Advances in Applied Mathematics
Vol.06 No.02(2017), Article ID:19924,13
pages
10.12677/AAM.2017.62013
A Finite Difference Parallel Scheme Based on MPI Implementation for Fourth Order Parabolic Equations
Yuyang Gao, Haiming Gu
Qingdao University of Science and Technology, Qingdao Shandong

Received: Feb. 27th, 2017; accepted: Mar. 18th, 2017; published: Mar. 21st, 2017

ABSTRACT
Parallel computing can save a lot of time in the field of large-scale scientific computing. In this paper, the main idea is that a finite difference parallel scheme for fourth order parabolic equations. The scheme is constructed by Saul’yev asymmetric difference schemes which called the four-point scheme. It’s one explicit difference scheme, the computational domain can be divided into a number of large areas; each sub-region computes themselves, and the parallel scheme is unconditionally stable. Then, the paper focuses on the numerical calculation of the four-point scheme in MPI parallel environment. Two different MPI parallel algorithms are constructed, one is blocking com- munication (wait communication) mode, and the other is non-blocking communication (non-wait communication) mode. These two parallel algorithms both better than serial algorithm to calculate numerical solutions use four-point scheme, and the non-blocking communication mode is higher computational than the other, because the wait time in non-blocking communication mode is less than blocking communication mode.
Keywords:Fourth Order Parabolic Equations, Finite Difference Parallel Scheme, MPI (Message Passing Interface)
基于MPI的一种有限并行差分格式求解四阶抛物方程
高玉羊,顾海明
青岛科技大学,山东 青岛
收稿日期:2017年2月27日;录用日期:2017年3月18日;发布日期:2017年3月21日

摘 要
在大规模的科学与工程计算问题中,并行计算能够节省大量的时间,本文针对一维四阶抛物方程给出了一类并行差分格式。利用Saul’yev非对称格式进行恰当的组合,形成求解抛物方程的四点格式。四点格式是显式求解的,因此可以将空间区域分为若干子区域,每个子区域独立计算。验证分析表明,该格式是绝对稳定的。随后本文着重介绍了在MPI并行环境下对该格式进行数值计算,构建了两种不同的MPI并行算法并与串行状态下的有限差分格式做出比较,即阻塞通信(等待通信)和非阻塞通信(非等待通信)模式。相对于串行算法运用四点格式求解四阶抛物方程,两种并行通信模式都表现出极好的效果,而且,非阻塞通信模式下的计算由于相对减少了一部分数据的通信等待时间,使得相对于阻塞通信模式,非阻塞通信模式表现出较好的并行效率。
关键词 :四阶抛物方程,有限并行差分法,Message Passing Interface

Copyright © 2017 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
在自然科学和工程技术领域中,尤其是以物理学、化学、生物学等为主的学科引领了现代科学技术的快速发展,而这些学科自身的精确化又是他们取得进展的重要保证。其中,很多问题可以描述为偏微分方程或方程组的形式,因此,运用有限差分方法数值求解偏微分方程问题具有很多重要的理论意义与应用价值。
随着科学计算问题的规模不断扩大,并行计算越来越受到人们的重视,其中,高性能并行计算机的快速发展也促进了偏微分方程并行数值算法的研究。MPI是当今最重要的并行编程工具之一,MPI是一个信息传递应用程序接口,包括协议和语义说明,MPI的目标是高性能,大规模性,和可移植性。大部分的MPI实现由一些指定惯例集(API)组成,可由C,C++,Fortran,或者有此类库的语言比如C#, Java or Python直接调用。MPI优于老式信息传递库是因为他的可移植性和速度。MPI为并行算法提供了多种通信模式,其中,一般的阻塞通讯(等待通讯)模式即可满足大多数并行算法,非阻塞通讯(非等待通讯)相对减少了各并行模块之间的通讯时间,从而使得并行计算模式的效率得到提升。
关于求解二阶抛物偏微分方程的并行差分格式,已经有了很多的研究(文献 [1] ),D. J. Evans和A. R. Abdullah在文献 [2] 中巧妙的利用Saul’yev非对称格式(文献 [3] )构造了交替分组显式(AGE)方法,以及在近年来,Evans等陆续基于AGE方法经过变换扩展到其他方面(见文献 [4] , [5] , [6] )。在文献 [7] 中,作者运用分组显式的方法求解了四阶椭圆方程,并应用于MPI并行计算。文献 [8] , [9] 中,作者改进了AGE方法,得到交替分段方法,使数值结果更加精确。实际上,四阶抛物偏微分方程相对于二阶方程的求解有更大的困难,一般的显式格式的稳定性条件比二阶抛物方程更加苛刻,一般四阶抛物方程的隐格式形成的代数方程组的系数矩阵比二阶方程占据更大运算空间,因此,四阶抛物方程在数值求解的规模上要远远大于二阶方程。
本文在探究四阶抛物方程的并行有限差分格式时,主要借鉴于求解二阶抛物方程的差分方法,运用不同类型的Saul’yev非对称格式进行恰当的组合,对少部分点的求解形成代数方程组,从而构造出方程的显式差分格式,由于显式格式不必要求规模庞大的代数方程组,因而可以适用于并行计算。单独使用一种非对称差分格式会使误差偏上或偏下(文献 [10] ),因此在时间层上交替的使用不同的非对称格式,可以使每层产生的误差抵消,从而使方程数值解的精度得到提高。
2. 四阶抛物方程的非对称差分格式
考虑如下四阶抛物方程以及初边值问题,
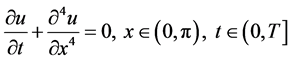 (1)
(1)
 (2)
(2)
 (3)
(3)
建立差分格式之前,不妨设 为精确解。对求解区域
为精确解。对求解区域 进行网格剖分,空间步长为
进行网格剖分,空间步长为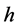 ,时间步长为
,时间步长为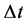 。
。 ,
, ,其中
,其中 ,
,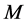 是自然数。
是自然数。


将求解区域分割成矩形网格,网格节点为 ,为方便起见,记
,为方便起见,记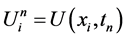 为节点处的值。将
为节点处的值。将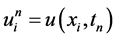 记为初边值问题(1),(2),(3)在网格节点
记为初边值问题(1),(2),(3)在网格节点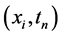 的数值解,
的数值解,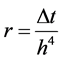 为网格比。
为网格比。
2.1. 四阶抛物方程的显格式
易知,

方程(1)可以写成下面的形式
 (4)
(4)
将二阶差商化为一阶得

用 代替
代替 ,舍弃无穷小项化简后可以得到
,舍弃无穷小项化简后可以得到
 (5)
(5)
运用Fourier方法可以证明四阶抛物方程的显式格式是条件稳定的,此处不再赘述,稳定性条件是 ,截断误差为
,截断误差为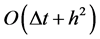 。
。
2.2. 四阶抛物方程的隐格式
易知,
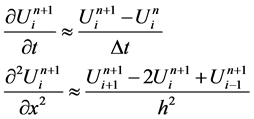
方程(1)可以写成如下形式
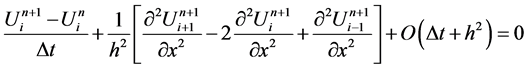 (6)
(6)
舍弃无穷小,用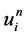 代替
代替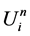 ,化简后得到
,化简后得到
 (7)
(7)
可以证明四阶方程的隐式格式是绝对稳定的,且局部截断误差为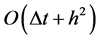 。
。
2.3. 四阶抛物方程的非对称格式
由中值定理可以得到,
 (8)
(8)
 (9)
(9)
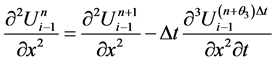 (10)
(10)
 (11)
(11)
其中, ,
, 。
。
类似于二阶抛物方程的非对称差分格式的构造(文献 [3] ),尝试构造四阶抛物方程的非对称差分格式,将(8)代入方程(4),可以得到
 (12)
(12)
舍去无穷小项 和
和 ,得到网格方程
,得到网格方程
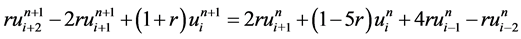 (13)
(13)
即得到四阶抛物方程的一个非对称差分格式。
运用同样的方法,分别将(9),(10),(11)代入等式(6),(4),(6),可以得到
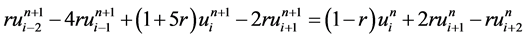 (14)
(14)
 (15)
(15)
 (16)
(16)
上述四个非对称网格方程的局部截断误差为 。
。
利用方程(13)~(16)可以构造出求解方程(1)的显式四点格式,即将其联立,可以得到一组差分方程
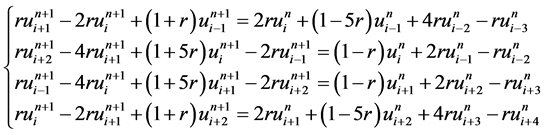 (17)
(17)
四点格式所涉及到的网格节点如图1所示。
可以将方程组(17)写成矩阵的形式,如下
 (18)
(18)
为了求解初边值问题(1),(2),(3),假设网格的剖分节点是 (
( 是自然数),则内部节点数为
是自然数),则内部节点数为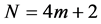 。因此共有
。因此共有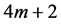 个需要计算的内点,共有
个需要计算的内点,共有 个四点组使用方程组(17)计算,可以明显的看到,还有两个单独的内点无法使用四点方法计算,可以考虑将两个内点放在计算区域的最左端或者最右端,使用方程(13)和(16)处理右边界临近的内点,方程(14),(15)处理左端边界临近的内点,这两种不同的方法与四点方法组合可以得到一种新的方法。
个四点组使用方程组(17)计算,可以明显的看到,还有两个单独的内点无法使用四点方法计算,可以考虑将两个内点放在计算区域的最左端或者最右端,使用方程(13)和(16)处理右边界临近的内点,方程(14),(15)处理左端边界临近的内点,这两种不同的方法与四点方法组合可以得到一种新的方法。

Figure 1. Points of four-point method
图1. 四点格式涉及节点
考虑右边界的两点格式,
 (19)
(19)
将初边值条件,即 ,
, 代入上式,可得
代入上式,可得
 (20)
(20)
同理,考虑左边界的两点格式,得到方程组
 (21)
(21)
2.4. GER和GEL格式
当临近右边界的两点采用两点格式(20),其余内点采用四点格式,即可得到右端分组显式(GER)格式。写成矩阵的形式为
 (22)
(22)

与GER格式相似,在临近左边界的两个内点采用方程(21),其余内点可以分成 个四点组,使用方程组(17)计算,可以得到左端分组显式(GEL)格式,方程如下,
个四点组,使用方程组(17)计算,可以得到左端分组显式(GEL)格式,方程如下,
 (23)
(23)
下面对GER格式进行稳定性分析。
Kellogg引理(文献 [10] ):设 ,如果
,如果 为非负定实阵,即满足
为非负定实阵,即满足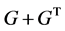 非负定,则
非负定,则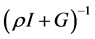 存在,且
存在,且 。
。
在上述引理条件下,可以得到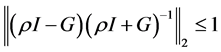 。
。
方程(22),(23)可以写成 的形式,
的形式, 。因
。因 为非负定矩阵,可以得到
为非负定矩阵,可以得到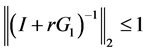 。再由
。再由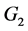 的对称性以及特征值与范数的关系可以得到,
的对称性以及特征值与范数的关系可以得到,
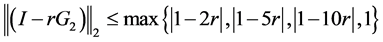
所以,只要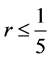 ,就能得到
,就能得到 。因此,GER或者GEL格式是条件稳定的,稳定条件为
。因此,GER或者GEL格式是条件稳定的,稳定条件为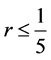 。
。
条件稳定的局限性并不能满足高效的求解微分方程,因此,在下面给出了分层交替方法,使稳定性得到本质的改善。
2.5. 分组交替方法(AGE方法)
考虑上述的GER和GEL格式,在不同的时间层上分别交替的使用两种格式,写成方程组的形式为
 (24)
(24)
其中 ,
,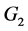 已在上文中定义,增长矩阵为
已在上文中定义,增长矩阵为
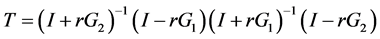
利用Kellogg引理,容易得到
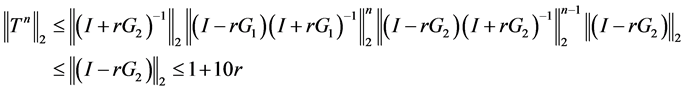
即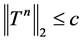 ,
, ,即可以得到,四阶抛物方程的分层交替方法是绝对稳定的。
,即可以得到,四阶抛物方程的分层交替方法是绝对稳定的。
3. MPI并行算法
在本文中,所涉及到的并行算法都是基于上文中给出分组交替方法,GER方法,GEL方法实现的,在并行计算之前,首先,将求解区域 划分为若干大的区域,例如,若将抛物方程(1)进行4进程并行计算,则将求解区域分割成四条带状的区域,每个进程负责一条带状计算区域,并在时间层上逐次计算。为了实现高效计算,比较适宜的做法是为每一条进程分配大约相等的任务量,即保证在空间方向上分割的带状区域大小几乎是一致的。在进行每一时间层上的计算时,每两两相邻进程之间进行数据通信,当前时间层上的通信与计算完毕后,即进入下一时间层的计算。下文中,给出了两种不同的通信模式,即阻塞通信与非阻塞通信。一般情况下,这两种通讯模式即可满足大多数的并行计算任务。然后针对上文中论述的多种显示差分方法构造了相适应的并行处理框架,随后对其进行了并行运算。阻塞通信模式流程如表1所示。
划分为若干大的区域,例如,若将抛物方程(1)进行4进程并行计算,则将求解区域分割成四条带状的区域,每个进程负责一条带状计算区域,并在时间层上逐次计算。为了实现高效计算,比较适宜的做法是为每一条进程分配大约相等的任务量,即保证在空间方向上分割的带状区域大小几乎是一致的。在进行每一时间层上的计算时,每两两相邻进程之间进行数据通信,当前时间层上的通信与计算完毕后,即进入下一时间层的计算。下文中,给出了两种不同的通信模式,即阻塞通信与非阻塞通信。一般情况下,这两种通讯模式即可满足大多数的并行计算任务。然后针对上文中论述的多种显示差分方法构造了相适应的并行处理框架,随后对其进行了并行运算。阻塞通信模式流程如表1所示。
考虑问题(1) (2) (3),如上文,网格划分后,单一时间层上的内部节点数为 (即
(即 ),通过合适的划分网格,可以选择不同数目的进程进行计算,不失一般性,对上述三种差分格式考虑在4条进程下完成计算。首先,将整个求解区域大约的划分为四个部分,考虑GEL格式,在进程0中,前两个内部节点使用方程组(21)计算,进程0的其他内点以及其他进程的内部节点使用方程(17)计算。由于各相邻进程之间需要数据通信,此处以0号进程与1号进程之间的通信传递说明,不妨假设已知第
),通过合适的划分网格,可以选择不同数目的进程进行计算,不失一般性,对上述三种差分格式考虑在4条进程下完成计算。首先,将整个求解区域大约的划分为四个部分,考虑GEL格式,在进程0中,前两个内部节点使用方程组(21)计算,进程0的其他内点以及其他进程的内部节点使用方程(17)计算。由于各相邻进程之间需要数据通信,此处以0号进程与1号进程之间的通信传递说明,不妨假设已知第 层上的数据,求解第
层上的数据,求解第 层上的数据,
层上的数据, 层上的动作:进程0右端的两个点的数据发送至进程1,进程1左
层上的动作:进程0右端的两个点的数据发送至进程1,进程1左

Table 1. The step of blocking communication mode
表1. 阻塞通信模式下并行详细步骤
端的两内点数据发送至进程0。 层上的动作:进程0和进程1接收来自对方的数据,并运用于计算。其他进程之间的通讯也是如此,通信模式简图见图2。
层上的动作:进程0和进程1接收来自对方的数据,并运用于计算。其他进程之间的通讯也是如此,通信模式简图见图2。
在使用GER格式计算的情况下,与GEL格式类似,两点组的内部节点由最后一个进程计算,即最右端进程的最右端的两个内部节点由方程组(21)计算,其他内部节点由四点方法进行计算。与GEL格式一致,相邻进程的附近节点进行数据通信,见图3。
在使用分组交替格式计算的情况下,与GER,GEL格式有些不同之处,首先考虑在时间层第 层使用GEL格式,第
层使用GEL格式,第 层使用GER格式,第
层使用GER格式,第 层上的通讯与计算与普通的GEL格式一样,在进行第
层上的通讯与计算与普通的GEL格式一样,在进行第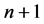 时间层上的GER格式的计算时,在
时间层上的GER格式的计算时,在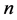 层上,相邻两个进程的最初与最后四个内部节点的数据分别向前一个进程与后一个进程发送。通讯简图如图4所示。
层上,相邻两个进程的最初与最后四个内部节点的数据分别向前一个进程与后一个进程发送。通讯简图如图4所示。
在MPI并行环境下,阻塞通信模式下用到的计算与通讯过程中的命令,如下,
MPI_Send(void* buf,int count,MPI_Datatype,int destination,int tag,MPI_Comm comm)
MPI_Recv(void* buf,int count,MPI_Datatype,int source,int tag,MPI_Comm comm, MPI_Status*status)
非阻塞通信模式下三种差分格式的通信和计算与阻塞通信模式下的基本一致,差异之处在于各个进程之间的通讯可能尚未结束时,就已经在进行数据的计算,这样往往可以使CPU在各个核心在通讯的过程中,仍然满载运行,从而减少程序运行的时间,达到并行计算效率的提升。但非阻塞通讯同样带来程序实现成本的上升。非阻塞通信模式流程如表2所示。
在MPI并行环境下,非阻塞通信模式下用到的计算与通讯过程中的命令,如下
MPI_Isend(void* buf,int count,MPI_Datatype,int destination,int tag,MPI_Comm comm, MPI_Request*request)
MPI_Irecv(void* buf,int count,MPI_Datatype,int source,int tag,MPI_Comm comm, MPI_Request*request)
MPI_Waitall(int count,MPI_Request*request,MPI_Status*status)
4. 数值并行计算
为了验证分层交替格式的稳定性及误差情况,以及并行效率的提升情况。作如下数值运算。对方程(1),考虑初始条件, 为初值,此时,问题(1)的精确解为
为初值,此时,问题(1)的精确解为 。
。
表3为 所给出的近似解及误差情况,
所给出的近似解及误差情况, 为绝对误差,
为绝对误差, 为相对误差,
为相对误差,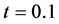 为最终计算时间。
为最终计算时间。
下文中给出的数值计算结果是在ACER双核四线程计算机,处理器i3-2350M进行并行计算,定义内部节点数为40002,时间层为2000,时间步长 ,针对分组交替格式,分别给出了在1、2、4、
,针对分组交替格式,分别给出了在1、2、4、
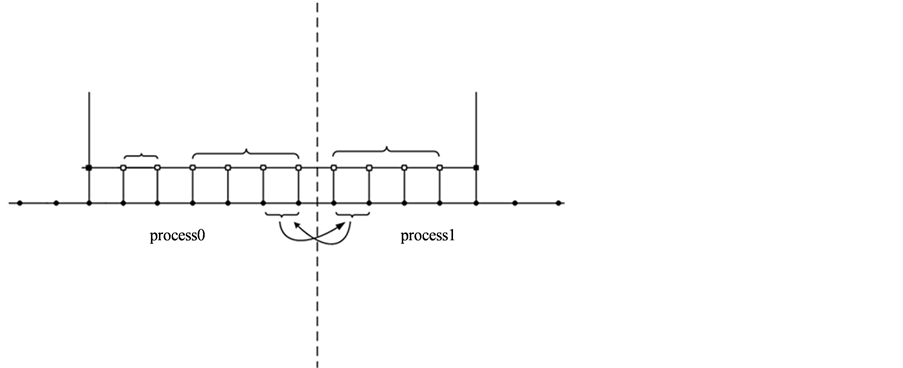
Figure 2. Communication mode of GEL
图2. GEL格式通讯简图

Figure 3. Communication mode of GER
图3. GER格式通讯简图

Figure 4. Communication mode of AGE
图4. AGE格式通讯简图
Table 2. The step of non-blocking communication mode
表2. 非阻塞通信模式下并行详细步骤
Table 3. The comparison of exact solution and approximate solution
表3. 数值解与解析解及误差对比
8条进程下的程序运行时间,在多核并行运算的程序中,也给出了阻塞通信模式与非阻塞通信模式的时间效率的对比,并以图表的方式给予了清晰的展示。非阻塞通信相对于阻塞通信来说,并未改变算法的逻辑结构,非阻塞通信只是降低了通信过程中消息传递的成本,因此阻塞通信与非阻塞通信在最终数值结果上是一致的。表4~7展现了不同进程数目下的并行运算时间。表8给出不同进程数目下的并行加速比。图5~7展示了表4中时间数据的柱状图,使并行效率得到了更清晰的展示。
5. 总结
在上述数值模拟计算的数据表格中,可以看出多条进程下,运用分组交替格式数值计算四阶抛物方程要比一个进程拥有更快的效率,多次试验数据表明,2条进程运算时间约是1条进程的1/2,4条进程运算时间约是1条进程的1/3,8条进程运算的时间约是一条进程的1/3,可以看到,随着进程数量的增多,程序运算的时间并没有随之线性下降,可以在表7中看到,在程序运行中,大量的时间用于各个进程之间的通信,从而导致计算效率相对于4条进程执行并未得到明显的提高。产生这种问题的原因一方面是由于进程总数过多,导致各个进程之间的通讯变得复杂。另一方面的原因是进程总数超过了计算机CPU的硬件核心总数,一个核心不再单独的只负责一个进程。所以,要达到完美的并行效果,就尽量要求进程总数与并行计算系统的计算核心总数相持平或小于CPU核心数。
Table 4. The executive time of 4 processes in blocking and non-blocking communication mode (sec.)
表4. 4进程阻塞通信与非阻塞通信模式的程序运算时间比较(单位/秒)
Table 5. The executive time of 2 processes in blocking and non-blocking communication mode for AGE scheme (sec.)
表5. AGE格式下2进程阻塞通信与非阻塞通信模式的程序运算时间比较(单位/秒)
Table 6. The executive time of 8 processes in blocking communication mode for AGE scheme (sec.)
表6. AGE格式下8进程阻塞通信程序运算时间(单位/秒)
Table 7. The executive time of 8 processes in non-blocking communication mode for AGE scheme (sec.)
表7. AGE格式下8进程非阻塞通信程序运算时间(单位/秒)
Table 8. Comparison of the parallel efficiency in different processes
表8. 不同进程数下并行效率比较

Figure 5. The executive time of single process and 4 processes of AGE blocking communication program
图5. AGE阻塞通信模式下四进程并行计算与单进程计算的计算时间柱状图

Figure 6. The executive time of single process and 4 processes of AGE non-blocking communication program
图6. AGE非阻塞通信模式下四进程并行计算与单进程计算的计算时间柱状图
在表4~7与图7中,可以看到非阻塞通信相对于阻塞通信模式的优势。以4条进程运算为例,非阻塞通信程序的总时间相对于阻塞通信程序的总时间是减少的。在信息传递过程中,当数据发送操作已完成,非阻塞通信模式即开始数据的计算,阻塞通信模式需要等待各个进程间的通信完成,因而,非阻塞通信降低了程序的运算时间。在表8和图5,图6中,可以看到,多进程计算相当于单进程计算时是极有优势的。在表8中,随着进程总数的增加,加速比是不断提高的,但并行的效率却逐渐下降,这也从

Figure 7. The time of AGE blocking and non-blocking communication program in 4 processes
图7. 四进程下AGE阻塞通信模式与非阻塞通信模式下时间柱状图
侧面论证了进行多进程并行运算时,要选择恰当的进程总数。在表8中,还可以看到非阻塞通信相对于阻塞通信的优势,即在相同的进程数目下,无论是加速比还是并行效率,非阻塞通信都要高于阻塞通信。
文章引用
高玉羊,顾海明. 基于MPI的一种有限并行差分格式求解四阶抛物方程
A Finite Difference Parallel Scheme Based on MPI Implementation for Fourth Order Parabolic Equations[J]. 应用数学进展, 2017, 06(02): 114-126. http://dx.doi.org/10.12677/AAM.2017.62013
参考文献 (References)
- 1. Vabishchevich, P.N. (2015) Explicit Schemes for Parabolic and Hyperbolic Equations. Applied Mathematics and Com- putation, 250, 424-431.
- 2. Evans, D.J. and Abdullah, A.R. (1983) Group Explicit Methods for Parabolic Equations. International Journal Computer Mathematics, 14, 73-105. https://doi.org/10.1080/00207168308803377
- 3. Saul’yev, V.K. (1965) Integration of Equations of Parabolic Type by the Method of Nets. Proceedings of the Edinburgh Mathematical Society, 14, 247-248. https://doi.org/10.1017/S0013091500008890
- 4. Evans, D.J. and Abdullah, A.R. (1985) A New Explicit Method for the Diffusion-Convection Equation. Computers and Mathematics with Applications, 11, 145-154.
- 5. Abdullah, A.R. (1991) The Four Point Explicit Decoupled Group (EDG) Method: A Fast Poisson Solver. International Journal of Computer Mathematics, 38, 61-70. https://doi.org/10.1080/00207169108803958
- 6. Evans, D.J. (1985) Alternating Group Explicit Method for the Diffusion Equations. Applied Mathematical Modelling, 9, 201-206.
- 7. Ali, M., Hj, N., Teong, K. and Khoo (2010) Numerical Performance of Parallel Group Explicit Solvers for the Solution of Fourth Order Elliptic Equations. Applied Mathematics and Computation, 217, 2737-2749.
- 8. Zhang, B.L. and Li, W.Z. (1994) One Alternating Segment Crank-Nicolson Scheme. Parallel Computing, 20, 897-902.
- 9. 张宝琳. 求解扩散方程的交替分段显–隐式方法[J]. 数值计算与计算机应用, 1991(4): 245-253.
- 10. Kellogg, R.B. (1964) An Alternating Direction Method for Operator Equations. Journal of the Society of Industrial and Applied Mathematics, 12, 7. https://doi.org/10.1137/0112072