Statistical and Application
Vol.04 No.04(2015), Article ID:16630,6
pages
10.12677/SA.2015.44029
Macroeconomic Statistics Matching Evaluation
—In Xinjiang
Wanqiu Li, Jianjun Zhou
School of Mathematics and Statistics, Yunnan University, Kunming Yunnan

Received: Dec. 4th, 2015; accepted: Dec. 26th, 2015; published: Dec. 29th, 2015
Copyright © 2015 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
Statistics is a government department of social and economic operation of supervision and management means such as decision analysis of important basis, and the quality of statistical data about the effectiveness of government management, so the quality of statistical data of the test as government departments and economic theory researchers on topics of mutual interest. Suitability assessment is an important content of statistical data quality assessment, this article is based on gross domestic product (GDP), the total retail sales of social consumer goods (LS), the whole society fixed asset investment (INV), urban per capita disposable income (UPDI) four indexes, through the integrated time series and simultaneous equation method to match the statistical data of four indicators analysis, concluded that Xinjiang macroeconomic statistics matching sexual needs to improve, and give advice.
Keywords:Data Matching, Time Series Analysis, Simultaneous Equations Model

宏观经济统计数据匹配性评价
—以新疆维吾尔自治区为例
李晚秋,周建军
云南大学数学与统计学院,云南 昆明

收稿日期:2015年12月4日;录用日期:2015年12月26日;发布日期:2015年12月29日

摘 要
统计数据是政府部门对社会经济运行情况监督、决策分析等管理手段的重要依据,而统计数据的质量关乎着政府部门管理措施的成效,因此对统计数据质量的检验成为政府部门和经济理论研究者共同关注的话题。匹配性评估是统计数据质量评估重要内容,本文基于国内生产总值(GDP)、社会消费品零售总额(LS)、全社会固定资产投资总额(INV)、城镇居民人均可支配收入(UPDI)四个指标,通过综合时间序列和联立方程方法对四个指标的统计数据进行匹配性分析,得出新疆宏观经济统计数据匹配性有待提高的结论,并给出建议。
关键词 :数据匹配性,时间序列分析,联立方程组模型

1. 前言
一个地区社会经济的均衡发展是科学发展的关键,地区社会经济的均衡发展有赖于统计数据真实可靠的反映客观实际、有赖于统计调查对社会经济状况的有效监督和反馈。统计数据的匹配性评估是统计数据质量评估重要的一环,而数据之间是否协调匹配是其中要点。
目前我国尚未建立制度性的政府宏观统计数据质量评估与管理体系,对宏观统计数据质量的研究多以综合管理和对策性研究为主,如谭斌(2001)关于提高统计数据质量的几点看法[1] ;在研究视角上,基本上都是从被评估指标自身角度进行设计,对单项指标数据匹配性的评估又主要是围绕GDP等指标展开,如李庭辉(2012)用相对误差率来评估GDP在时间序列方面的数据匹配性 [2] ;赵翔,程飞,潘英杰(2012)构建相对误差率来评估部分省份GDP数据匹配性 [3] ;周国富(2013)用空间面板模型对中国地区GDP数据质量评估 [4] 等。
本文从数据匹配性的角度出发,利用国民生产总值、城镇人均可支配收入、全社会固定资产投资总额和社会消费品零售总额四个指标,通过构建预测值与实际值的相对误差率来评估四个指标的数据匹配性。并且在单指标时间序列分析的基础上引入了联立方程组模型。以上四个评估指标不仅受其他因素的影响,同时也会反作用于其他因素,故考虑用联立方程组模型对四个指标进行预测。结合纵向时间序列和横向联立方程模型两个方面可以对宏观经济统计数据的匹配性做出更为综合的评价。
2. 分析基础
参考《新疆国民经济和社会发展第十二个五年规划纲要》的目标中提到的与新疆运行状况密切相关的宏观经济指标,根据统计数据的来源、统计方法、以及政府与民众对指标的关注程度,尽可能地考虑了指标的代表性、全面性和数据的可获得性,选取了Y1国内生产总值(GDP)、Y2社会消费品零售总额(LS)、Y3全社会固定资产投资总额(INV)、Y4城镇居民人均可支配收入(UPDI)四个指标作为的主要评估指标。
在判断数据匹配性时,李廷辉、朱一波等学者都是通过构造相对误差率指标来作为评判标准 [5] 。即
测量第t期实际观测值与根据模型得到的估计值的相对误差,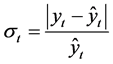 。如果某年数据相对误差率
。如果某年数据相对误差率
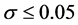 则认为该年数据与相关指标数据匹配;反之,则认为不匹配。该相对误差率既反映了地区数据偏离平均水平的偏离程度,又剔除掉了自身规模或水平对离差的影响,因此具有横向和纵向的可比性。
则认为该年数据与相关指标数据匹配;反之,则认为不匹配。该相对误差率既反映了地区数据偏离平均水平的偏离程度,又剔除掉了自身规模或水平对离差的影响,因此具有横向和纵向的可比性。
3. 纵向统计数据匹配性评价
根据新疆统计年鉴、新疆五十年、中国金融统计年鉴等,本文选取了各指标1980~2013年共34年的年度数据。由于Y4城镇人均可支配收入的1981~1984年数据存在缺失,因此对Y4只分析其1985年至2013年的年度数据。为消除指数型变量带来的异方差性,需要对这些数值型统计指标取自然对数。
如表1所示,由ADF检验结果可知,ln(Y1)、ln(Y2)、ln(Y3)、ln(Y4)均为一阶单整序列,且差分后的各变量均非白噪声。由此对各指标考虑时间序列的随机性模型,Δln(Y1)采用ARMA(2,1)模型、Δln(Y2)采用ARMA(3,1)模型、Δln(Y3)采用ARMA(1,2)模型、Δln(Y4)采用ARMA(1,1)模型。对这四个变量模型残差经检验为白噪声。经残差图对比后认为模型预期值与真实值的差距在0.05以上的,是偏离模型预期的数据。
如图1所示,从各因变量的匹配情况看:Δln(Y4)城镇居民人均可支配收入(UPDI)的匹配性最好,仅有6个年份的数据偏离了模型预期,1996年以后数据匹配性都较好;Δln(Y1)国民生产总值(GDP)的匹配性次之,有10个年份的数据与模型有所偏离,普遍呈现实际值比预测值先偏低后偏高的情况;Δln(Y2)社会消费品零售总额(LS)实际值比预测值先偏低后偏高;Δln(Y3)全社会固定资产投资(INV)的匹配性最差。
2000年以前四个指标的相对误差率均在0.05以上,其中1993年以前的数据匹配性尤为不好,2000年以后四个指标的数据匹配性较好。
4. 横向统计数据匹配性评价
4.1. 模型变量选择
从经济发展来看,宏观经济统计数据相关变量之间的关系具有稳定性。在投入产出环节,与用电量指标相关;在后续流通或消费环节与货运量指标相关;在终期形态上,与财政收入指标、出口总额指标相关。而且这种相关具有渐进的稳定性和结构的稳定性。
我们按照计算国内生产总值的不同方法,确定部分有代表性的指标,如选择支出法中的“出口总值”,选择收入法中的“地方财政总收入”。另外,为作为辅助参考,我们还选择了与经济发展密切相关的“全社会用电量”和“货运量”以增加估计地区经济水平的准确性。
模型变量具体如表2所示。
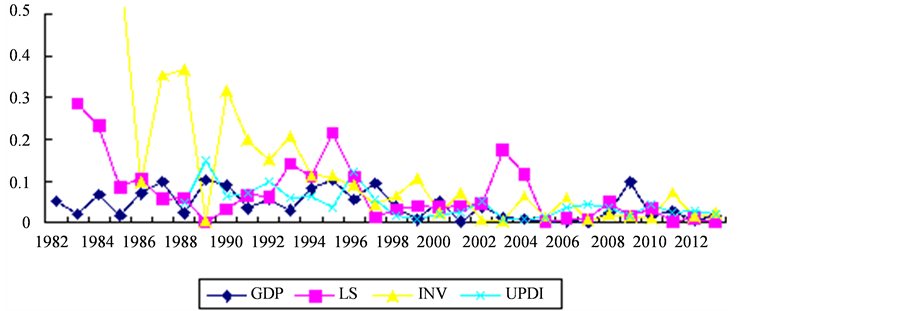
Figure 1. Relative error of prediction and the actual value in evaluation index time series model
图1. 待评估指标时间序列模型预测值与实际值相对误差情况

Table 1. Unit root test——Augmented Dickey-Fuller test
表1. 单位根检验——Augmented Dickey-Fuller检验
注:检验类型(c,t,k)分别表示检验平稳性时估计方程中的常数项、趋势项和最优滞后期
Table 2. Model list of variables
表2. 模型变量列表
4.2. 模型方程解释
1) 经济增长方程
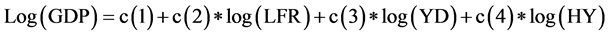
该方程描述了经济增长和财政收入、全社会用电量、货运量的关系。财政收入既是维持国家有效运转的经济基础,又是国家调节经济的有效手段,同时,在一定的政策下,地区财政收入的多少与产出之间存在高度的相关关系。货运量则是反映经济景气程度的一个重要内容,地区经济主要还是需要运输来完成的经济,因此引用全社会用电量和货运量两个解释变量。
2) 社会消费品零售总额模型
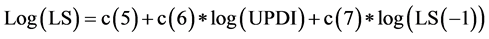
该方程描述了社会消费品零售总额和城镇人均可支配收入、社会消费品零售总额滞后期的关系。社会消费品零售总额的数据质量评估涉及到可支配收入和社会消费品零售总额两个指标,其中社会消费品零售总额为被评估的对象,可支配收入是核心匹配指标,而可支配收入有不同的指标,根据数据的可获取性原则,选取城镇居民人均可支配收入。
3) 固定资产投资需求方程
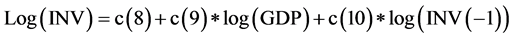
该方程描述了固定资产投资和GDP、固定资产投资滞后期的关系。根据固定资产投资的影响因素分析可知,一个地区固定资产投资受其影响最直接的途径是经济发展水平和其历史时期的固定资产投资规模的影响,故而此处引入了GDP和INV(−1)两个解释变量 [6] 。
4) 城镇人均可支配收入模型

该模型描述了城镇人均可支配收入和固定资产、出口总值、消费品零售总额、用电量、地方财政收入的关系。城镇人均可支配收入受经济发展水平、政策导向、贸易情况、社会环境等方面因素的综合影响,故而引进固定资产投资、地方财政收入、出口总值、用电量四个指标分别代表这四方面的影响。
联立方程组模型整体检验采用了连续事后预测。方法是将模型中的内生变量29年实际数值赋予模型,各年外生变量取实际值,计算预测结果与实际数值之间的误差。
对27个年份数据匹配分析,四个待评估指标中没有一个年份是四个指标相对误差率均在0.05以内。匹配性最不好的年份是2005年和2006年,四个指标的相对误差率均超过0.1。其余二十五个年份四个指标至少有一个指标是匹配的。2000年以后四个指标的数据匹配性较2000年前稍好。
如图2所示,分指标来看,四个指标的匹配性都不好。Y4城镇居民人均可支配收入(UPDI)的偏离情况最严重,21个数据误差较大。Y1国内生产总值(GDP)有17个数据偏离,预测值具有明显的周期性。Y2社会消费品零售总额(LS)有14个数据偏离,其误差逐步加大,最后逐步缩小。Y3全社会固定资产投资(INV)有12个数据偏离,其相对误差逐渐缩小。由于方程4的设定,Y2社会消费品零售总额(LS)和Y4城镇居民人均可支配收入(UPDI)的数据偏离情况具有联动性,两个指标同年度下都偏高或都偏低。
5. 结论及建议
5.1. 结论
本文选取的四个待评估指标中,纵向匹配性最不好的指标是Y3全社会固定资产投资(INV),横向匹配性最不好的指标是Y4城镇居民人均可支配收入(UPDI)。整体来看:2000年以后的数据匹配性比2000年以前的好;纵向匹配性比横向匹配性好,横向匹配性较差。根据以上对统计数据匹配性的分析,可以得出新疆宏观经济统计数据匹配性有待提高的结论。
Y3全社会固定资产投资(INV)的匹配性不好,分析其原因,新疆受的投资导向型经济发展和受偶发事件的影响较大是关键。政府在经济发展中有宏观调控的作用,对口援疆等政策对新疆的固定资产投资影响较大,全社会固定资产投资应该是成几何级数增长的,所以造成实际值比拟合值偏高。
Y4城镇居民人均可支配收入(UPDI)一直保持较快发展,其增长速度远远高于匹配性指标的增长速度,这是导致该指标匹配性较差的原因。此外,城镇居民人均可支配收入的来源很多,统计不方便,由此造成的统计数据偏差也导致该指标匹配性较差。
2000年以前的数据匹配性较为不好,均与当时的新疆经济形势发展有关。21世纪以来,随着新疆统计体制机制不断完善,同时经济运行也相对稳定,各宏观经济数据匹配性较之前有一定改善。
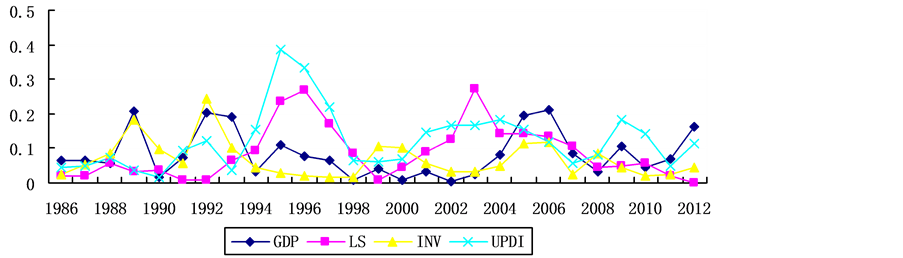
Figure 2. Relative error of prediction and the actual value in assessment index of simultaneous equations model
图2. 待评估指标联立方程组模型预测值与实际值相对误差情况
5.2. 建议
首先,在本文分析过程中发现四个评估指标中Y3全社会固定资产投资(INV)和Y4城镇居民人均可支配收入(UPDI)匹配性不好均与政府导向有关,建议自治区政府做宏观调控的时候注重经济的健康平衡发展。
其次,要提高统计数据的匹配性,就要确保统计数据真实可靠。需要继续健全统计指标和统计方法,完善统计指标体系增加数据透明性,强化数据监控过程,提高统计人员综合素质。
最后,多指标全口径衡量经济发展。近年来人们对经济的关注度大多集中在GDP数据上,官方GDP数据在传递上已不知经过了多少只手,其中的人为因素显然不容忽视,真实性也因而大打折扣。2010年提出的克强指数,其耗电量、铁路货运量和银行贷款发放量三项指标项项涉及真金白银,几乎不存在作假可能性。而克强指数与官方发布的GDP走势相对照,发现趋势上总体一致,但在上下波幅上,前者的表现比后者剧烈的多。以此为例,多指标全口径的衡量经济发展,不单纯凭借某一指标来评定经济发展,均分社会公众关注的舆论压力,可以缓解统计数据注水现象,从而提高宏观经济统计数据匹配性。
致谢
感谢石河子大学何剑老师对本论文提出宝贵建议。在论文的写作过程中引用了许多专家学者的研究成果,在这里也向他们表示感谢!感谢编辑和审稿人对本论文提出的宝贵意见。本研究得到了国家青年自然科学基金项目(11301464)的支持,特此感谢。
文章引用
李晚秋,周建军. 宏观经济统计数据匹配性评价—以新疆维吾尔自治区为例
Macroeconomic Statistics Matching Evaluation—In Xinjiang[J]. 统计学与应用, 2015, 04(04): 262-267. http://dx.doi.org/10.12677/SA.2015.44029
参考文献 (References)
- 1. 谭斌. 关于提高统计数据质量的几点看法[J]. 新疆农垦经济, 2001(3): 74-75.
- 2. 李庭辉, 薛丽娜. 基于时间序列匹配性的GDP数据质量评估研究[J]. 财经理论与实践, 2012(1): 119-123.
- 3. 赵翔, 程飞, 潘英杰. 基于两种方法的部分省份宏观经济数据匹配性研究[D]. 西安: 陕西统计局, 2012.
- 4. 周国富. 中国地区GDP数据质量评估[J]. 统计研究, 2013(3): 17-23.
- 5. 朱一波. 浙江宏观经济统计数据质量评估的实证研究[J]. 统计科学与实践, 2013(12): 20-22.
- 6. 何剑. 统计综合实验[M]. 大连: 东北财经大学出版社, 2014.