Operations Research and Fuzziology
Vol.05 No.01(2015), Article ID:14871,7
pages
10.12677/ORF.2015.51002
A Hybrid EDA with GA for the Permutation Flow Shop Scheduling Problem
Zhuzhi Liu, Kai Wang
School of Economics and Management, Wuhan University, Wuhan Hubei
Email: lzz_cau_whu@163.com
Received: Feb. 6th, 2015; accepted: Feb. 18th, 2015; published: Feb. 26th, 2015
Copyright © 2015 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
The permutation flow shop scheduling problem is a classical combinatorial optimization in industrial engineering. Population-based evolutionary algorithms (EA) are the common methods to solve this problem. As a novel EA, estimation of distribution algorithm (EDA) directs the algorithm search towards good solutions by statistical learning. However, this algorithm may trap into the local optimal and lead to the premature convergence. To overcome the drawback of EDA, this paper incorporates EDA with GA to address the PFSP. The participation rates of EDA and GA are adaptively regulated by fuzzy logic controller. The experiment results on the benchmarks validate the efficiency of the proposed algorithm.
Keywords:Permutation Flow Shop Scheduling Problem, Estimation of Distribution Algorithm, Genetic Algorithm, Fuzzy Logic Controller
基于EDA-GA的置换流水车间调度算法
刘祝智,王恺
武汉大学经济与管理学院,湖北 武汉
Email: lzz_cau_whu@163.com
收稿日期:2015年2月6日;录用日期:2015年2月18日;发布日期:2015年2月26日

摘 要
置换流水车间调度问题是工业工程中经典的组合优化问题,一般采用智能优化算法来求解该问题。作为一种新颖的优化算法,分布估计算法主要使用统计学习的方法指导搜索过程。然而,这种算法容易陷入到局部最优而出现过早收敛的现象。本文将分布估计算法与遗传算法结合,通过模糊逻辑控制来调节两种算法生成个体的比例。该算法有利于保持种群的多样性,避免了过早收敛。以Car类和Rec类算例进行测试,实验结果证实了本文所提出的混合算法的有效性。
关键词 :置换流水车间调度,分布估计算法,遗传算法,模糊逻辑控制

1. 前言
置换流水车间调度问题(Permutation Flow Shop Scheduling Problem,PFSP)是工业工程中经典的规划问题。它在制造系统、生产线组装和信息设备服务上都有着很重要的运用[1] 。在该问题中,有n个待加工工件需要在m台机器上进行加工,问题的目标是寻找这n个工件在机器上的加工顺序,从而使得工件的某个调度指标达到最优,最常用的指标为工件的总完工时间(makespan )最短。
PFSP最早由Johnson于1954年进行研究 [2] ,具有NP难性质 [3] 。常用的求解方法主要有数学规划,启发式方法和基于人工智能的元启发式算法 [4] 。数学规划适用于小规模问题,无法解决计算复杂性高的PFSP问题,而启发式方法求解时间虽短,但是不能保证解的质量。随着计算智能的发展,基于人工智能的元启发式优化算法成为研究的重点,目前应用得较多的算法有模拟退火算法、遗传算法、蚁群算法、粒子群算法等等。
分布估计算法(Estimation of Distribution Algorithm,EDA)是近些年来最为热门的智能优化算法之一,它是在遗传算法(Genetic Algorithm,GA)的基础上改进而来的,最初由H. Muhlenbein在1996年提出 [5] 。分布估计算法不进行交叉变异操作,而是用统计学习的方法,记录选择后的个体在解空间上的分布并建立一个概率模型,通过概率模型生成下一代个体。作为一种全新的搜索策略,分布估计算法侧重于在宏观层面上指导种群的进化,得到了学术界的广泛关注。
EDA在解空间上具有较强的搜寻能力,然而对解的开发利用不足,从而导致对问题求解时很容易出现过早收敛的现象,尤其是在处理高维优化问题时 [6] [7] 。对此,学术界提出了解决方法,包括提高EDA在运行时种群中个体的多样性、改进概率模型生成个体的机制以及将EDA与其他优化算法结合等等 [7] 。本文将设计一种EDA与GA结合的混合算法来求解PFSP问题,混合算法通过EDA的概率模型和GA的交叉变异操作两种方式来生成个体,并引入模糊控制理论 [8] 来自适应调节两种算法生成个体的比例。
2. 置换流水车间调度问题
PFSP问题有如下规定:
1) n台工件在m台机器上加工
2) 每个工件以相同的顺序在m台机器上加工
3) 每个工件在每台机器上的加工时间是预先确定的
4) 每台机器只能同时加工一个工件
令 代表所有工件,
代表所有工件,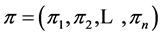 为一个待加工工件的排列,其中
为一个待加工工件的排列,其中
 ,则以总完工时间最短为优化目标的PFSP数学模型描述如下:
,则以总完工时间最短为优化目标的PFSP数学模型描述如下:

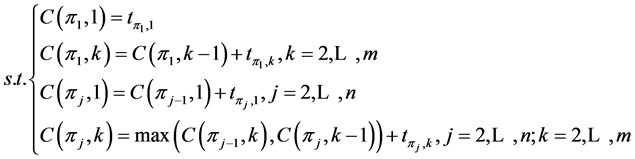
其中,m表示机器数,n表示工件数,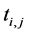 为工件
为工件 在机器
在机器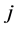 的加工完成时间。
的加工完成时间。
3. 算法设计
3.1. 种群初始化
种群包括PS个个体,初始时利用经典的NEH [9] 算法产生1个个体,采用随机初始化的方法生成PS-1个个体,以充分利用解空间的分布信息。
3.2. 选择
根据事前确定的加工时间表计算出所有个体的总完工时间 ,显然
,显然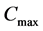 越小个体的质量就越好,据此可将评价个体好坏的适应度函数(fitness function)设为
越小个体的质量就越好,据此可将评价个体好坏的适应度函数(fitness function)设为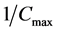 。使用轮盘赌法(Roulette Wheel Selection)对个体进行选择,每个个体被选择的概率大小与其适应度值正相关,某个体的总完工时间越短,相应的
。使用轮盘赌法(Roulette Wheel Selection)对个体进行选择,每个个体被选择的概率大小与其适应度值正相关,某个体的总完工时间越短,相应的 越小,其适应度值就越高,该个体被选中的概率也就越大。
越小,其适应度值就越高,该个体被选中的概率也就越大。
3.3. 概率模型
概率模型是EDA的核心,它指导着EDA在解空间上的搜索,概率模型一般为 矩阵
矩阵 [10] ,
[10] , 代表工件
代表工件 在解的第
在解的第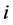 位上或之前出现的概率,初始时
位上或之前出现的概率,初始时 ,之后每一次迭代后
,之后每一次迭代后 计算公式如下:
计算公式如下:
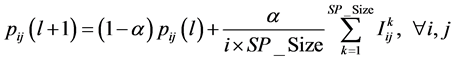
 为设置的概率模型的学习速率,
为设置的概率模型的学习速率, 代表第k个个体的如下特征
代表第k个个体的如下特征

3.4. 局部搜索
对概率模型采样即可得到新一代的个体,对个体进行局部搜索可以提高EDA的性能 [11] ,为了减少计算开销,本文将对较好的个体进行局部搜索,分别有如下三种搜索方法:
插入:选择一个工件并随机插入到某一位置
交换:随机选择两个工件并交换其所在位置
倒置:随机选择两个工件,将这两个工件之间的序列反转
3.5. 交叉算子
本文采用的交叉算子为次序保留交叉(order preserved crossover)。例如,亲代个体为{2, 3, 5, 1, 4, 9, 8, 6, 7, 10}和{1, 2, 4, 5, 6, 7, 8, 3, 9, 10},在交叉过程中保留的片段为{4, 9, 8, 6},则生成的子代个体为{1, 2, 5, 7, 4, 9, 8, 6, 3, 10} 和 {2, 3, 4, 5, 6, 1, 8, 7, 9, 10},如图1所示。
3.6. 变异算子
本文选取的变异算子为移码变异(shift move mutation),例如,变异前的个体为{6, 8, 9, 10, 7, 4, 3, 1, 2, 5},选择7, 8这两个位点进行变异,变异后个体为{6, 9, 10, 7, 8, 4, 3, 1, 2, 5},如图2所示。
3.7. 模糊逻辑控制
混合算法中EDA和GA生成个体的比例是影响算法性能的关键,传统的算法比例混合方法主要包括固定比例和动态比例两种。使用固定比例时,比例值将在整个算法搜索过程中保持不变。这种方法需要进行试验来确定合适的比例值,其缺点在于为寻找到最佳比例值所需进行的试验多,耗时久。而动态比例调节则只需预先确定一个比例的初始值,而在运行过程中会根据搜索情况调节比例。调节方式又可以分为两种:一种是应用传统的启发式规则控制算法生成个体的比例,这些规则可以用确定的数学公式表示;而另一种是用人工智能技术自适应调整生成个体的比例,最常见的是将模糊逻辑应用于比例调节,能根据算法性能的变化来实现比例控制 [12] 。为了使混合算法具有优良的适应性,本文采用模糊逻辑控制来进行比例调节:在EDA表现良好时提高EDA生成个体的比例发挥其全局搜索的优势,在EDA求得解的质量下降时提高GA生成个体的比例,以避免出现局部最优。
模糊逻辑控制 [8] [13] [14] 的步骤如下:
1) 计算出种群中全部个体的总完工时间平均值 ,令
,令 ,
, 。
。
2) 将 ,
, 标准化至
标准化至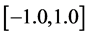 ,所使用的公式如下:
,所使用的公式如下:

3) 根据隶属度函数(membership function,见图3)将标准化后的 ,
, 进行模糊处理。
进行模糊处理。
(NR是negative larger缩写,NL为negative large,NM为negative medium,NS为negative small,ZS为zero,PS为positive small,PM为positive medium,PL为positive large,PR为positive larger)。
4) 得到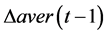 ,
,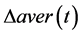 的模糊值后结合模糊判断规则(fuzzy decision table,见表1)确定模糊输出量
的模糊值后结合模糊判断规则(fuzzy decision table,见表1)确定模糊输出量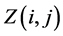 。
。
5) 利用输出量 的隶属度函数(见图4)和去模糊化规则(defuzzification table,见表2)确定最终EDA生成个体的比例的变化量
的隶属度函数(见图4)和去模糊化规则(defuzzification table,见表2)确定最终EDA生成个体的比例的变化量 ,则下一代EDA所生成个体的比例为
,则下一代EDA所生成个体的比例为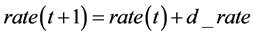 。
。
(NR是negative larger缩写,NL为negative large,NM为negative medium,NS为negative small,ZS为zero,PS为positive small,PM为positive medium,PL为positive large,PR为positive larger)。

Figure 1. Order preserved crossover
图1. 次序保留交叉

Figure 2. Shift move mutation
图2. 移码变异

Figure 3. Membership function for inputs
图3. 输入量的隶属度函数

Figure 4. Membership function for outputs
图4. 输出量的隶属度函数

Table 1. Fuzzy decision table
表1. 模糊判断规则
Table 2. Defuzzification table
表2. 去模糊化规则
4. EDA-GA混合算法
EDA-GA混合算法步骤如下:
1) 种群和概率模型的初始化
产生初始种群,迭代次数t = 1,概率模型 中
中
2) 对种群个体进行评价并选择出优势个体
以轮盘赌法选择出用以更新EDA概率模型的优势个体和待进行交叉变异操作的父代个体
3) 更新概率模型并对概率模型取样生成个体
对优势个体进行统计学习完成概率模型的更新,然后对概率模型抽样产生PS个个体,局部搜索后,把最好的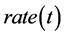 *PS个个体加入到下一代种群,
*PS个个体加入到下一代种群,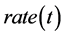 为当前EDA所生成个体的比例
为当前EDA所生成个体的比例
4) 交叉操作和变异操作
对父代分别进行交叉操作和变异操作,共产生 *PS个个体,将这些个体加入到下一代种群中
*PS个个体,将这些个体加入到下一代种群中
5) 模糊逻辑控制调节比例
新一代种群生成后,将种群平均完工时间与上一代进行比较,得到模糊输入量,根据模糊判断规则确定下一次迭代时EDA所生成个体的比例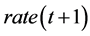
6) 终止条件判断
若满足终止条件,输出此时得到的最优解;否则,t = t + 1,进入步骤2)。
5. 实验结果
5.1. 参数设置
将EDA-GA混合算法的参数设为种群大小PS = 200,迭代次数iteration_times = 300,优势个体所占比例为superior_rate = 0.2,GA变异比例mutation_rate = 0.1,EDA初始生成个体的比例rate = 1,概率模型学习速率 。
。
5.2. 结果分析
为验证混合算法的效果,本文选用OR-library中的Car1~Car8,Rec01~Rec41,共29个算例来进行测试,每个算例用matlab在计算机上独立运行10次,并与GA,EDA的结果进行比较。测试结果如表3
Table 3. Computational results for benchmarks
表3. 算例仿真结果
所示。其中, 、
、 为每种算法求得的最优解
为每种算法求得的最优解 与三种算法测试所得的最好解
与三种算法测试所得的最好解 的相对偏差百分比的最小值和平均值。
的相对偏差百分比的最小值和平均值。
从表3的实验结果可以看出,对测试问题Car1~Car8和Rec01~Rec37,本文设计的EDA-GA混合算法ARE与BRE均优于EDA和GA,说明GA的引入使得EDA的优化性能有了很大的改进。对于Rec39、Rec41,混合算法BRE不如GA,说明优化性能稍弱于GA,但相比EDA解的质量有显著提高。因此总体而言,EDA-GA混合算法的性能是要强于GA和EDA。
6. 结论
本文设计了一种EDA-GA混合算法对以最小化总完工时间为优化目标的PFSP问题进行了求解。针对EDA容易过早收敛的缺点,将EDA和GA各自生成一定比例的个体进行混合,并用模糊逻辑控制的方法对比例进行自适应调节。模糊输入量为种群个体总加工时间的平均值的变化,模糊输出量为EDA在下一次迭代中所生成个体的比例。混合算法既利用了EDA全局搜索能力强的优势,又弥补了EDA局部搜索能力弱的缺陷,相比遗传算法也提高了搜索能力。算例仿真的结果证明上述EDA-GA混合算法是有效的。
致谢
本工作受国家自然科学基金项目(71301124)、教育部人文社会科学一般项目(13YJC630165),博士点新教师基金项目(20130141120071)的资助。
文章引用
刘祝智,王 恺, (2015) 基于EDA-GA的置换流水车间调度算法
A Hybrid EDA with GA for the Permutation Flow Shop Scheduling Problem. 运筹与模糊学,01,6-13. doi: 10.12677/ORF.2015.51002
参考文献 (References)
- 1. Pan, Q.-K., Suganhan, P.N., Tasgetiren, M.F. and Chua, T.J. (2011) A discrete artificial bee colony algorithm for the lot-streaming flow shop scheduling problem. Information Sciences, 181, 2455-2468.
- 2. Johnson, S.M. (1954) Op-timal two-and three-stage production schedules with setup times included. Naval Research Logistics Quarterly, 1, 61-68.
- 3. Zhang, Y. and Li, X. (2011) Estimation of distribution algorithm for permutation flow shops with total flow time minimization. Computers & Industrial Engineering, 60, 706-718.
- 4. 周驰, 高亮, 高海兵 (2006) 基于 PSO 的置换流水车间调度算法. 电子学报, 34, 2008-2011.
- 5. Larranaga, P. and Lozano, J.A. (2002) Estimation of distribution algorithms: A new tool for evolutionary computation. Springer, Berlin.
- 6. 叶宝林, 高慧敏, 王筱萍, 等 (2011) 基于分布估计算法的二阶段置换流水车间调度算法. 计算机应用研究, 10, 3702-3706.
- 7. Chen, S.H., Chen, M.C., Chang, P.C., et al. (2010) Guidelines for developing effective estimation of distribution algorithms in solving single machine scheduling problems. Expert Systems with Applications, 37, 6441-6451.
- 8. Chan, F.T.S., Prakash, A. and Mishra, N. (2013) Priority-based scheduling in flexible system using AIS with FLC approach. Interna-tional Journal of Production Research, 51, 4880-4895.
- 9. Nawaz, M., Enscore Jr., E.E. and Ham, I. (1983) A heu-ristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega, 11, 91-95.
- 10. 王圣尧, 王凌, 许烨, 等 (2012) 求解混合流水车间调度问题的分布估计算法. 自动化学报, 3, 437-443.
- 11. Wang, S., Wang, L., Liu, M., et al. (2013) An effective estimation of distribution algorithm for solving the distributed permutation flow-shop scheduling problem. International Journal of Production Economics, 145, 387-396.
- 12. 何宏, 钱锋 (2006) 遗传算法参数自适应控制的新方法. 华东理工大学学报(自然科学版), 5, 601-606.
- 13. Kim, K.W., Gen, M. and Yamazaki, G. (2003) Hybrid genetic algorithm with fuzzy logic for resource-constrained project scheduling. Applied Soft Computing, 2, 174-188.
- 14. Kim, K.W., Yun, Y.S., Yoon, J.M., et al. (2005) Hybrid genetic algorithm with adaptive abilities for resource-con- strained multiple project scheduling. Computers in Industry, 56, 143-160.