Computer Science and Application
Vol.07 No.06(2017), Article ID:21097,10
pages
10.12677/CSA.2017.76069
The Comparison of “Big Data” Literatures Analysis Tools: Taking Citespace and SCI2 as Examples
Jing Yang1,2,3, Changxiu Cheng1,2,3
1Key Laboratory of Environmental Change and Natural Disaster, Beijing Normal University, Beijing
2Faculty of Geographical Science, Beijing Normal University, Beijing
3Center for geographic data and Analysis, Beijing Normal University, Beijing

Received: Jun. 5th, 2017; accepted: Jun. 20th, 2017; published: Jun. 23rd, 2017

ABSTRACT
Recently, the information is too much to induce revolution. For researchers, the speed of update of knowledge is faster and faster. However, the mass and various data do not mean high accurate. It is a big challenge to get the important academic resources quickly and accurately and master research’s skeleton, frontiers and hot topics. This article took the Citespace and SCI2 as example, then summarized their complementary roles in data acquisition, data preprocessing, data visualization. After that an earthquake case was shown. Their complementarities are as follows: a) Data sources. Citespace can analyze both Chinese and English articles. SCI2 is just for English articles and it has more English data source than Citespace. b) Data preprocessing. SCI2 can merge the synonyms automatically but may miss merged. And as Citespace need a lot of manual work to build a synonym table, it is laborious. c) Network output. The network outputted by SCI2 is editable. However, the network from Citespace cannot do it. But the network of citespace is clear due to its path finder function. d) Visualization. Besides undirected network, SCI2 can output directed network which would express the directed relationship between nodes. The nodes in network of Citespace can express the centrality beside the occurrence frequency. Time zone map is another advantage of Citespace, it could reflect research hot topics changes with the time.
Keywords:Bibliometrics, Data Mining, Citespace, SCI2
文献“大数据”分析软件Citespace和SCI2的对比分析研究
杨静1,2,3,程昌秀1,2,3
1北京师范大学环境演变与自然灾害教育部重点实验室,北京
2北京师范大学地理科学学部,北京
3北京师范大学地理数据与应用分析中心,北京
收稿日期:2017年6月5日;录用日期:2017年6月20日;发布日期:2017年6月23日

摘 要
当今世界,信息爆炸已经累积到了一个可以引发变革的时刻,对学术研究者而言,知识更新迭代周期不断缩短,然而海量、多元的数据并不等于精准的数据贮备。如何快速精准获取重要学术资源,掌握研究前沿、热点与脉络是大数据时代学术研究者共同面临的挑战。本文以Citespace和Science of Science(SCI2) Tool为例,从数据源、数据预处理、数据可视化几方面总结了二者在文献数据挖掘中的优势互补作用,并加以地震实例分析。二者互补情况主要有以下几点:1) 数据源。Citespace可以分析中英文文献,而SCI2只限英文文献,不过英文数据源更广;2) 数据预处理。SCI2能自动合并拼写相近的单词,但有时会出现误合或漏合的情况;而Citespace则需人工添加同义词对照表,可以避免这种情况,但处理工作量较大;3) 网络输出。SCI2输出的网络可编辑能力强;而Citespace编辑能力相对较差,不过其剪枝功能使得剪枝后的网络研究脉络更清晰;4) 可视化方式。SCI2除无向网络外还可生成有向网络,有向网络能更好地反映研究之间的指向关系;Citespace的网络节点除能表达出现次数多少之外,还能给出节点中心度,并且Citespace的时域图能更好地反映研究随时间变化的特点。
关键词 :文献计量学,数据挖掘,Citespace,SCI2

Copyright © 2017 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
当今时代正在经历一场革命性的变化,人类正在由工业化进入信息化时代,信息爆炸已经达到了一个可以引发变革的时刻,人们把这些海量的数据称为“大数据(big data)”。对学术研究者而言,上千种数据库、几十万的期刊、上亿篇文献,各种意义丰富的信息充斥着科研工作,然而海量、多元的数据源并不等于精准的数据准备。如何全面、深入的挖掘文献资料,快速精准的获取学术重要资源,掌握研究前沿、热点与脉络,从数据库中发现学术研究的规律并得出结论,是大数据时代学术研究者共同面临的挑战。
传统的文献分析方法需要大量的计算与绘图操作,就作者共引分析为例,分析者首先必须通过各种来源确定能够覆盖一个学科各个分支的作者集合,进而通过分析程序,并依赖于支持因子分析、多维尺度和聚类分析的统计工具(如SPSS),通过多维图观察相似性而形成簇,同时借助统计方法确定作者的重要性 [1] 。繁琐的数据收集和计算过程严重阻碍了分析方法的应用,近年来很多基于引文分析、共引分析、词频分析的可视化软件的出现推动了本学科的发展。如,Citespace、CoPalRed、Science of Science (SCI2) Tool、VOSViewer等,这些软件通过可视化的手段呈现科学知识的结构、规律和分布情况,研究过程大大简化。本文以Citespace和Science of Science (SCI2) Tool为例,从数据源、数据预处理、数据可视化几方面总结了二者在文献分析过程中的优势互补。并加以“地震”实例分析。
2. 分析工具介绍
Citespace是美国Drexel大学陈超美教授开发的用来分析和可视共被引网络的JAVA应用程序。他主要是基于共引(co-citation)分析理论和寻径(PathFinder)网络算法等,对特定领域文献进行计量,以探寻出学科领域演化的关键路径及其知识拐点,并通过一系列可视化知识图谱的绘制来形成对学科演化潜在动力机制的分析和学科发展前沿的探测 [2] [3] 。
SCI2是印第安纳大学的Katy Börner及其团队开发的一款知识图谱分析软件。它集时空、主题、网络分析一体,以及支持大中小三个尺度的可视化。用户可以在线获取数据或者是加载自己已有数据,使用恰当的方法进行不同类型的分析,利用不同的可视化插件,如GUESS,交互式的探索和理解特定的数据集。并且是一个开源的软件框架,易于集成和应用数据集、算法和工具 [4] 。
二者均支持文献数据挖掘,用科学地图来表示学科、领域、文献、作者间的内在联系 [5] ,以科学知识可视化的形式展示学科知识间的相互联系、学科的知识架构还有科学研究的动态变化 [6] 。但SCI2有不同的可视化插件及其开源优势使得SCI2较Citespace功能更丰富,而Citespace更易掌握。目前Citespace在国内文献分析领域应用更广、更成熟 [7] - [11] 。研究人员可以根据自己需要选择适当的分析工具。
3. 分析工具比较
文献数据挖掘过程一般分为数据源获取、数据预处理、数据可视化几个步骤。下面依次从上述几阶段入手,基于笔者实际使用经验,分析论述Citespace和SCI2两个工具软件的优劣,为研究学者提供一些研究基础和启发。
3.1. 数据源获取
Citespace是一款中英文文献均可作为分析对象的软件,可以分析不同来源的数据,包括文献数据,比如WOS、Scopus、CNKI、CSSCI等;还有一些其他数据,比如NSF、Derwent等。目前外文文献以WOS数据库数据居多,WOS数据下载时以纯文本格式存储全纪录和参考文献。中文文献的研究以CNKI和CSSCI为主,CSSCI需要有权限才能进行数据下载,CNKI即使没有数据权限也可以分析所收集的数据。来自CNKI和CSSCI的数据需要利用Citespace软件格式转化之后才能进行分析。
SCI2主要支持英文文献的分析。它支持多种数据和数据格式,比如,期刊文献、专利、基金和临床试验等数据类型 [12] 以及.xml、.net、.isi、.csv、.bib、.enw、.nsfdeng等数据格式。它除WOS和Scopus外还可分析Google Scholar数据。
Citespace在数据源包括中英文文献,而SCI2只可分析英文文献,但可用于SCI2分析的英文文献数据源更广。用户可以根据文献库和文献格式选择恰当的分析工具。
3.2. 数据预处理
数据预处理是数据分析之前保证数据质量的关键步骤。文献计量学分析是基于文献的共被引分析,来源于数据库的原始数据难免会出现作者名的拼写方式多样、一个词有多种表达方式或重复记录等情况。这些异形同义短语及重复记录会影响短语出现的频率。分析工具将这些实际上表示同一人、同一期刊名短语以及同一记录当成不同对象表示出来。例如:earthquake、seismic、earthquakes这些词均表示地震,但是分析工具却将他们识别成三个不同的词。所以数据分析之前有必要通过词汇合并和去重来提高数据质量,保证数据精度。
Citespace的同义词合并比较精确但耗时耗力。它的同义词合并是通过手动建立别名文件(Alias List),将需要合并的词汇手动添加到文件,在数据可视化之前调用该文件然后合并词汇,另外还有专门针对WOS数据的数据记录去重功能——remove duplicates,该功能直接删除文献数据的重复记录。
SCI2的同义词合并功能高效但出错率也对应增加。SCI2通过“检测双节点(detect duplicate nodes)”功能,人为设定相似性系数,然后自动合并大于某一相似度的词,并对临近该相似度的词予以警告,如图1。例如,相似度在0.95以上的节点合并,相似度在0.85到0.95之间的节点给予警告但不合并。这样合并方式使得类似于单复数差别的“s”或“es”的微小差异很容易被检测出来,所以如果有大量需要处理的数据时,这种自动检测的方式将节省很多人力和时间。但会导致“but”和“nut”这样虽然拼写相近,但意思完全不同的词汇的误合。并且也不适用于有些书写形式差异较大但表示表示意思相同词或差异虽小但非同义词的情况,比如,全称与缩写(GIS与Geographic Information System)、Earthquake和Seismic、reverse和revert。
所以,Citespace和SCI2在数据预处理过程中各有优势与不足,SCI2更适合大量数据的去重,但却不适用于有些书写形式差异较大但表示表示意思相同词或差异虽小但非同义词的情况,Citespace需人工添加同义词对照表,故处理工作量较大。
3.3. 数据可视化
3.3.1. 输入设置
数据输出由输入设置决定。Citesapce首先根据不同的标准对文章的重要性排序,选择性输出比较重要的文章。它在可视化之前有四个选择标准,如图2,分别是:1) 每个时间段一定数量的出现次数最多的短语或引用最多的文献;2) 每个时间段一定比例的出现次数最多的短语或引用最多的文献;3) 根据最低被引频次或出现次数、共被引频次或共现次数以及共被引系数确定符合条件的数据;4) 先选施引文献,然后再用方法1~3之一。使用者选取任意一种标准,指定输出文章范围。
SCI2可以高效的一次性输入全部数据,这也是它优于大部分文献分析软件的地方。大部分的文献分析软件均只能处理中小规模的数据量(<100,00条数据),SCI2能处理百万甚至上亿条的数据记录 [7] ,将输入的节点全部可视化显示输出,如图3。这样有助于保留节点间的所有相关关系,使用者可以对全数据图进行观察之后,根据自己需要提取各自有用信息。
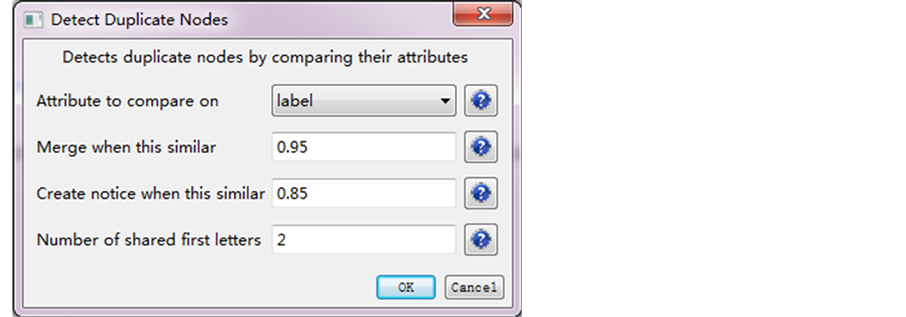
Figure 1. Detect duplicate nodes
图1. 重复节点检测
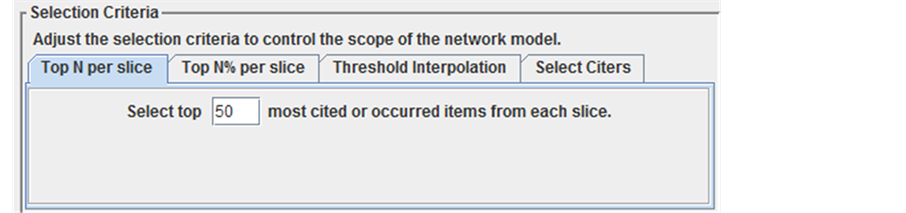
Figure 2. Dialog box of selection criteria
图2. 选择标准对话框
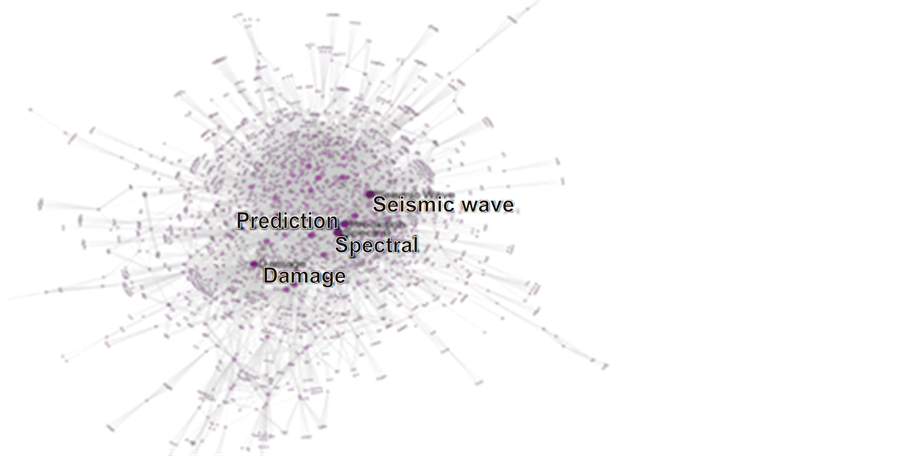
Figure 3. Visualization of SCI2 by the form of network
图3. SCI2网络可视化
所以,在数据输入阶段,Citespace是比较有目的性,先将数据提炼然后分析。Citespace输出数据精简但我们难以判断隐去数据是否包含有用信息;而SCI2是先输出所有数据,用户根据需要选择符合条件的信息。SCI2的全数据虽包含了全部有用信息但数据量庞大,需要足够的判断力来挖掘有用信息。
3.3.2. 数据可视化方式
不同的可视化形式可以传达不同的信息,在可视化表达方面,两种软件都有各自的优势。
可视化方面,Citespace有三种数据可视化的方式,网络图、时间线和时间域视图;SCI2支持网络分析、时序和地理空间分析。他们都可以生成时域图,但Citespace的时域分析图较SCI2的时域分析图应用更加广泛;他们都可以用于网络分析,Citespace除表示出现频次或共现次数之外还可以突出高中心度的节点,SCI2除无向网络外还可以生成有向网络以表示对象间的指向关系。网络图体现主要节点和节点间的关系;时间线视图侧重于描述聚类之间的关系和某一文献对学科影响的历史跨度;时间域视图从另一角度描述知识的发展过程并清晰表示节点之间的联系 [13] 。网络图的节点对象可以是作者、研究机构、参考文献、关键词等任何一种,如果两个节点共同出现在一篇文章则用直线连接来表示他们之间的相关性。如图4,通常节点大小与其出现次数正相关,节点越大其出现次数越多。此外,该图还可以突出高中心度节点,图中用红圈表示,这些节点在整个网络中起重要的连接作用。时域图以时间轴的形式展示了各个时间段的研究热点,如图5。该图主要用来分析某领域研究随时间的变化情况,或某一具体时间段内学者们的关注热点。目前主要用于网络分析,包括有向网络、无向网络、文献引用网络、作者网络、词共现和作者共现网络等。有向网络是SCI2的一大优势,如图6所示,它可以表达对象间的指向关系。比如在作者引用、文献引用分析时,有向网络可以明确区分引用与被引用文献和作者。
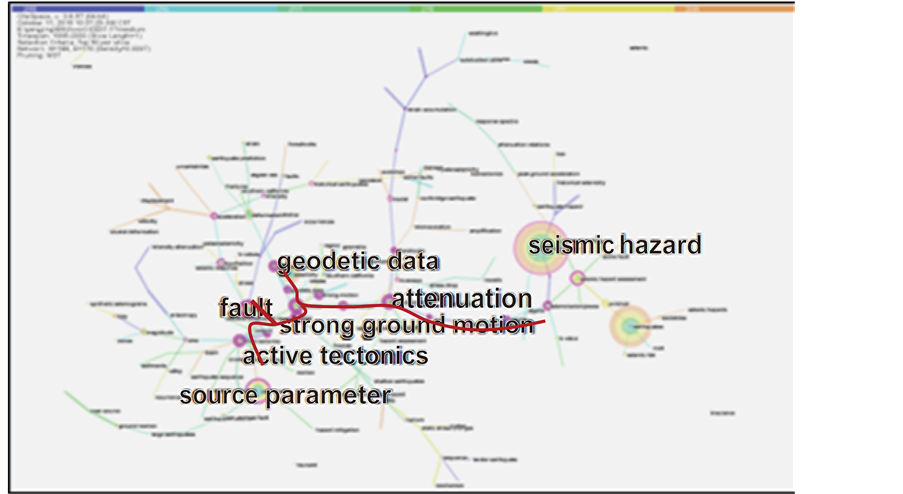
Figure 4. Network of Co-occurrence Network
图4. 节点共现网络图

Figure 5. Time zone figure
图5. 时域图
编辑能力方面,SCI2的编辑能力优于Citespace。网络生成后,基于Citespace的网络不可人为修改删减节点,而SCI2可以在生成网络的基础上进一步人工选择所需节点。在SCI2全纪录生成网络的基础上,我们能够根据需要有选择的提取自己感兴趣的信息,如图7所示。比如提取节点大小小于8,边的权重等于5的节点或边。经信息提取后的图清晰显示了节点之间的关系。
3.4. 小结
本节内容依次从数据源、数据预处理、数据可视化整个数据挖掘阶段介绍了Citespace和SCI2在相关过程中的优势互补作用,如表1。差异主要体现在:1) 数据源。Citespace可以分析中英文文献,在国内
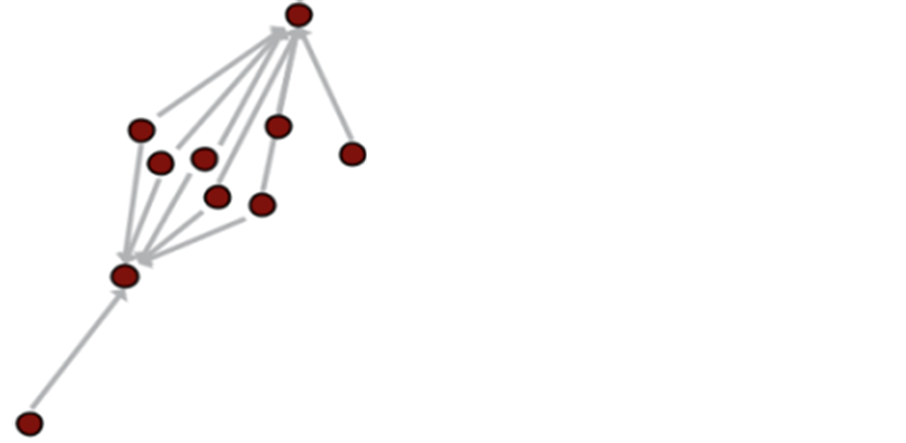
Figure 6. Directed network of citation
图6. 文献引用有向网络
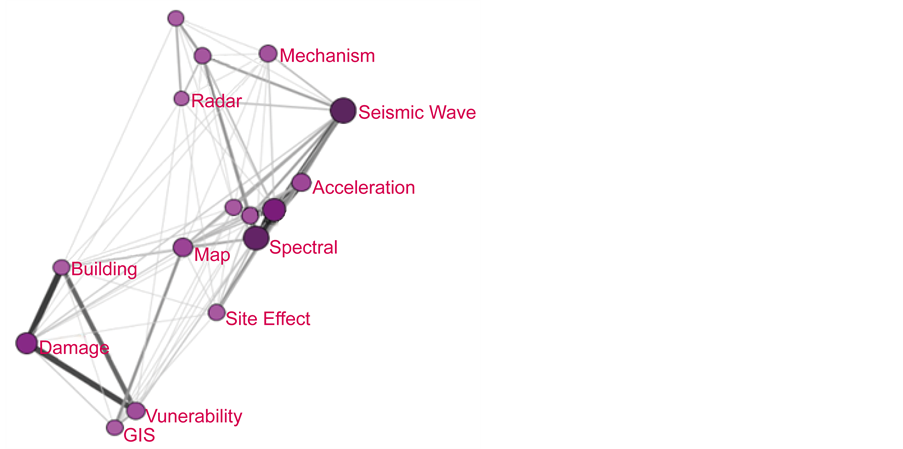
Figure 7. Extraction of information
图7. 信息提取

Table 1. The Advantages of SCI2 and Citespace
表1. Citespace和SCI2优势互补表
文献分析领域应用较广,SCI2数据来源是英文数据库,英文数据源更广;2) 数据预处理。Citespace在同义词合并时手动添加同义词表,故工作量庞大;SCI2在同义词合并时是通过相似性检测功能自动合并,节省了人力和时间,但却不适用于书写形式差异较大但是同义词,或差异虽小但非同义词的情况;3) 网络输出。Ciespace只能输出部分节点并且不能删减不相关节点而SCI2可以输出全部相关节点,然后人们根据需要筛选各自所需信息。4) 可视化方式。二者均能生成时域和空间网络图。SCI2的有向网络能更好地反映引用文献之间的指向关系,而Citespace的网络节点除能表达出现次数多少之外,还能给出节点中心度,节点中心度体现了节点在网络连接中的重要性。并且Citespace的时域图能更好地反映研究随时间变化的特点。总的来说两个软件各有优缺点,在实际分析中应互相结合,优势互补。
4. 实例分析
数据分析是通过可视化图谱结合作者已有的专业知识挖掘有用信息的过程。它和前面几个过程紧密结合,良好的数据预处理过程保证清晰的可视化图谱,充足的科学知识图谱知识保证了清晰的分析思路。最后通过图谱、分析思路和专业知识结合来提取有价值的信息。
研究学者根据可视化结果进行热点分析,热点转移以及研究内容的相互关系。出现次数越多的词汇即是对应时段的研究热点;不同时段的研究热点变化表征研究热点的演变;节点之间的连接表征节点之间关系的远近。数据分析主要从作者、研究机构、期刊、参考文献、关键词几个方面,从共引网络图和时域图两个角度分析。作者分析有被引频次、作者共现和作者所属国别等研究方式;研究机构分析从出现频次和机构间共现角度分析研究机构对学科领域的贡献和机构间的合作情况;期刊分析从期刊的被引频次出发分析对学科领域有重要影响力的期刊;参考文献分析从被引频次出发挖掘本学科的基础文献或是对学科有重大影响意义的文献,从时域角度出发挖掘对某一时间段学科有重要影响的文献,以及根据学者们关注文献随时间的变化探讨本学科的发展情况;关键词分析与参考文献分析比较接近,从出现频次角度挖掘研究热点,从时域角度挖掘学科的变化情况。每个节点以年轮形式表示:年轮颜色由内而外与出现年份相对应,每种颜色半径与出现次数正相关,整个年轮半径与关键词出现次数正相关。
4.1. Citespace实例分析
实验数据来自WOS数据库1995~2000年的地震主题文献数据。数据分析以1年为周期,提取每年被引次数排名前50的文献为研究对象,网络生成算法是最小生成树。
从共现网络图得出:如图4,地震危险性是地震领域的热点研究,地震风险研究主要从震源参数、断层、地面运动加速度几方面展开讨论。图中无论次数最多或者中心度最高的关键词均与地震风险有关。例如,seismic hazard是出现次数最多的关键词,source parameter、fault、active tectonics居其次。图中seismic hazard assessment、strong ground motion、source parameter、attenuation、fault、geodetic data等红色节点是中心度较高的节点,同时也是构成整个图谱的主要骨架点,这也表示这些关键词是本学科的骨干词汇,本学科主要围绕这些词汇展开研究。
从时域图谱得出:如图5,圣安地列斯断层的研究集中在96年(圣安地列斯断层是地球表面最长和最活跃的断层之一);地震灾害的评估分析主要集中在98年。从左到右依次为1995~2000年6个时间域。每个时间域对应该时间段主要的研究问题。96年对应的关键词是San-andreas fault,98年出现最多的词是seismic hazard assessment。
4.2. SCI2实例分析
实验数据来自WOS数据库2013-2015年的与地震相关的文献数据。经过节点去重等数据处理,实验结果如图3,该图显示了13~15年实验文献的全部关键词。节点代表作者关键词,连线代表二者之间关系。
图3表明:2013~2015年间,地震波、波谱特征、地震预测和地震损坏是该时间段的研究热点。图3中出现次数最多的关键词节点有seismic wave、prediction、spectral、Damage等。与1995~2000年相比,研究对象有了明显的转移。图3包括了13~15年所有关键词节点信息,所以网络略显杂乱。本例进一步筛选节点(numberofwork > 30),如图7,成功凸显了新的信息。
图7表明:研究热点从之前的危险性评估转向了脆弱性的分析;脆弱性分析主要从建筑物及其毁坏程度的角度评价;GIS是主要的研究手段。图7中building、damage、vulnerability联系密切,GIS和map紧密相连,seismic wave和spectral相关,均符合人们的一贯研究逻辑。
5. 总结
本文比较了大数据挖掘之文献数据挖掘的两个软件——SCI2在数据源、数据预处理、数据可视化、数据分析等整个数据处理过程中的优缺点。它们均能表达作者、关键词的共现以及作者和参考文献的共引关系。Citespace的网络可视化图谱包含了高中心度节点、突变节点、节点出现次数多少、节点间关系等信息,比SCI2单幅图谱传播信息更丰富;Citespace的时域图谱时域图能更好地反映研究随时间变化的特点,在国内文献分析领域应用更广,但SCI2也有很多Citespace所不及的优势,比如SCI2更适用于大数据的节点去重;SCI2可以对已生成的图谱加以筛选,删减不需要节点等主观操作,而Citespace不能改变已成型的网络结构。此外,它还可生成有向网络以表示对象间的指向关系。
文献挖掘可视化软件的出现大大节省了研究学者从海量文献中挖掘自己所需知识的时间和精力。它们以节点和网络的形式将作者、参考文献、期刊和关键词等连接,形成研究领域的知识框架。同时,也提供了时域和网络等多种可视化方式传达信息。所以我们在分析应用中应根据自己的需求合理选择分析工具或者多种工具相结合的全面分析,从数据库中发现学术研究的规律并得出结论, 快速精准的获取学术重要资源,掌握研究前沿、热点与脉络。
资助信息
国家自然科学基金优秀青年科学基金项目(41222009);国家自然科学基金面上项目(41271405);中央高校基本科研业务费专项资金资助
文章引用
杨 静,程昌秀. 文献“大数据”分析软件Citespace和SCI2的对比分析研究
The Comparison of “Big Data” Literatures Analysis Tools: Taking Citespace and SCI2 as Examples[J]. 计算机科学与应用, 2017, 07(06): 580-589. http://dx.doi.org/10.12677/CSA.2017.76069
参考文献 (References)
- 1. White, H.D. (2003) Pathfinder Networks and Author Cocitation Analysis: A Remapping of Paradigmatic Information Scientist. Journal of the American Society for Information Science and Technology, 54, 423-434. https://doi.org/10.1002/asi.10228
- 2. 陈悦, 陈超美, 刘泽渊. Citespace知识图谱的方法论功能[J]. 科学学研究, 2015, 33(2): 242-253.
- 3. 樊瑛, 任素婷. 基于复杂网络的世界贸易格局探测[J]. 北京师范大学学报(自然科学版), 2015(2): 140-143+221.
- 4. 邱小花, 李国俊, 肖明. SCI2——一款新的知识图谱分析软件介绍与评价[J]. 图书馆杂志, 2013, 32(9): 79-87.
- 5. Small, H. (1999) Visualizing Science by Citation Mapping. Journal of the American Society for Information Science, 50, 799-813. https://doi.org/10.1002/(SICI)1097-4571(1999)50:9<799::AID-ASI9>3.0.CO;2-G
- 6. Cobo, M.J., López-Herrera, A.G., Herrera-Viedma, E., et al. (2011) Science Mapping Software Tools: Review, Analysis, and Cooperative Study among Tools. Journal of the American Society for Information Science, 62, 1382-1402. https://doi.org/10.1002/asi.21525
- 7. Zhang, X., Gao, Y., Yan, X.D., et al. (2015) From E-Learning to Social-Learning: Mapping Development of Studies on Social Media-Supported Knowledge Management. Computer in Human Behavior, 51, 803-811. https://doi.org/10.1016/j.chb.2014.11.084
- 8. Wu, Y. and Duan, Z.G. (2015) Analysis on Evolution and Research Focus in Psychiatry Field. BMC Psychiatry, 12, 105-129. https://doi.org/10.1186/s12888-015-0482-1
- 9. Xie, P. (2015) Study of International Anticancer Research Trends via Co-Word and Co-Citation Visualization Analysis. Scientometrics, 105, 611-622. https://doi.org/10.1007/s11192-015-1689-0
- 10. Fang, Y.Q. (2015) Visualizing the Structure and the Evolving of Digital Medicine: A Scientometrics Review. Scientometrics, 105, 5-21. https://doi.org/10.1007/s11192-015-1696-1
- 11. Gao, Y., Qu, B., Shen, Y., et al. (2015) Bibliometric Profile of Neurogenic Bladder in the Literature: A 20-Year Bibliometric Analysis. Neural Regeneration Research, 10, 797-803. https://doi.org/10.4103/1673-5374.156985
- 12. Light, R.P., Polley, D.E. and Börner, K. (2014) Open Data and Open Code for Big Science of Science Studies. Scientometrics, 101, 1535-1551.
- 13. Kim, M.C. and Chen, C.M. (2015) A Scientometric Review of Emerging Trends and New Developments in Recommendation Systems. Scientometrics, 104, 239-263. https://doi.org/10.1007/s11192-015-1595-5