 Hans Journal of Data Mining 数据挖掘, 2012, 2, 1-5 http://dx.doi.org/10.12677/hjdm.2012.21001 Published Online January 2012 (http://www.hanspub.org/journal/hjdm) Recognization of Blood Odor Based on Stepwise Discrimination Analysis* Chengsheng Long, Xin Wang, Dehua Wu#, Huidong Zhang, Jingning Qiang Nanjing Police Dog Research Institute of Public Security Ministry, Nanjing Email: {#jqswdh, longchengsheng}@163.com Received: Nov. 4th, 2011; revised: Dec. 8th, 2011; accepted: Dec. 15th, 2011. Abstract: A model for recognization of blood odor based on stepwise discrimination analysis was established and the features come from the chromatographs of blood samples. The model was described in detail and its code was compiled by means of Matlab. The human blood and animal blood samples were used to train and test the model, which d etailed the usage of the model. The results demonstrated that samples from different species could be distinguished. Keywords: Pattern Recognization; Blood Odor; Stepwise Discrimination Analysis; Matlab 基于逐步判别分析的血液气味识别* 龙成生,王 辛,吴德华#,张汇东,强京宁 公安部南京警犬研究所,南京 Email: {#jqswdh, longchengsheng}@163.com 收稿日期:2011 年11 月4日;修回日期:2011 年12 月8号;录用日期:2011 年12 月15 日 摘 要:本文以血液气味色谱为基础,利用逐步判别分析法建立了血液气味识别模型,并对血液气味识别模型 的建立进行了详细描述。以Matlab 为计算工具,编写了血液气味识别模型的代码。以人体血液与犬、鸡的血液 为例,讨论了血液气味识别模型的使用方法。血液气味识别模型能够正确区分人体血液与动物血液。 关键词:模式识别;血液气味;逐步判别分析;Matlab 1. 引言 血液气味是血迹搜索犬作业的物质基础。在命案 快速侦破中,血迹搜索犬发挥了快速、便捷、准确定 位等特殊作用[1,2]。在犯罪现场进行血迹搜索和血迹气 味追踪时,血迹搜索犬能迅速找出现场血迹走向和附 有血液气味的物证如凶器、血衣等。在血迹搜索犬的 训练和使用中,血迹气味的质量是影响血迹搜索犬作 业结果的关键[3,4]。有文献报道,人体血液气味与个体 的健康状况[5]和所处环境[6]有密切关系。因此,血液 气味的化学组成分析,可以揭示血迹气味的本质特 征,有利于进一步提高血迹搜索犬的训练使用水平, 提供血迹搜索犬进行气味作业的科学依据。 血迹搜索犬区分人体血液与其它血液的具体化 学成分仍不清楚。但是可以肯定,这些化学成分在不 同类别血液气味中存在差异性。研究这种差异性有利 于扩大血迹搜索犬的应用范围,也为犬的气味识别机 理的研究提供参考。模式识别(Pattern Recognition)是 通过对表征事物或现象的各种形式数值、文字和逻辑 关系信息进行处理和分析,达到对事物或现象进行描 述、辨认、分类和解释的一个过程[7]。除了图像处理[8]、 语音系统、文字识别等领域外,模式识别技术也被广 泛应用于医学[9]、化 学 [10]、生物学[11]、食 品 [12]等领域。 *资助信息:公安部应用创新项目(2011YYCXNJJQ164)。 #通讯作者。 Copyright © 2012 Hanspub 1  基于逐步判别分析的血液气味识别 本文以血液气味样品色谱图为基础,利用逐步判 别分析方法建立了血液气味识别模型,并以 Matlab 软件为计算工具编写了相关代码。利用建立的血液气 味识别模型对不同来源的血液样品进行了识别,得到 了较好结果。 2. 基于逐步判别分析的模式识别 逐步判别的基本思想:每一步选一个判别能力最 显著的自变量进入判别函数,而且在每次选变量之前 都对已经进入判别函数的诸变量逐个检验其显著性, 如果发现有某个变量由于新变量的引入而变得不重 要,即在判别函数中判别能力不显著时,就剔除这个 变量,直到差别函数中包含的所有变量判别能力都显 著时为止,其实施过程如图1所示。 3. 血液气味识别模型 3.1. 变量集的建立 在血液气味色谱图中,每一个色谱峰代表一个化 合物,每个化合物都有特定的保留时间。血液气味识 别模型的变量来自色谱图的保留时间和峰面积。 Figure 1. Stepwise discriminant analysis process 图1. 逐步判别分析流程图 3.2. 特征向量选择 逐步判别分析过程已经包括特征向量优化过程。 当然,我们可以根据经验选择待选变量作为自变量 集,也可以去除明显的非特征变量。 3.3. 逐步判别分析过程(计算过程[13]) 设变量数据为 xigk,它表示第 g类第 k个样品第 i 个变量的数值。 1) 计算分类均值 ig x 和总均值 i x : 1 1g n ig igk k g x x n , 11 1g n G ii gk gk x x N , 式中 i = 1, 2,, m,表示第 i个变量; g = 1, 2,, G, 表示第 g类;ng表示第g类的样品数量;N = n1 + n2 + n3 + + nG,表示样品总数量。 2) 计算组内协方差矩阵W和总协方差矩阵 T: ij mm Ww ,式中 m表示变量个数, 11 g n G ijigk igjgkjg gk wxxx x ij mm Tt ,式中 m表示变量个数, 11 g n G ijigk ijgkj gk txxx x 3) 逐步计算 假设已计算 l步(包括 l = 0),判别函数中引入了L 个变量,则第 l + 1步的计算内容如下: a) 计算全部变量的判别能力。若xi是未选变量, 则 l ii iL l ii w Ut ;若 xi是已选变量,则 1 l ii iL l ii t Uw , 其中和表示第 l步计算的结果。 l ii w l ii t b) 在已选变量中考虑剔除可能存在的最不显著 的变量从已选变量中寻找最大的 1iL U,即最小的 F 值,将最大的 1iL U 记为 1rL U并作 F检验: 1 1 11 1 rL rL UNG L FUG ,若 F F ( F 为给 定值),则把 xr从判别函数中剔除出去,其后的计算 见第 c)步;若 F F ,则改为考虑从未选变量中选出 最显著的变量,这时从未选变量中寻找最小的 iL U, 即最大的 F值,将最小的 iL U记为 rL U并作 F检验: 1 1 rL rL UNGL FUG ,若 F F ,则把xr引入判 2 Copyright © 2012 Hanspub 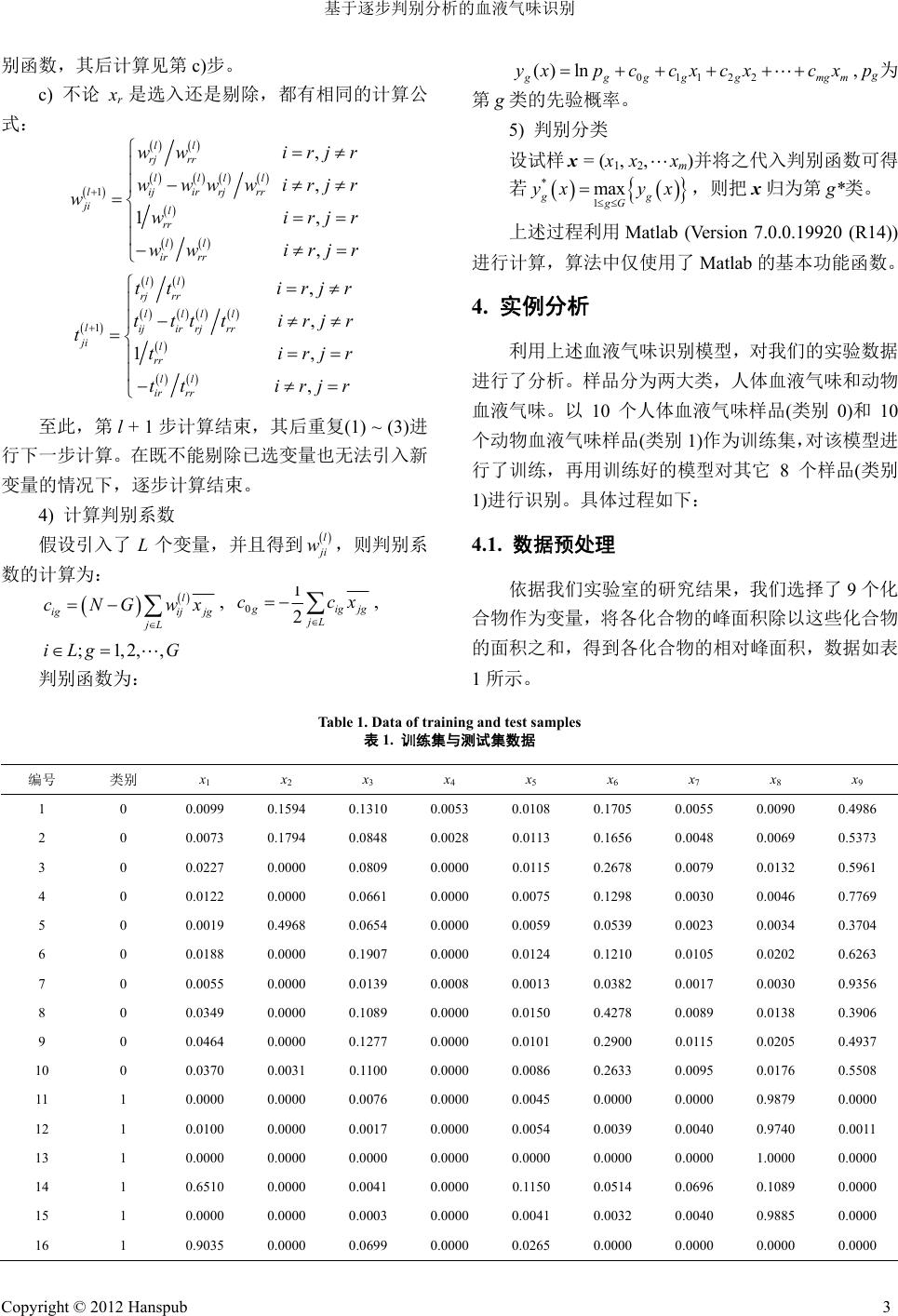 基于逐步判别分析的血液气味识别 Copyright © 2012 Hanspub 3 别函数,其后计算见第 c)步。 c) 不论 xr是选入还是剔除,都 01122 () ln g ggg gmg yxpccx cxcx m , pg为 第g类的先验概率。 有相同的计算公 式: 5) 判别分类 1 , , 1, , ll rj rr llll ww irjr 设试样 x = (x1, x2,xm)并将之代入判别函数可得 若 * 1 max gg gG yx yx ,则把 x归为第 g*类。 lij ir rjrr ji l rr ll ir rr ww wwirjr wwirjr w wirjr 1 , , 1, , ll rj rr llll lijir rjrr ji l rr ll ir rr tt irjr tttt irj tti t tirjr 上述过程利用 Matlab (Version 7.0.0.19920 (R14)) 进行计算,算法中仅使用了 Matlab 的基本功能函数。 r rjr 至此,第 l + 1步计算结束,其后重复(1) ~ (3)进 行下一步计算。在既不能剔除已选变量也无法引入新 变量的情 到 4. 实例分析 利用上述血液气味识别模型,对我们的实验数据 进行了分析。样品分为两大类,人体血液气味和动物 血液气味。以 10 个人体血液气味样品(类别 0)和10 个动物血液气味样品(类别 1)作为训练集,对该模型进 行了训练,再用训练好的模型对其它 8个样品(类别 1)进行识别。具体过程如下: 况下,逐步计算结束。 4) 计算判别系数 假设引入了 L个变量,并且得 l4.1. 数据预处理 j i w,则判别系 数的计算为: 依据我们实验室的研究结果,我们选择了 9个化 合物作为变量,将各化合物的峰面积除以这些化合物 的面积之和,得到各化合物的相对峰面积,数据如表 1所示。 l igij jg jL cNGwx , 0 1 2 g ig jg ccx , ;1,iLg jL 判别函数为: 2,,G Table 1. Data of training and test samples 表1. 训练集与测试集数据 编号 类别 x1 x 2 x6 x7 x8 x9 x3 4x5 x 1 0 0.0099 0.1594 0. 0.1705 0.0055 0.0090 0.4986 1310 0.0053 0.0108 2 0 0.000.17000.013 0.16000. 10 1 16 1 0.9035 0.0000 0.0699 0.0000 0.0265 0.0000 0.0000 0.0000 0.0000 73 94 0.0848 0.28 156 0.48 0.0069 5373 3 0 0.0227 0.0000 0.0809 0.0000 0.0115 0.2678 0.0079 0.0132 0.5961 4 0 0.0122 0.0000 0.0661 0.0000 0.0075 0.1298 0.0030 0.0046 0.7769 5 0 0.0019 0.4968 0.0654 0.0000 0.0059 0.0539 0.0023 0.0034 0.3704 6 0 0.0188 0.0000 0.1907 0.0000 0.0124 0.1210 0.0105 0.0202 0.6263 7 0 0.0055 0.0000 0.0139 0.0008 0.0013 0.0382 0.0017 0.0030 0.9356 8 0 0.0349 0.0000 0.1089 0.0000 0.0150 0.4278 0.0089 0.0138 0.3906 9 0 0.0464 0.0000 0.1277 0.0000 0.0101 0.2900 0.0115 0.0205 0.4937 0 0.0370 0.0031 0.1100 0.0000 0.0086 0.2633 0.0095 0.0176 0.5508 11 0.0000 0.0000 0.0076 0.0000 0.0045 0.0000 0.0000 0.9879 0.0000 12 1 0.0100 0.0000 0.0017 0.0000 0.0054 0.0039 0.0040 0.9740 0.0011 13 1 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 14 1 0.6510 0.0000 0.0041 0.0000 0.1150 0.0514 0.0696 0.1089 0.0000 15 1 0.0000 0.0000 0.0003 0.0000 0.0041 0.0032 0.0040 0.9885 0.0000 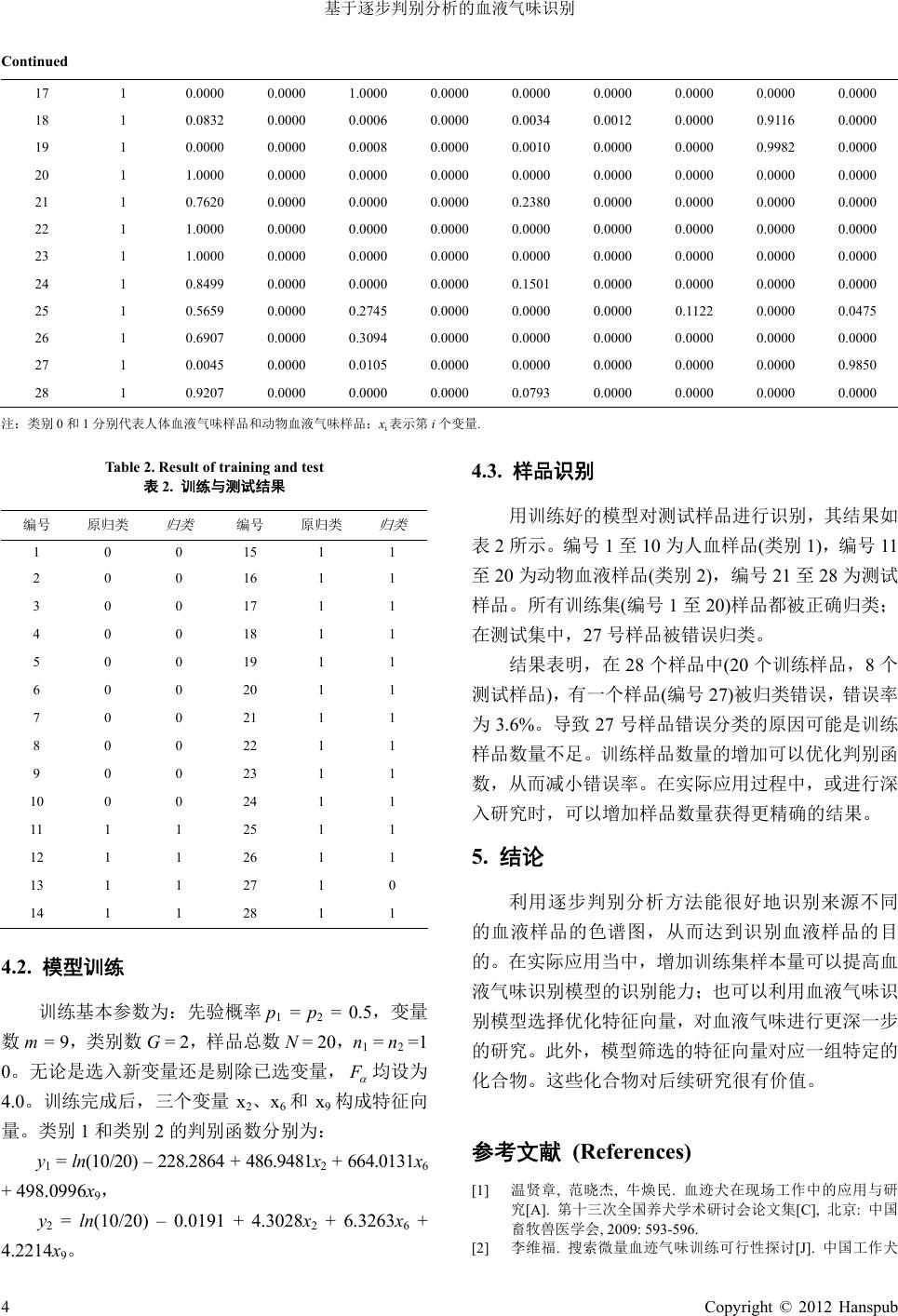 基于逐步判别分析的血液气味识别 Continued 17 1 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 18 1 0.0832 0.0000 0.0006 0.0000 0.0034 0.0012 0.0000 0.9116 0.0000 19 1 0.0000 0.0000 0.0008 0.0000 0.0010 0.0000 0.0000 0.9982 0.0000 20 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 21 1 0.7620 0.0000 0.0000 0.0000 0.2380 0.0000 0.0000 0.0000 0.0000 22 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 23 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 24 1 0.8499 0.0000 0.0000 0.0000 0.1501 0.0000 0.0000 0.0000 0.0000 25 1 0.5659 0.0000 0.2745 0.0000 0.0000 0.0000 0.1122 0.0000 0.0475 26 1 0.6907 0.0000 0.3094 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 27 1 0.0045 0.0000 0.0105 0.0000 0.0000 0.0000 0.0000 0.0000 0.9850 28 1 0.9207 0.0000 0.0000 0.0000 0.0793 0.0000 0.0000 0.0000 0.0000 注:类 0和1分别代表人体血品和气味样第 . Tat 表2. 试结 编号 归类 编号 原归类 别液气味样 动物血液品;xi表示 i个变量 ble 2. Result of training and tes 训练与测 果 原归类 归类 1 1 0 0 15 1 2 0 1 1 0 16 3 0 0 17 1 1 4 0 0 18 1 1 5 0 0 19 1 1 6 0 0 20 1 1 7 0 0 21 1 1 8 0 0 22 1 1 9 0 0 23 1 1 10 0 0 24 1 1 11 1 1 25 1 1 12 1 1 26 1 1 13 1 1 27 1 0 14 1 1 28 1 1 4.2 型训 练基本为:先验概 p1 = p20.5,变量 G = 2,样品总数 N = 20,n = n2 =1 入新变量还是剔除已选变量, . 模练 训 参数率 = 数m = 9,类别数 0。无论是选 1 F 均设为 4.0。 .3263x6 + 4.22 4.3. 用训练好的模型对测试样品进行识别,其结果如 号1至10 为人血样品(类别 1),编号 11 号样品被错误归类。 结果表明,在 28 个样品中(20 个训练样品,8个 测试 确的结果。 5. 结论 优化特征向量,对血液气味进行更深一步 外,模型筛选的特征向量对应一组特定的 化合 [2] 李维福. 搜索微量血迹气味训练可行性探讨[J]. 中国工作犬 训练完成后,三个变量x2、x6和x9构成特征向 量。类别 1和类别 2的判别函数分别为: y1 = ln(10/20) – 228.2864 + 486.9481x2 + 664.0131x6 + 498.0996x9, y2 = ln(10/20) – 0.0191 + 4.3028x2 + 6 14x9。 表2所示。编 至20 为 样品识别 动物血液样品(类别 2),编号 21 至28 为测试 样品。所有训练集(编号 1至20)样品都被正确归类; 在测试集中,27 样品),有一个样品(编号27)被归类错误,错误率 为3.6%。导致 27 号样品错误分类的原因可能是训练 样品数量不足。训练样品数量的增加可以优化判别函 数,从而减小错误率。在实际应用过程中,或进行深 入研究时,可以增加样品数量获得更精 利用逐步判别分析方法能很好地识别来源不同 的血液样品的色谱图,从而达到识别血液样品的目 的。在实际应用当中,增加训练集样本量可以提高血 液气味识别模型的识别能力;也可以利用血液气味识 别模型选择 的研究。此 物。这些化合物对后续研究很有价值。 参考文献 (References) [1] 温贤章, 范晓杰, 牛焕民. 血迹犬在现场工作中的应用与研 究[A]. 第十三次全国养犬学术研讨会论文集[C], 北京: 中国 畜牧兽医学会, 2009: 593-596. 4 Copyright © 2012 Hanspub  基于逐步判别分析的血液气味识别 业, 2011, 2: 24-25. [3] 刘凤义. 犬在血 迹搜索训练中的要点[J]. 中国工作犬业, h 2010, 4: 21. [4] 董继霖. 浅谈血迹搜索犬的训练及使用[J]. 中国工作犬业 . Paulsson. Characteristic odour unds in air and blood from the , 18(4): 421-429. . He and P. F. Shi. Face recognition using differ erman, T.et al. Imoved t orus species (nematoda: Longidoridae) from , [ 2011, 27(2): 26-28. [5] G. Horvath, H. Andersson and G in the blood reveals ovarian carcinoma. BMC Cancer , 2010, 10(1): 643. [6] Y. S. Lin, P. P. Egeghy and S. M. Rappaport. Relationships be tween levels of volatile organic compo general population. Journal of Exposure Science & Environmental Epidemiology, 2008 [7] 张学工. 模式识别[M]. 北京: 清大学出版社, 2010. [8] Y. Wen, L. Hence [13] 许禄, 邵学广. 化学计量学方法(第二版)[M]. 北京: 科学出 版社, 2004. ve c to r p l u s K PC A . D i g i t a l Si gn a l P ro c es s ing , 2 01 2 , 2 2 ( 1 ) : 140-146. [9] A. Daemen, D. Timm Van Den Bosch, pr modeling of clinical data with kernel methods. Artificial Intel- ligence in Medicine[URL], 2011. ttp://www.sciencedirect.com/science/article/pii/S09333657110 01448#FCANote 10] D. S. Cao, Y. Z. Liang, Q. S. Xu, et al. Exploring nonlinear rela- tionships in chemical data using kernel-based methods. Chemo- m e t r i c s a n d In t el l ige n t L ab o ra to r y S y s te ms, 2 0 11, 1 0 7 ( 1 ): 106-1 15. [11] W. Ye and R. T. Robbins. Stepwise and canonical discriminan analysis of longid arkansas. Journal of Nematology, 2004, 36(4): 449-456. [12] C. Simo, P. J. Martin-Alvarez, C. Barbas, et al. Application of stepwise discriminant analysis to classify commercial orange juices using chiral micellar electrokinetic chromatography-laser induced fluorescence data of amino acids. Electrophoresis, 2004, 16(25): 2885-2891. Copyright © 2012 Hanspub 5 |