Operations Research and Fuzziology
Vol.
13
No.
02
(
2023
), Article ID:
64759
,
19
pages
10.12677/ORF.2023.132132
基于各模型对重庆GDP实证分析
叶茂越
贵州大学数学与统计学院,贵州 贵阳
收稿日期:2023年3月17日;录用日期:2023年4月21日;发布日期:2023年4月28日
摘要
分析1979年至2021年的重庆GDP数据的时间序列,建立了自回归滑动平均求和模型ARIMA(p,d,q),并用该模型预测的2020年和2021年重庆GDP数据与实际数据进行比较,对建立的模型进行优化评估,最后利用优化模型对2022年和2023年重庆GDP进行短期预测,为重庆经济的发展提供参考。根据建立的时间序列分析得到最优模型为ARIMA(0,2,2),预测值与实际值的平均绝对误差为1.22%,能较好地反映重庆GDP发展的趋势并进行短期预测。此外还对语言自动识别的ARIMA(0,2,1)模型进行分析,并基于BP神经网络、CNN、LSTM模型等对重庆GDP进行预测。在2020年中,基于ARIMA(0,2,2)模型预测结果的相对误差的绝对值最小。在2021年中,基于单变量MLP模型预测结果的相对误差的绝对值最小,在平均绝对误差水平中,ARIMA(0,2,2)模型的平均绝对误差水平最小。综合可以看出ARIMA(0,2,2)模型的预测效果是最好的。
关键词
时间序列,ARIMA模型,GDP,BP神经网络,CNN,LSTM模型

Empirical Analysis of Chongqing GDP Based on Various Models
Maoyue Ye
School of Mathematics and Statistics, Guizhou University, Guiyang Guizhou
Received: Mar. 17th, 2023; accepted: Apr. 21st, 2023; published: Apr. 28th, 2023

ABSTRACT
This paper analyzes the time series of Chongqing’s GDP data from 1979 to 2021, establishes an autoregressive moving average summation model ARIMA(p,d,q), compares the GDP data predicted by this model in 2020 and 2021 with the actual data, optimizes and evaluates the established model, and finally uses the optimized model to make a short-term prediction of Chongqing’s GDP in 2022 and 2023, providing reference for Chongqing’s economic development. According to the established time series analysis, the optimal model is ARIMA(0,2,2), and the average absolute error between the predicted value and the actual value is 1.22%, which can better reflect the development trend of Chongqing’s GDP and make short-term prediction. In addition, the ARIMA(0,2,1) model of automatic language recognition is analyzed, and the GDP of Chongqing is predicted based on BP neural network, CNN and LSTM model. In 2020, the absolute value of the relative error of the results predicted based on ARIMA(0,2,2) model is the smallest. In 2021, the absolute value of the relative error of the results based on the univariate MLP model is the smallest, and the average absolute error level of ARIMA(0,2,2) model is the smallest. It can be seen that ARIMA(0,2,2e) modl has the best prediction effect.
Keywords:Time Series, ARIMA Models, GDP, BP Neural Networks, CNN, LSTM Models

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
GDP (Gross Domestic Product)是国民经济核算过程中的重要指标之一,能够反映一国或一个地区的国民经济生产规模及综合实力,而研究GDP的数值对预测经济的发展起到了极大的参考作用。如果能正确地预测出GDP的发展,那么就可以依据预测的结果,为国家或地区在制定经济政策方面上提供依据和参考作用。
Gwilym和George [1] [2] [3] [4] [5] 主要介绍ARIMA模型建立的详细过程,分别为模型的识别、估计、检验和预测四个过程。赵子萌 [6] 在分析并确定了ARIMA(2,3,0)模型可较准确预测成都市GDP;李辰飞等 [7] 采用ARIMA模型预测分析湖北省GDP,最终确定了ARIMA(0,1,1)模型对GDP数据的拟合效果更好。华鹏等 [8] 建立ARIMA模型分析广东省GDP的发展状况,确定ARIMA(1,1,0)模型对GDP数据进行拟合,并用该模型预测了广东省2005年至2008年的GDP,得出用ARIMA模型来短期预测GDP效果更好的结论。张文韬等 [9] 对河南省GDP的数据进行了分析,证明了ARIMA(0,1,4)模型可预测河南省GDP,但是该模型只适合在短期内预测河南省GDP趋势。瞿海情等 [10] 对湖北省GDP的预测模型ARIMA(0,2,3),ARIMA模型能较好地反映湖北省GDP发展的趋势并进行短期预测。
重庆是一个比较发达的直辖市 [11] ,最近几年来,重庆的经济呈现快速增长的趋势,但是这个趋势能保持多久却是我们需要仔细考虑的问题。所以本文就对重庆的GDP数据进行分析研究,而研究GDP具有一定的现实和指导意义。本文选择时间序列分析的方法对重庆GDP进行预测,时间序列预测是通过处理自身时间序列的数据来研究其变化趋势的,也就是通过分析过去和现在的数据来预测未来的数据,而分析处理数据的过程就是建立模型的过程,然后再依据建立的模型来预测出未来数据的变化。此外通过BP神经网络、CNN、LSTM等模型对重庆GDP时间序列数据进行了相关分析与对比。
2. ARIMA模型简介
美国统计学家G. E. P. Box和G. M. Jenkins于1970年首次提出ARIMA模型。该模型在ARMA模型的基础上进差分运算,并用数学模型描述预测对象随时间推移而形成的数据序列,模型被识别后可以从时间序列的过去值及现在值来预测未来值。最基本的模型是自回归滑动平均求和模型ARIMA(p,d,q),其中q移动平均项数,d为时间序列成为平稳时所做的差分次数,p为自回归项。
该模型的基本思想是:将预测变量随时间变化而形成的序列作为随机序列,其后以时间序列的自相关性为基础,用特定的数学模型来描述该随机序列。当 时,就是滑动平均模型MA(q),当 时,就是自回归模型AR(p),当只有 时,模型就变成了自回归滑动平均混合模型ARMA(p,q),所以后三种模型是ARIMA模型的特殊形式。
2.1. ARMA模型
ARMA(p,q)模型是自回归模型AR(p)和滑动平均模型MA(q)的混合形式,所以它又称为自回归滑动平均混合模型,方程形式为:
(1)
其中,c是常数,是 自回归模型AR的系数,p是AR的阶数, 是滑动平均模型MA的系数,q是MA的阶数, 是均值为0方差为 的白噪声序列。
2.2. ARIMA模型
ARMA(p,q)模型只能在的平稳时间序列中应用,对于非平稳的序列,ARMA模型却不再适用,这时就需要引入一个新的模型,即ARIMA模型,ARIMA模型主要解决非平稳的时间序列问题。
是一个不平稳的时间序列,在d次差分运算后,序列逐渐趋于平稳,就称 是自回归滑动平均求和混合模型。如果差分后的序列 满足ARMA(p,q)模型,就称是ARIMA(p,d,q)过程,模型的方程是:令,有 :
(2)
用序列符号 来表示:
(3)
通过化简可以得到:
(4)
称其为模型的差分方程形式。值得注意的是,该表达式看起来是一个ARMA(p + 1,q)过程。
3. ARIMA模型的建立与预测
3.1. 模型识别
时间序列的平稳化处理:数据的平稳性检验主要包括平稳性检验和白噪声检验两个方面。适用于ARIMA模型分析预测的时间序列必须是平稳非白噪声序列。非平稳的时间序列则需要进行差分处理,直至检验平稳为止。其中,差分的次数就是模型ARIMA(p,d,q)的阶数。一般来说,差分阶数不超过2。
ARMA(p,q)拟合:对于平稳的时间序列而言,可画出序列的自相关图(ACF)和偏自相关图(PACF)进行观察分析,初步判断模型的值,值的选择标准见表1所示。选择的不同ARIMA模型也不同,此时则是根据AIC或BIC准则来评价模型的好坏,当AIC或BIC最小时,ARIMA模型拟合的最好。

Table 1. Selection principle of ARMA model
表1. ARMA模型的选择原则
3.2. 模型估计
通常采用极大似然估计法来估计ARIMA(p,q)模型中的未知参数。
3.3. 模型检验
模型检验主要是检验模型对时间序列拟合的好坏,如果拟合的效果很差,就需要重新选择新的模型,直到拟合效果达到最好。模型检验既要对参数的估计值进行检验,又要对残差序列进行检验,如果检验的参数估计值是显著的并且残差序列是白噪声序列,则模型通过检验,说明模型的拟合效果很好,如若不是,则需要重新选择模型使其通过检验。通常采用Ljung-Box统计量检验的方法来判断残差序列是否为白噪声。
3.4. 模型预测
根据模型检验和比较的最后结果,利用所构建的ARIMA(p,d,q)模型,用R软件中的预测功能对模型进行预测,得到原始时间序列图的将来变化趋势,对比预测的数值和实际的数值进行误差分析,进一步验证模型是可行的。具体的ARIMA(p,d,q)建模流程图见图1所示。

Figure 1. ARIMA modeling flow chart
图1. ARIMA建模流程图
4. ARIMA模型对重庆GDP的预测及实证分析
本文对重庆1979年至2021年的42个GDP数据进行了分析,为了检验模型的说服力以及正确性,现在选取前面40个GDP数据用来建模,并用后面2年的数据来检验模型的拟合效果,最后再来预测2022年和2023年的GDP。
4.1. 数据平稳性检验与处理
本文从《中国知网》中搜集到重庆1979年至今的国内生产总值,数据见表2所示。根据1979~2019年的重庆GDP数据,画出时间序列图,见图2所示。
Table 2. GDP data of Chongqing from 1979 to 2019
表2. 1979~2019年的重庆GDP数据
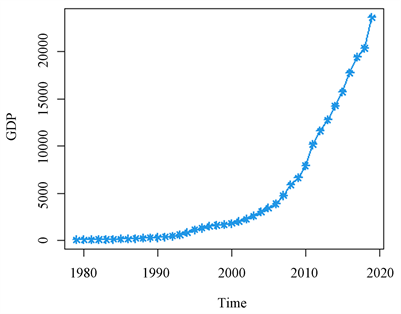
Figure 2. Time series chart of Chongqing’s GDP from 1979 to 2019
图2. 1979~2019年重庆GDP的时间序列图
从图2可以看出,近30年来重庆国内生产总值呈现指数型增长,并没有出现周期性和季节性的波动,可初步判断此序列属于非平稳序列。针对这个时间序列进行ADF单位根检验,可以得到 ,因此这个时间序列是非平稳的。对这个非平稳的序列进行第一次差分,得到一次差分后的折线图见图3所示,图中有明显的增长趋势,初步说明序列是不平稳的,在进行单位根检验后,得到, 进一步证明序列是不平稳的。这时需要进行第二次差分,得到二次差分后的折线图见图4所示,从图4可以看出序列是围绕0值上下波动的,但还是需要进行单位根检验来加以证明,最后得到 ,证明了此时的时间序列是平稳的。因此认为ARIMA(p,d,q)中 。
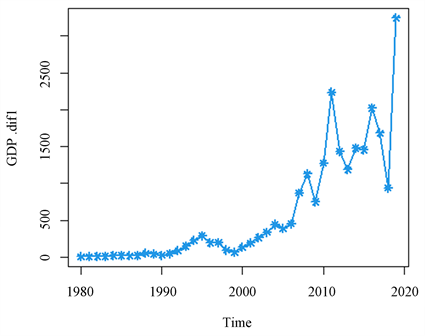
Figure 3. First-order differential GDP line chart
图3. 一阶差分GDP折线图
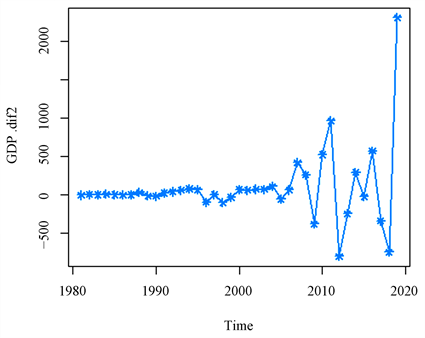
Figure 4. Second-order differential GDP line chart
图4. 二阶差分GDP折线图
4.2. 确定ARIMA模型的阶数
从上述分析得到,二次差分后的重庆GDP序列是平稳的,画出二次差分后序列的自相关PACF图见图5所示,偏自相关ACF图见图6所示。
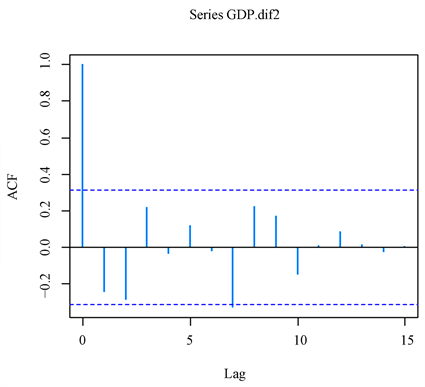
Figure 5. Autocorrelation diagram after second-order difference
图5. 二阶差分后的自相关图
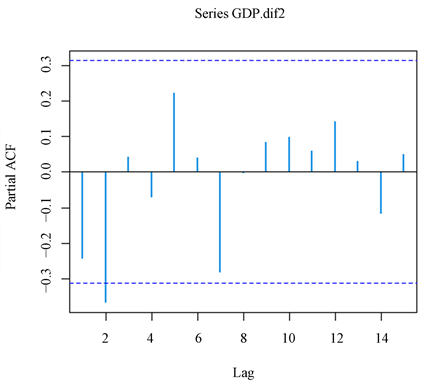
Figure 6. Partial autocorrelation diagram after second-order difference
图6. 二阶差分后的偏自相关图
从图5可看出,自相关系数都在2倍标准差范围内,并且是逐渐趋于零的;从图6可看出,偏自相关系数显示拖尾,所以选取 ,但是这样估计的模型具有很大的主观性,同时建立多个ARIMA模型以消除误差,分别选择:ARIMA(0,2,0),ARIMA(0,2,1),ARIMA(0,2,2),ARIMA(1,2,1),ARIMA(1,2,2),得到每个模型的AIC值或BIC值见表3所示,从表3中观察到,ARIMA(0,2,2)模型的AIC值或BIC值最小,因此该模型是最好的。
Table 3. Comparison of ARIMA models
表3. ARIMA模型的比较
4.3. 模型的检验
接下来我们对模型ARIMA(0,2,2)进行检验,ARIMA(0,2,2)模型检验表见表4所示。
Table 4. ARIMA(0,2,2) model checklist
表4. ARIMA(0,2,2)模型检验表
注:***、**、*分别代表1%、5%、10%的显著性水平。
表4中展示本次模型检验结果,包括样本数、自由度、Q统计量和信息准则模型的拟合优度。ARIMA模型要求模型的残差不存在自相关性,即模型残差为白噪声,查看模型检验表,根据Q统计量的Q值(p值大于0.1为白噪声)对模型白噪声进行检验;R2代表时间序列的拟合程度,越接近1效果越好。
根据ARIMA(0,2,2)模型检验表,基于字段:GDP (亿元),从Q统计量结果分析可以得到:Q6在水平上不呈现显著性,不能拒绝模型的残差为白噪声序列的假设,同时模型的拟合优度R2为0.997,模型表现优秀,模型基本满足要求。
可知对ARIMA(0,2,2)模型的残差进行白噪声检验,如果统计量的p值大于给定的显著性水平,则模型检验通过可以用来预测。此外利用R软件,得到p值也显著大于0.05,因此模型通过检验,可以用来预测。下面我们将给出ARIMA(0,2,2)模型残差自相关图(ACF)见图7所示,残差偏自相关图(PACF)见图8所示。
从图7展示了模型的残差自相关图(ACF),包括系数,置信上限和置信下限。横轴代表延迟数目,纵轴代表自相关系数;若相关系数均在虚线内,自回归模型(AR)残差为白噪声序列,时间序列要求模型残差为白噪声序列。
图8展示了模型的残差偏自相关图(PACF),包括系数,置信上限和置信下限。若相关系数均在虚线内,滑动平均模型(MA)残差为白噪声序列,时间序列要求模型残差为白噪声序列。综合上述图7和图8的分析可见,模型ARIMA(0,2,2)的残差是白噪声序列。接下来给出ARIMA(0,2,2)模型的参数表见表5所示。
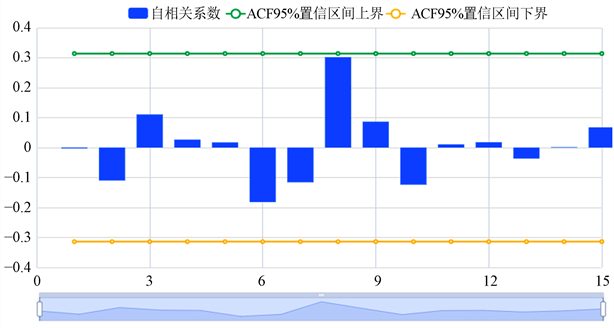
Figure 7. Residual autocorrelation diagram (ACF) of ARIMA(0,2,2) model
图7. ARIMA(0,2,2)模型残差自相关图(ACF)

Figure 8. Residual partial autocorrelation diagram (PACF) of ARIMA(0,2,2) model
图8. ARIMA(0,2,2)模型残差偏自相关图(PACF)
Table 5. Parameter table of ARIMA(0,2,2) model
表5. ARIMA(0,2,2)模型参数表
表5展示本次模型参数结果,包括模型的系数、标准差,T检验结果等,用于分析模型公式。基于字段GDP (亿元),根据模型ARIMA模型(0,2,2)检验表且基于2差分数据,模型公式如下:
(5)
我们给出了ARIMA(0,2,2)时间序列图,见图9所示,表示了该时间序列模型的原始数据图、模型拟合值、模型预测值。我们还用ARIMA(0,2,2)时间序列模型预测最近4期数据,并将预测情况列于预测表中,见表6所示。

Figure 9. ARIMA(0,2,2) time series diagram
图9. ARIMA(0,2,2)时间序列图
Table 6. ARIMA(0,2,2) time series forecast table
表6. ARIMA(0,2,2)时间序列预测表
此外为了更加客观的确定 ,还采用forecast包中的auto.arima()可以自动尝试不同的阶数组合并挑选出可能的最优模型。得到模型ARIMA(0,2,1),ARIMA(0,2,1)模型的基本指标见表7所示,ARIMA(0,2,1)模型检验表见表8所示。
在表8中展示本次模型检验结果,根据模型ARIMA模型(0,2,1)检验表,基于字段:GDP(亿元),从Q统计量结果分析可以得到:Q6在水平上不呈现显著性,不能拒绝模型的残差为白噪声序列的假设,同时模型的拟合优度R2为0.996,模型表现优秀,模型基本满足要求。对ARIMA(0,2,1)模型的残差进行白噪声检验,得到p值也显著大于0.05,因此模型通过检验,可以用来预测。
Table 7. ARIMA (0,2,1) model
表7. ARIMA(0,2,1)模型
Table 8. ARIMA (0,2,1) model checklist
表8. ARIMA(0,2,1)模型检验表
注:***、**、*分别代表1%、5%、10%的显著性水平。
另外,我们还给出了模型的残差自相关图(ACF)和残差偏自相关图(PACF)。ARIMA(0,2,1)模型残差自相关图(ACF)见图10所示,ARIMA(0,2,1)模型残差偏自相关图(PACF)见图11所示。综合分析图10和图11可见,模型ARIMA(0,2,1)的残差是白噪声序列。

Figure 10. ARIMA(0,2,1) model residual autocorrelation plot (ACF)
图10. ARIMA(0,2,1)模型残差自相关图(ACF)

Figure 11. ARIMA(0,2,1) model residual biased autocorrelation plot (PACF)
图11. ARIMA(0,2,1)模型残差偏自相关图(PACF)
下面给出ARIMA(0,2,1)模型检验表见表9所示。
Table 9. ARIMA (0,2,1) model checklist
表9. ARIMA(0,2,1)模型检验表
注:***、**、*分别代表1%、5%、10%的显著性水平。
表9展示本次模型参数结果分析:基于字段GDP (亿元),根据模型ARIMA模型(0,2,1)检验表且基于2差分数据,模型公式如下:
(6)
给出了ARIMA(0,2,1)时间序列图,见图12所示,表示了该时间序列模型的原始数据图、模型拟合值、模型预测值。我们还用ARIMA(0,2,1)时间序列模型预测最近4期数据,并将预测情况列于预测表中,见表10所示。

Figure 12. Time series plots
图12. 时间序列图
Table 10. ARIMA(0,2,2) time series forecast table
表10. ARIMA(0,2,2)时间序列预测表
4.4. 模型预测
利用通过检验的ARIMA(0,2,2)模型,预测2020年和2021年的重庆GDP,预测结果见表11所示。
Table 11. ARIMA (0,2,2) comparison of predicted and actual values
表11. ARIMA(0,2,2)预测值与实际值的比较
根据相对误差计算公式:相对误差 = (测量值 − 真实值)/真实值 × 100%,可得2020年、2021年GDP的相对误差值分别为0.44%和−2%。
利用通过检验的ARIMA(0,2,1)模型,预测2020年和2021年的重庆GDP,预测结果见表12所示。
Table12. ARIMA (0,2,1) comparison of predicted and actual values
表12. ARIMA(0,2,1)预测值与实际值的比较
根据相对误差计算公式可得2020年、2021年GDP的相对误差值分别为3.17%和0.3%。
经过ARIMA(0,2,2)模型和ARIMA(0,2,1)模型的AIC和BIC的以及相对误差比较,最终选择模型ARIMA(0,2,2)。当然,在前面的AIC和BIC比较时就可以选择模型ARIMA(0,2,2)。
可以看出该模型预测短时间内的值是比较准确的。1979年至2000年的GDP增长还比较的平缓,但是从2000年到2019年重庆的GDP增长是非常迅速的。随着预测时间周期的延长,预测的误差会逐渐增大。用得到的模型预测重庆2022年和2023年的GDP,预测的结果分别为29581.2亿元和31815.46亿元。但是由于2022年仍然存在新冠肺炎疫情的影响,2022年的GDP肯定会受到影响,所以预测出来的数据只能作为参考作用。
5. 基于BP神经网络对重庆GDP的预测的时间序列分析
5.1. 模型建立
神经网络是机器学习中一种常见的数学模型,通过构建类似于大脑神经突触联接的结构,来进行信息处理 [12] 。在应用神经网络的过程中,处理信息的单元一般分为三类:输入单元、输出单元和隐含单元。除了上述三个处理信息的单元之外,神经元间的连接强度大小由权值等参数来决定。
单步预测模型结构:
(7)
即:每一次取若干个历史点,只能往后推一步,此外还有多步预测结构,此处我们假设每 ,即每5个时刻便会影响下一个时刻的值;每个时刻的数据是历史5个时刻的数据(预测第六个数据,是时刻1~5的数据),步长为5。
此处我们采用这五个评价指标来进行分析:平均绝对误差MAE,均方误差MSE,均方根误差RMSE,平方相对误差MAPE,决定系数R2。
5.2. 评价指标
1) 平均绝对误差MAE:全称是Mean Absolute Error,它表示预测值和观测值之间绝对误差的平均值。公式如下
(8)
2) 均方误差MSE:全称是Mean Absolute Error,预测数据和原始数据对应点误差的平方和的均值。公式如下
(9)
3) 均方根误差RMSE:全称是Root Mean Square Error,它表示预测值和观测值之间差异(称为残差)的样本标准差。公式如下
(10)
4) 平方相对误差MAPE:全称是Mean Absolute Percentage Error,是相对误差度量值,它使用绝对值来避免正误差和负误差相互抵消,可以使用相对误差来比较各种时间序列模型预测的准确性。公式如下
(11)
5) 决定系数:R2 (coefficient of determination),也称为判定系数或拟合优度。公式如下
(12)
由此,我们根据上述五个评价指标来分析基于BP神经网络预测时间序列模型,并将评价指标数值列于表中,见表13所示。
Table 13. Judging criteria for forecasting time series models based on BP neural networks
表13. 基于BP神经网络预测时间序列模型的评判标准
决定系数越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比高。观察点在回归直线附近越密集。当R2越接近1时,表示相关的方程式参考价值越高;相反越接近0时,表示参考价值越低。对时间序列数据,判定系数达到0.9以上是很平常的,在表13中我们可以看出决定系数R2为0.94297,虽然说与模型ARIMA(0,2,2)相比较,拟合优度不及模型ARIMA(0,2,2)的拟合优度,但是效果也很不错。平方相对误差MAPE为0.083844,不到百分之十,一般而言,平方相对误差在百分之十一下效果良好,可见的基于BP神经网络预测时间序列模型的效果也很不错。
6. 基于MLP模型对重庆GDP的预测的时间序列分析
层感知器,简称MLPs,可用于时间序列预测。使用MLPs进行时间序列预测的难点在于数据的准备。具体来说,先前的时间步的值在输入时必须展平为特征向量。
6.1. 数据准备
在对单变量序列进行建模之前,必须先进行准备。MLP模型将学习将过去的观测序列作为输入映射到输出观测的函数。因此,必须将观察序列转换成可以从中学习模型的多个样本。假设有如下单变量序列,即使1979年~2019年重庆GDP数据集,我们可以将序列分为多个称为样本的输入/输出模式,其中三个时间步长用作输入,一个时间步长用作输出,用于单步预测。
6.2. 单变量MLP模型
一个简单的MLP模型具有单个隐藏的节点层和一个用于进行预测的输出层。每个样本的输入维度在第一个隐藏层定义的input dim参数中指定。从技术上讲,模型将把每个时间步看作一个单独的特征,而不是单独的时间步。
定义模型,模型期望训练数据的输入部分具有维度或形状。split_sequence()函数输出X的形状可用于建模。利用随机梯度下降算法Adam进行拟合,使用均方误差损失函数进行优化和训练。
在模型拟合后,可进行预测。通过输入重庆GDP连续三年的数据预测下一年的重庆GDP数据来预测序列中的下一个值。该模型期望输入形状是二维的,因此,在进行预测之前,必须重塑单个输入样本。
6.3. 模型结果
将基于MLP模型时间序列预测数值,以及根据相对误差计算公式:相对误差 = (测量值 − 真实值)/真实值 × 100%,所求得的相对误差见表14所示。
Table 14. Time series forecast table based on MLP model
表14. 基于MLP模型时间序列预测表
7. 基于CNN对重庆GDP的预测的时间序列分析
CNN可以用来对单变量时间序列预测问题进行建模。单变量时间序列是由具有时间顺序的单个观测序列组成的数据集,需要一个模型从过去的观测序列中学习以预测序列中的下一个值。
7.1. 数据准备
本文对重庆1979年至2021年的42个数GDP据进行了分析,选取前面40个GDP数据用来建模,并用后2年的数据来检验模型的效果,预测2022年和2023年的GDP。
将序列分成多个输入/输出模式,称为样本,其中三个时间步作为输入,一个时间步作为输出,并据此来预测一个时间步的输出值。通过一个split_sequence()函数来实现上述操作,该函数可以将给定的单变量序列拆分为多个样本,其中每个样本具有指定数量的时间步,并且输出是单个时间步。
7.2. CNN模型
CNN模型有一个卷积隐藏层,在一维序列上工作。在某些情况下,这之后可能是第二卷积层,例如非常长的输入序列,然后是池化层,其任务是将卷积层的输出提取到最显著的元素。卷积层和池化层之后是全连接层,用于解释模型卷积部分提取的特征。在卷积层和全连接层之间使用展平层将特征映射简化为一个一维向量。
7.3. 模型建立
模型的关键是输入形状参数;这是模型在时间步数和特征数方面期望作为每个样本的输入。我们使用的是一个单变量序列,因此特征数为1。时间步数是在划分数据集时split_sequence()函数的参数中定义。
每个样本的输入形状在第一个隐藏层定义的输入形状参数中指定。因为有多个样本,因此,模型期望训练数据的输入维度或形状为:[样本,时间步,特征]。split_sequence()函数输出的训练数据X的形状为[样本,时间步],因此应对X重塑形状,增加一个特征维度,以满足CNN模型的输入要求。
CNN实际上并不认为数据具有时间步,而是将其视为可以执行卷积读取操作的序列。我们定义了一个卷积层,接下来是一个最大池化层和一个全连接层来解释输入特性。最后,输出层预测单个数值。该模型利用有效的随机梯度下降进行拟合,利用均方误差损失函数进行优化。处理好训练数据和定义完模型之后,接下来开始训练,
在模型拟合后,可以利用它进行预测。假设输入2017~2019年的GDP数据来预测序列中的下一个值。该CNN模型期望输入形状是三维的,形状为[样本、时间步、特征],因此,在进行预测之前,必须重塑单个输入样本为三维形状。将基于CNN模型时间序列预测数值,以及根据相对误差计算公式所求得的相对误差见表15所示。
Table 15. Time series prediction table based on CNN model
表15. 基于CNN模型时间序列预测表
8. 基于LSTM模型对重庆GDP的预测的时间序列分析
长短期记忆网络(LSTM),LSTM是一种改进的循环神经网络(Recurrent Neural Network),它解决了RNN中的梯度消失和长期依赖的问题。
8.1. 单变量LSTM模型
单变量LSTM模型(Univariate LSTM Models),LSTMs可用于单变量时间序列预测问题的建模。这些问题由单个观测序列组成,需要一个模型从过去的观测序列中学习,以预测序列中的下一个值。下文将演示重庆GDP一元时间序列预测的LSTM模型。分为以下五个部分:该5种LSTM模型都可用于单时间步单变量时间序列预测。
1) Vanilla LSTM是一个LSTM模型,它有一个单隐层的LSTM单元和一个用于预测的输出层。与CNN读取整个输入向量不同,LSTM模型一次读取序列的一个时间步,并建立一个内部状态表示,来学习上下文信息,从而进行预测。
2) Stacked LSTM即堆叠LSTM,可以将多个LSTM层堆叠在一起。LSTM层需要三维输入,LSTM的默认输出为二维,可以通过设置参数使得LSTM的输出形状为三维。这样就可以作为下一层的输入。
3) Bidirectional LSTM,在一些序列预测问题上,允许LSTM模型向前和向后学习输入序列,并将两种解释连接起来是有益的。这称为双向LSTM。我们可以通过将第一个隐藏层包装在一个称为双向的包装层中来实现用于单变量时间序列预测的双向LSTM。
4) CNN-LSTM,CNN可以非常有效地从一维序列数据(如单变量时间序列数据)中自动提取和学习特征。CNN模型可用于具有LSTM后端的混合模型中,其中CNN用于解释输入的子序列,这些子序列作为一个序列提供给LSTM模型来解释。这种混合模型称为CNN-LSTM。
5) ConvLSTM,输入的卷积读取直接构建到每个LSTM单元中。该方法可用于单变量时间序列预测。
8.2. 数据准备
在对单变量序列建模之前,必须做好准备。LSTM模型学习一个映射规则,该规则以过去的序列观测值作为输入,然后输出预测值。因此,观测序列必须转换LSTM可以学习的多个样本。考虑一个单变量序列即重庆GDP的观测值,将序列分成多个输入/输出模式,称为样本,其中三个时间步(的观测值)作为输入,一个时间步(的观测值)作为输出,数据集构建好之后,定义网络模型,进行训练。
8.3. 模型输出
为了方便比较基于单变量LSTM模型时间序列预测数值,以及根据相对误差计算公式所求得的相对误差见表16所示。
Table 16. Time series forecast table based on univariate LSTM model
表16. 基于单变量LSTM模型时间序列预测表
9. 结语
为了方便各个模型对重庆GDP时间序列的分析对比,将各个模型的预测结果统计在表17中。
Table 17. Time series comparison table based on each model
表17. 基于单变量LSTM模型时间序列预测表
从表17中看出,在2020年中,基于ARIMA(0,2,2)模型预测的结果25113.65最接近真实值25,003,相对误差的绝对值最小,为0.44%,而基于Stacked LSTM模型预测的结果27010.244,离真实值25,003最远,相对误差的绝对值最大,为8.03%;在2021年中,基于单变量MLP模型预测的结果27841.172最接近真实值27894.02,相对误差的绝对值最小,为0.2%,而基于CNN模型预测的结果25827.166,离真实值27894.02最远,相对误差的绝对值最大,为7.4%;在平均绝对误差水平中,CNN模型的平均绝对误差水平最大,为5.255%,为ARIMA(0,2,2)模型的平均绝对误差水平最小,为1.22%。因此,可以看出ARIMA(0,2,2)模型的预测效果是最好的。
时间序列主要是利用过去和现在的数据对未来数据进行预测的一种方法。在建模分析预测的过程中,首先建模数据需要满足平稳性的条件,若不满足,则需要进行处理使其通过检验,比如处理的方法有差分和取对数,然后再依据画出的ACF图和PACF图,确定出模型为ARIMA(0,2,2),接着模型要通过参数的显著性检验和残差的白噪声检验,增加模型的可信度使其更具说服力,预测的结果与实际值之间的误差比较也证明了模型的可行性。在实际应用过程中,ARIMA模型预测短期的效果很好,但预测时间的延长会导致模型的误差变大。比较2020年、2021年的预测值和实际值的过程中,会发现误差还是不能够忽视的,用ARIMA模型只能做短期的预测,仅以用来参考。
文章引用
叶茂越. 基于各模型对重庆GDP实证分析
Empirical Analysis of Chongqing GDP Based on Various Models[J]. 运筹与模糊学, 2023, 13(02): 1301-1319. https://doi.org/10.12677/ORF.2023.132132
参考文献
- 1. Box, G.E.P. (1976) Science and Statistics. Journal of the American Statistical Association, 71, 791-799. https://doi.org/10.1080/01621459.1976.10480949
- 2. Box, G.E.P. (1987) Empirical Model-Building and Response Surfaces. John Wiley & Sons, Inc., State of New Jersey.
- 3. Box, G.E.P. (2005) Statistics for Experi-menters. 2nd Edition, John Wiley & Sons, Inc., State of New Jersey.
- 4. Jenkins, G.M. (1983) Case Studies in Time Series Analysis. John Wiley & Sons, Inc., State of New Jersey.
- 5. Jenkins, G.M. (1979) Practical Experience with Modelling and Forecasting Time Series. John Wiley & Sons, Inc., State of New Jersey.
- 6. 赵子萌. 基于ARIMA时间序列模型预测成都市GDP [J]. 通讯世界, 2019, 26(2): 206-207.
- 7. 李辰飞, 常婕, 沈燕. ARIMA模型在湖北省GDP预测中的应用[J]. 湖北师范学院学报(哲学社会科学版), 2015, 35(4): 62-66.
- 8. 华鹏, 赵学民. ARIMA模型在广东省GDP预测中的应用[J]. 统计与决策, 2010(12): 166-167.
- 9. 张文韬, 李瑛琪. 基于ARIMA模型的河南省GDP指数分析[J]. 洛阳师范学院学报, 2019, 38(2): 11-14.
- 10. 瞿海情, 何先平. 基于时间序列分析的湖北省GDP预测模型研究[J]. 湖北经济学院学报(人文社会科学版), 2021, 18(9): 37-39.
- 11. 王燚. 重庆市GDP的预测及发展的政策建议[J]. 商讯, 2021(16): 14-16.
- 12. 张朝龙, 卢阳, 杨璇, 胡靓靓. 基于集成ARIMA模型与BP神经网络的锂电池容量预测[J]. 安庆师范大学学报(自然科学版), 2022, 28(2): 15-18.