 Computer Science and Application 计算机科学与应用, 2012, 2, 17-21 http://dx.doi.org/10.12677/csa.2012.21004 Published Online March 2012 (http://www.hanspub.org/journal/csa) An Improved KNN Algorithm for Haplotype Reconstruction Problem Tao Zhuang, Hong Liu School of Computer Science and Technology, Shandong University, Jinan Email: zhtao663@163.com Received: Dec. 1st, 2011; revised: Dec. 29th, 2011; accepted: Jan. 14th, 2012 Abstract: Single Nucleotide Polymorphisms (SNPs) is a single base pair position in genomic DNA where different nucleotide variants exist in some population, and is considered as the most frequent form of human genetic variants. The haplotype is composed of the SNP which was found to contain more genetic information. Study it plays an important role in the diagnosis of disease and drugs design. Haplotype reconstruction is to reconstruct a pair of haplotypes from localized polymorphism data got through short genome fragment assembly. In this paper, a new clustering method, based on KNN and PSO algorithms, is proposed to solve haplotype reconstruction problem. In the end, it will be used simulation data and real biological data to test the proposed algorithm, and the results show that the proposed method is feasible. Keywords: SNP; Haplotype Assembly; Cluster; KNN; PSO 基于改进的 k最近邻算法的单体型重建问题 庄 涛,刘 宏 山东大学计算机科学与技术学院,济南 Email: zhtao663@163.com 收稿日期:2011年12月1日;修回日期:2011年12月29 日;录用日期:2012 年1月14 日 摘 要:单核苷酸多态性(SNPs)是人类遗传变异中最显著的一种形式,是一个物种中 DNA序列中某个位点上的 碱基变化。人们发现由单核苷酸组成的单体型比单一的单核苷酸包含更多的生物遗传信息,因此研究单体型对 于诊断疾病和药物研制有着重要作用。单体型重建就是对由SNP 片段组成的基因片段进行组装,从而构造出原 来的一对单体型。本文在 k最近邻和粒子群算法的基础上,提出一种解决单体型重建问题的一种聚类算法。最 后,本文将用模拟数据和真实数据来检验本文所提出的算法,结果证明所提出的算法可行。 关键词:单核苷酸多态性;单体型重建;聚类;k最近邻算法;粒子群算法 1. 引言 随着人类基因组图谱的基本完成[1],人们对遗传 的差异性、由基因突变引起的疾病复杂性有了更精确 的阐释[2]。现在人们普遍认为,DNA 序列中少数的差 异是导致遗传疾病的主要原因。单核苷酸多态性 (SNPs),DNA某一位置碱基的变化[3],被认为是一个 物种不同个体表型的主要遗传来源[4]。研究 SNPs 对 基因的研究、遗传疾病的诊断和药物研制有着重要作 用。人类的 DNA 序列是按染色体成对出现的,每一 条染色体上 SNP 位点上的碱基序列叫做单体型,所以 人类等二倍体生物都有一对单体型。在医学研究中, 单体型数据通常比单个SNP 携带更多的信息。基于单 体型在遗传分析上的重要性,现在人们较为关注的是 单体型的检测问题。 Copyright © 2012 Hanspub 17  基于改进的 k最近邻算法的单体型重建问题 令人遗憾的是在当前的实验技术下,直接通过生 物实验手段来得到单体型既费时又费力,因此利用计 算机技术,通过计算的方式来获得单体型具有很好的 实际应用价值。目前检测单体型的方法主要有两种: 个体单体型检测,也称为单体型重建;群体单体型检 测,也称为单体型推断。本文主要对前者进行研究。 SNP位点是一个物种的基因组 DNA 序列中不同个体 可能出现不同碱基的位置。位于一个SNP 位点的碱基 称为等位基因。对于任意一个 SNP 位点来说,若两条 同源染色体上的碱基相同,则称为纯和位点;若不相 同,则称为杂合位点。几乎所有的SNP 位点上的碱基 都只有两种取值,为方便起见,我们用字符集{0,1,-} 上的字符序列来表示单体型,而不必用真正的碱基字 符,其中“-”表示该位点的取值未知,被称为空。因 此单体型可看作是一个字符串序列。 尽管科学技术有了很大的进步,但是由于技术的 限制、基因组的测序错误以及测试样本的污染等原 因,通过实验手段直接得到单体型是很困难的且代价 极为昂贵的。因此人们常利用计算的方式,设计一个 准确有效地算法来解决单体型重建问题。 依赖于不同的数据错误类型,主要有几种不同的 解决模型。其中主要有最少 片段删除模型(MFR)、最 少 SNP 去除模型(MSR)和另外一种被普遍应用的模型— —最少错误纠正模型(MER)[4,5]。其中 MER 模型首先被 Lippert 等人证明是 NP-hard 问题[5]。其它模型,例如 LHR,MEC/GI ,WMLF,WMEC 等也被用到[6,7]。实 际上单体型重建问题可以被看作是一个聚类问题。一 种启发式的聚类算法在文章 [8,9]中已被应用。本文中, 我们将给出另外一种基于 k最近邻算法和粒子群优化 算法的具有较好结果和效率的启发式 的聚类方法。 本文其他部分的组织结构如下:在第二部分中, 我们将给出单体型重建问题的形式化描述,给出一些 必要的字符、公式定义。我们的方法将在第三部分给 出。实验结果将在第四部分给出。最后,我们将总结 本文。 2. 符号、公式定义 假设给定来自某对同源染色体的 m条SNP 片段, 每条 SNP片段对应的单体型长度为n。为了描述方便, 在下文,所提到的片段也指 SNP 片段。我们定义一个 m × n的SNP 矩阵 M = [mij],0 < i ≤ m,0 < j ≤ n,每 个元素的值为 0、1或-矩阵 M中的每一行代表一条 SNP 片段,每一列代表一个 SNP 位点。 给出变量 x,y{0,1,-},并给出如下定义: 1 , , 0 x yx sxy 如果 且 其他 y (1) 1 , , 0 x yx dxy 如果 且 其他 y in (2) 对于两条 SNP片段 和 1,, ii mm m 1,, j j mm m jn ,给出如下定义: 1 , n ij ikjk k Smmsm m , , (3) 1 , n i jikjk k Dmmdmm (4) 如果 , ij Dmm 0,称这两条片段冲突,否则称 之为兼容。片段和单体型之间的距离也类似给出定 义。如果所有片段没有数据错误,则矩阵M中的行可 以被分为两个不相交的子集,每个子集中的所有行相 容且决定一条单体型。这时,称矩阵 M是可行的,否 则是不可行的。 定义 12 ,PCC,集合 C1和集合 C2代表片段划 分到的两个集合。定义 和 11112 1 ,,, n hhh h 122 2 ,,, n h h 22 hh为一对原始的单体型,用 12 h,hh 代表通过算法构造的单体型。用算法对片段 进行分类后,可以通过叠加同一集合中的片段构造 1 h 。 定义表示集合 C中所有片段第 j列中0的 个数。相同的,代表 1的个数。因此,单体型 根据以下方法进行构造: 0 jCN 1 jCN 01 0 10 01 0 0 1 - 0 ji ji ji ij ji ji ji ji NC NC NC hNC NC NC NC 如果 且 如果 如果 (5) 其中 1, 2i,1, 2,,jn 。 最后,用重建率(RR)来衡量单体型重建的正确度。 重建率说明了重新构建的单体型 与原始 单体型 12 ,hhh 12 ,hhh之间的相似程度。定义如下: 11 22 1221 min , ,1 2 rrrr RRh hn (6) 其中 , iji j rDhh ,1, 2i ; 并且 1, 2j Copyright © 2012 Hanspub 18  基于改进的 k最近邻算法的单体型重建问题 1 ,, n i jikjk k Dhhdh h 3. 算法 本节将给出解决单体型重建问题的启发式的聚 类算法。首先,介绍k最近邻算法和粒子群算法。 粒子群算法也称为粒子群优化算法(Particle Swarm Optimization),缩写为 PSO,是近年来发展起来的一 种新的进化算法。PSO算法和遗传算法相似,也是从 随机解出发,通过迭代寻找最优解;也是通过适应度 来评价解的品质,但比遗传算法规则更为简单,本算 法没有遗传算法的“交叉”和“变异”操作,本算法 通过追随当前搜索到的最优值来寻找全局最优。与遗 传算法相比较,粒子群算法在大多数情况下,能较快 的得到最优化的解[10]。 k最近邻(k-Nearest Neighbor,KNN)分类算法,是 较成熟和较简单的聚类分析算法之一。该方法的思路 是:选取一个待分类样本在特征空间中的k个最相似 (即特征空间中最邻近)的样本,如果这 k个中的大多 数样本属于某一个类别,则该待分类样本也属于这个 类别。一种启发式的聚类算法已经在文章[8]中被提 到,其数学形式表示如下: 12 2 12 max ,,,,, and and pp pp pp SfCDfCSf CDfC fC fC 1 (7) 通过这个公式,可以在每次迭代的过程中,将所 有的片段分到相应的集合中。但是在某些情况下,可 以通过理论及实验证明,(7)式并不准确。例如,C1 中片段的数量不等于 C2中片段的数量,(7)式就显得 没有多少意义了。为此,本文提出了一种改进算法。 实验结果表明,该改进算法能取得更好更精确的结 果,同时也提高了执行效率。 PHKN 算法 将粒子群算法和部分的 k最近邻算法结合起来达 到优化结果的目的,本文称之为 PHKN(英文)算法。 首先,计算出任意两条SNP 片段之间的距离,找出距 离最大者,并将相对应的两条片段分别放到集合 C1 和C2中,作为集合划分的初始值。接下来,在每次分 配过程中,通过粒子群算法为未划分的每一条片段分 别从集合 C1和C2中选取 k´条片段,这是本算法的关 键所在。其中k'的取值有以下公式决定: 12 1.5 log min,1 CC knn (8) 假设未划分的片段为 fp,通过公式(3)和公式(4) 分别计算出 fp与从 C1、C2中选取的k'条片段的距离 1 , p dfC、 2 , p dfC。比较 与 1 , p dfC 2 , p dfC的 大小,若 2 , p C 1 f, p dfCd,将 fp划分到集合C1, 否则我们将 fp划分到 C2,更新集合 C1、C2,进入下 一次迭代,直至所有片段被划分到两个集合为止。虽 然选择了 k'条片段,但是主要原理还是与 k最近邻算 法有区别的,顶多是用了 k最近邻算法的思想,加之 在k'条片段的选取中用到了粒子群算法,所以称本文 的方法为 PHKN 算法。算法的详细步骤在表 1中给出。 为了使得以上程序获得更加准确的结果,把h'作 为划分集合的初始值并且重复算法PHKN 直到h'不再 变化或者算法被运行100 次为止。 4. 实验结果 试验中采用真实数据和模拟数据来检验算法的 准确性。并在中央处理器为 Intel Pentium IV 2.33 GHz,内存为 2 GB 的微机系统上用 Java 语言运行。 4.1. 模拟数据 首先,用模拟数据来测试PHKN 算法。首先,随 机生成 10 条不同的单体型,每条单体型长度为60, 并通过相似度参数s来生成对应的 10条单体型,其中 Table 1. Pseudo code for the PHKN algorithm 表1. PHKN算法的伪代码 输入:m × n的SNP矩阵 M 输出:一对单体型 12 ,hhh 步骤 1:寻找距离最大的两条片段 m1和m2,作为初始值放 到集合 C1和C2中。 步骤 2:初始化参数,种群大小N,学习因子C1、C2,粒子 大小(SNP 片段的数量)k'以及最大迭代次数GN。 步骤 3:运行粒子群算法,分别为每条片段从每个集合中找 出最优的 k'条片段。 步骤 4:如果 12 21 ,, ,, kk pp kk pp SfC DfC SfC DfC 则 11i CC f ; 否则 22i CC f 。 步骤 5:如果仍有剩余的片段,则转到步骤2,否则转到步 骤6。 步骤 6:停止,通过划分的两个集合产生一对单体型。 Copyright © 2012 Hanspub 19 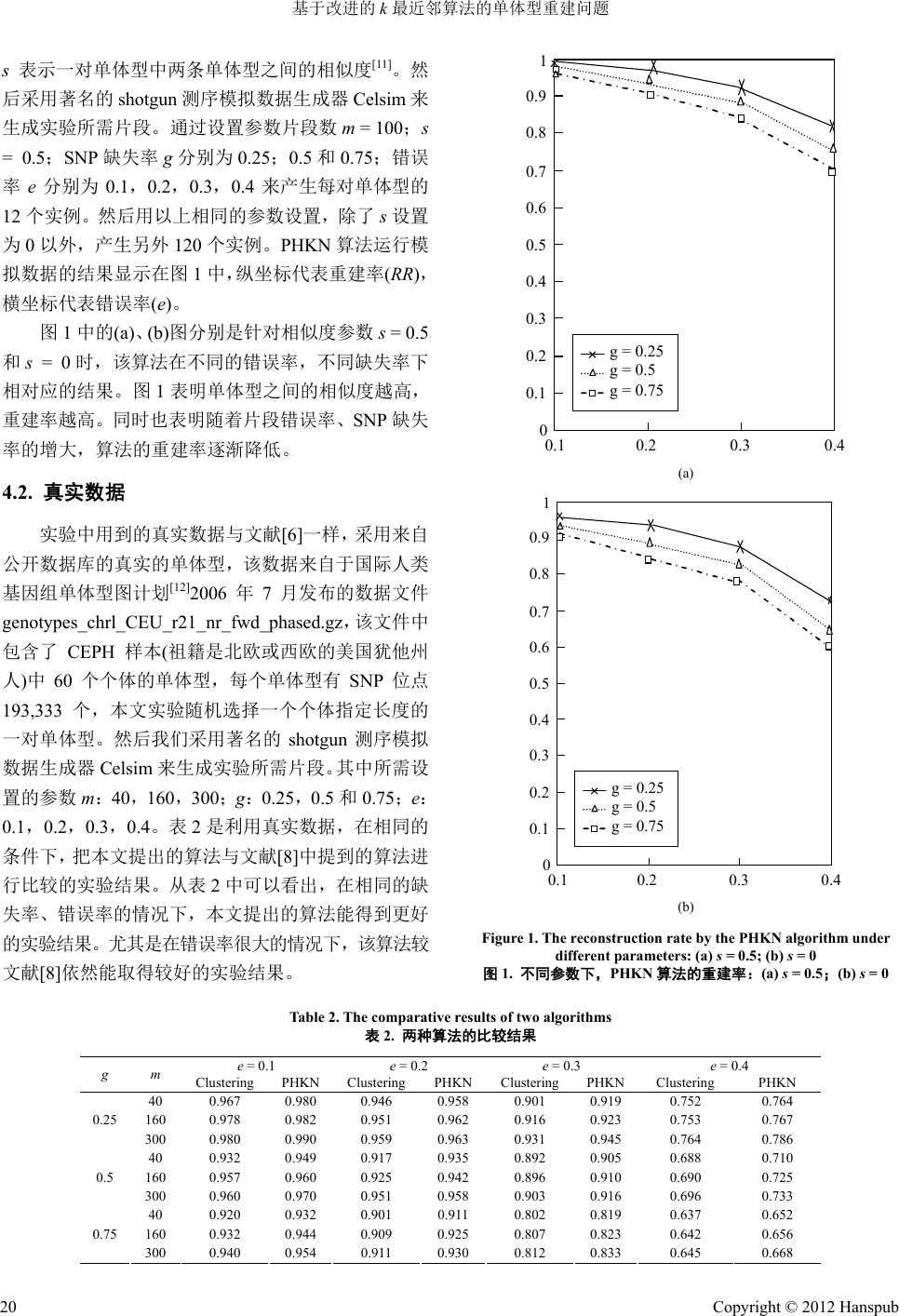 基于改进的 k最近邻算法的单体型重建问题 Copyright © 2012 Hanspub 20 1 0 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0.1 0.20.30.4 g = 0.25 g = 0.75 g = 0.5 s表示一对单体型中两条单体型之间的相似度[11]。然 后采用著名的 shotgun 测序模拟数据生成器 Celsim来 生成实验所需片段。通过设置参数片段数 m = 100;s = 0.5;SNP 缺失率 g分别为 0.25;0.5 和0.75;错误 率e分别为 0.1,0.2,0.3,0.4来产生每对单体型的 12 个实例。然后用以上相同的参数设置,除了s设置 为0以外,产生另外120 个实例。PHKN 算法运行模 拟数据的结果显示在图1中,纵坐标代表重建率(RR), 横坐标代表错误率(e)。 图1中的(a)、(b)图分别是针对相似度参数 s = 0.5 和s = 0时,该算法在不同的错误率,不同缺失率下 相对应的结果。图1表明单体型之间的相似度越高, 重建率越高。同时也表明随着片段错误率、SNP 缺失 率的增大,算法的重建率逐渐降低。 (a) 4.2. 真实数据 1 0 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0.1 0.20.30.4 g = 0.25 g = 0.75 g = 0.5 实验中用到的真实数据与文献[6]一样,采用来自 公开数据库的真实的单体型,该数据来自于国际人类 基因组单体型图计划[12]2006 年7月发布的数据文件 genotypes_ chrl_CEU_r 21_nr_fwd_p hased.gz,该文件中 包含了 CEPH 样本(祖籍是北欧或西欧的美国犹他州 人)中60 个个体的单体型,每个单体型有 SNP 位点 193,333个,本文实验随机选择一个个体指定长度的 一对单体型。然后我们采用著名的 shotgun测序模拟 数据生成器 Celsim 来生成实验所需片段。其中所需设 置的参数 m:40,160,300;g:0.25,0.5 和0.75;e: 0.1,0.2,0.3,0.4。表 2是利用真实数据,在相同的 条件下,把本文提出的算法与文献[8]中提到的算法进 行比较的实验结果。从表2中可以看出,在相同的缺 失率、错误率的情况下,本文提出的算法能得到更好 的实验结果。尤其是在错误率很大的情况下,该算法较 文献[8]依然能取得较好的实验结果。 (b) Figure 1. The reconstruction rate by the PHKN algorithm under different parameters: (a) s = 0.5; (b) s = 0 图1. 不同参数下,PHKN 算法的重建率:(a) s = 0.5;(b) s = 0 Table 2. The comparative results of two algorithms 表2. 两种算法的比较结果 e = 0.1 e = 0.2 e = 0.3 e = 0.4 g m Clustering PHKN Clustering PHKNClustering PHKNClustering PHKN 40 0.967 0.980 0.946 0.958 0.901 0.919 0.752 0.764 160 0.978 0.982 0.951 0.962 0.916 0.923 0.753 0.767 0.25 300 0.980 0.990 0.959 0.963 0.931 0.945 0.764 0.786 40 0.932 0.949 0.917 0.935 0.892 0.905 0.688 0.710 160 0.957 0.960 0.925 0.942 0.896 0.910 0.690 0.725 0.5 300 0.960 0.970 0.951 0.958 0.903 0.916 0.696 0.733 40 0.920 0.932 0.901 0.911 0.802 0.819 0.637 0.652 160 0.932 0.944 0.909 0.925 0.807 0.823 0.642 0.656 0.75 300 0.940 0.954 0.911 0.930 0.812 0.833 0.645 0.668  基于改进的 k最近邻算法的单体型重建问题 5. 结论 本文设计了一种启发式的数据聚类算法,从两个 集合中同时选择 k'条片段作为片段划分的依据是对文 献[8]的改进,通过采用模拟数据和真实数据检验了改 进算法的有效性。虽然经过改进,算法的准确度和执 行效率有了很大提高,但仍然不能得到最优化的解, 但是对单体型重建问题提供了一种快捷有效的解决 方案。因此,在未来的研究中,将继续采用类似的方 法来解决该问题。 参考文献 (References) [1] J. C. Venter, M. D. Adams, et al. The sequence of the human genome. Science, 2001, 291(5507): 1304-1351. [2] M. R. Hoehe, K. Kopke, B. Wendel, et al. Sequence variability and candidate gene analysis in complex disease: Association of opioid receptor gene variation with substance dependence. Hu- man Molecular Genetics, 2000, 9(19): 2895-2908. [3] The International HapMap Consortium. A haplotype map of the human genome. Nature, 2005, 437: 1299-1320. [4] Z. Li, W. Zhou, X. Zhang and L. Chen. A parsimonious tree-grow method for haplotype inference. Bioinformatics, 2005, 21(17): 3475-3481. [5] R. Lippert, R. Schwartz, G. Lancia and S. Istrail. Algorithmic strategies for the single nucleotide polymorphism haplotype as- sembly problem. Briefings in Bioinformatics, 2002, 3(1): 23-31. [6] R. S. Wang, L. Y. Wu, Z. P. Li and X. S. Zhang. Haplotype re- construction from SNP fragments by minimum error correction. Bioinformatics, 2005, 21(10): 2456-2462. [7] X. S. Zhang, R. S. Wang. Models and algorithms for haplotyping problem. Current Bioinformatic, 2006, 1(1): 105-114. [8] C. Eslahchi, M. Sadeghi, H. Pezeshk, M. Kargar and H. Poor- mohammadi. Haplotyping problem, a clustering approach, nu- merical analysis and applied mathematics. International Confer- ence, 2007, 936: 185-190. [9] Y. Wang, E. Feng and R. S. Wang. A clustering algorithm based on two distance functions for MEC model. Computational Biol- ogy and Chemistry, 2007, 31(2): 148-150. [10] J. Kennedy, R. C. Eberhart. Particle swarm optimization. Pro- ceedings of the IEEE International Conference on Neural Net- works, Perth, 27 November 1995-1 December 1995, 1942-1948. [11] W. Y. Qian, Y. J. Yang, N. N. Yang and C. Li. Particle swarm optimization for SNP haplotype reconstruction problem. Applied Mathematics and Computation, 2008, 196(1): 266-272. [12] The International HapMap Consortium. The international Hap- Map project. Nature, 2003, 426(6968): 789-796. Copyright © 2012 Hanspub 21 |