.18653/v1/W19-5203
- 41. Li, Y., Yin, Y., Li, J. and Zhang, Y. (2022) Prompt-Driven Neural Machine Translation. Findings of the Association for Computational Linguistics: ACL 2022, Dublin, 22-27 May 2022, 2579-2590. https://doi.org/10.18653/v1/2022.findings-acl.203
- 42. Sennrich, R. and Haddow, B. (2016) Linguistic Input Features Improve Neural Machine Translation. Proceedings of the First Conference on Machine Translation, Berlin, 11-12 August 2016, 83-91. https://doi.org/10.18653/v1/W16-2209
- 43. Chen, K., Wang, R. and Utiyama, M. (2017) Neural Machine Translation with Source Dependency Representation. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, 7-11 September 2017, 2836-3842. https://doi.org/10.18653/v1/D17-1304
- 44. Qing-dao-er-ji, R., Su, Y.L. and Liu, W.W. (2020) Research on the LSTM Mongolian and Chinese Machine Translation Based on Morpheme Encoding. Neural Computing and Applications, 32, 41-49. https://doi.org/10.1007/s00521-018-3741-5
- 45. Zhang, J. and Matsumoto, T. (2017) Improving Character Level Japanese-Chinese Neural Machine Translation with Radicals as an Additional Input Feature. Proceedings of the 2017 International Conference on Asian Language Processing, Singapore, 5-7 December 2017, 172-175. https://doi.org/10.1109/IALP.2017.8300572
- 46. Eriguchi, A., Hashimoto, K. and Tsuruoka, Y. (2016) Tree-to-Sequence Attentional Neural Machine Translation. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, 7-12 August 2016, 823-833. https://doi.org/10.18653/v1/P16-1078
- 47. Chen, H., Huang, S., Chiang, D. and Chen, J. (2017) Improved Neural Machine Translation with a Syntax-Aware Encoder and Decoder. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, 30 July-4 August 2017, 1936-1945. https://doi.org/10.18653/v1/P17-1177
- 48. Gū, J., Shavarani, H. and Sarkar, A. (2018) Top-Down Tree Structured Decoding with Syntactic Connections for Neural Machine Translation and Parsing. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, 31 October-4 November 2018, 401-413. https://doi.org/10.18653/v1/D18-1037
- 49. Pham, T., Macháček, D. and Bojar, O. (2019) Promoting the Knowledge of Source Syntax in Transformer NMT Is Not Needed. Computación y Sistemas, 3, 923-934. https://doi.org/10.13053/cys-23-3-3265
- 50. Chang, T. and Rafferty, A.N. (2020) Encodings of Source Syntax: Similarities in NMT Representations across Target Languages. Proceedings of the 5th Workshop on Representation Learning for NLP, Online, 9 July 2020, 7-16. https://doi.org/10.18653/v1/2020.repl4nlp-1.2
- 51. Zhang, M., Li, Z., Fu, G. and Zhang, M. (2019) Syntax-Enhanced Neural Machine Translation with Syntax-Aware Word Representations. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, 2-7 June 2019, 1151-1161. https://doi.org/10.18653/v1/N19-1118
- 52. Wang, Y., Lee, H. and Chen, Y. (2019) Tree Transformer: Integrating Tree Structures into Self-Attention. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, 3-7 November 2019, 1061-1070. https://doi.org/10.18653/v1/D19-1098
- 53. Moussallem, D., Arcan, M., Ngomo, A.N. and Buitelaar, P. (2019) Augmenting Neural Machine Translation with Knowledge Graphs. https://arxiv.org/abs/1902.08816
- 54. 潘一荣, 李晓, 杨雅婷, 等. 面向维汉机器翻译的层次化多特征融合模型[J]. 厦门大学学报(自然科学版), 2020, 59(2): 206-212.
- 55. Duan, X., Ji, B., Jia, H., Tan, M., Zhang, M., Chen, B., Luo, W. and Zhang, Y. (2020) Bilingual Dictionary Based Neural Machine Translation without Using Parallel Sentences. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5-10 July 2020, 1570-1579. https://doi.org/10.18653/v1/2020.acl-main.143
- 56. 满志博, 毛存礼, 余正涛, 李训宇, 高盛祥, 朱俊国. 基于多语言联合训练的汉-英-缅神经机器翻译方法[J]. 清华大学学报(自然科学版), 2021, 61(9): 927-935.
- 57. Chen, K., Wang, R., Utiyama, M. and Sumita, E. (2022) Integrating Prior Translation Knowledge into Neural Machine Translation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30, 330-339. https://doi.org/10.1109/TASLP.2021.3138714
- 58. Lu, Z., Li, X., Liu, Y., Zhou, C., Cui, J., Wang, B., Zhang, M. and Su, J. (2022) Exploring Multi-Stage Information Interactions for Multi-Source Neural Machine Translation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30, 562-570. https://doi.org/10.1109/TASLP.2021.3120592
- 59. 亢晓勉, 宗成庆. 基于篇章结构多任务学习的神经机器翻译[J]. 软件学报, 2022, 33(10): 3806-3818.
- 60. Leong, C.K., Liu, X., Wong, D.F. and Chao, L.S. (2021) Exploiting Translation Model for Parallel Corpus Mining. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 2829-2839. https://doi.org/10.1109/TASLP.2021.3105798
- 61. Li, X., Li, G., Liu, L., Meng, M. and Shi, S. (2019) On the Word Alignment from Neural Machine Translation. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, 28 July-2 August 2019, 1293-1303. https://doi.org/10.18653/v1/P19-1124
- 62. 邹翔, 朱俊国, 高盛祥, 余正涛, 杨福岸. 融入语言差异化特征的汉越神经机器翻译译文质量估计[J]. 小型微型计算机系统, 2022, 43(7): 1413-1418.
- 63. Song, K., Wang, K., Yu, H., Zhang, Y., Huang, Z., Luo, W., Duan, X. and Zhang, M. (2020) Alignment-Enhanced Transformer for Constraining NMT with Pre-Specified Translations. Proceedings of the AAAI Conference on Artificial Intelligence, 34, 8886-8893. https://doi.org/10.1609/aaai.v34i05.6418
- 64. Wang, W., Chen, G., Wang, H., Han, Y. and Chen, Y. (2022) Multilingual Sentence Transformer as a Multilingual Word Aligner. Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, December 2022, 2952-2963.
- 65. 罗雯涛. 关于日中神经网络机器翻译中的词汇问题的探讨[J]. 计算机科学与应用, 2020(3): 387-397.
- 66. Zhang, L. and Komachi, M. (2018) Neural Machine Translation of Logographic Languages Using Sub-character Level Information. Proceedings of the Third Conference on Machine Translation: Research Papers, Brussels, 31 October-1 Novermber 2018, 17-25. https://doi.org/10.18653/v1/W18-6303
NOTES
*通讯作者。