符繁强1,韦 维1,周 荧2,钱柳1
1贵州民族大学,数据科学与信息工程学院,贵州 贵阳
2贵州大学,数学与统计学院,贵州 贵阳
收稿日期:2018年10月1日;录用日期:2018年10月17日;发布日期:2018年10月24日
有限动态博弈过程在部分玩家的策略给定情形下,可以转化为多值逻辑控制网络的最优控制问题。本文研究这一类单输入输出的有限动态博弈问题,论文利用矩阵半张量积的方法,推导出多值逻辑动态系统的代数表达式和收益目标泛函的半张量积的表达形式,并证明此收益最大化问题新的表达方式与原问题的等价性;进而,给出了求解半张量积系统最优控制问题的动态规划法和算法;最后,应用此算法求解一个实例。 The finite dynamic game process can be transformed into the optimal control problem of multi-valued logic control networks given the strategy of some players. In this paper, we study the finite dynamic game problem of single input and output. The paper uses the method of matrix half tensor product to derive the algebraic expression of multi-valued logic dynamic system and the expression of the semi-tensor product of the income objective functional, and proves the equivalence between the new expression of this income maximization problem and the problem. Furthermore, the dynamic programming method and algorithm for solving the optimal control problem of semi-tensor product system are given. Finally, an algorithm is used to solve an example.
符繁强1,韦 维1,周 荧2,钱柳1
1贵州民族大学,数据科学与信息工程学院,贵州 贵阳
2贵州大学,数学与统计学院,贵州 贵阳
收稿日期:2018年10月1日;录用日期:2018年10月17日;发布日期:2018年10月24日
有限动态博弈过程在部分玩家的策略给定情形下,可以转化为多值逻辑控制网络的最优控制问题。本文研究这一类单输入输出的有限动态博弈问题,论文利用矩阵半张量积的方法,推导出多值逻辑动态系统的代数表达式和收益目标泛函的半张量积的表达形式,并证明此收益最大化问题新的表达方式与原问题的等价性;进而,给出了求解半张量积系统最优控制问题的动态规划法和算法;最后,应用此算法求解一个实例。
关键词 :矩阵半张量积,多值逻辑控制网络,最优控制,离散型动态规划方法
Copyright © 2018 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


布尔网络是描述人工智能系统、神经网络系统、基因调控网络等的一种简单可行工具 [
多值逻辑网络比布尔网络的应用更为广泛,所以在研究多值逻辑网络时同样可应用矩阵的半张量积。如文献 [
在这一节里,我们将本文的符号,涉及到的半张量积的定义和性质总结归纳如下。
为叙述方便,做以下的符号说明:
l M m × n : m × n 维实矩阵集合;
l D k = { 0 , 1 k − 1 , ⋯ , k − 2 k − 1 , 1 } ;
注:在博弈中也用
D k = { 1 , 2 , ⋯ , k }
这时,将 i ~ i − 1 k − 1 , i = 1 , 2 , ⋯ , k ,即可
l δ n k 为单位阵 I n 的第k列;
l C o l i ( A ) :为矩阵A的第i列,矩阵A的列集合记作 C o l ( A ) ;
l Δ k = { δ k i | i = 1 , 2 , ⋯ , k } ;这里 δ k i = C o l i ( I k ) ;
l 一个矩阵 L ∈ L n × m 称为逻辑矩阵,如果它的列满足 C o l ( L ) ⊂ Δ n ;
l 矩阵 L = [ δ n i 1 , δ n i 2 , ⋯ , δ n i m ] ∈ L n × m ,记为v。
定义2.2.1 [
a = l c m { n , p }
定义A与B的半张量积为
A ⋉ B : = ( A ⊗ I t / n ) ( B ⊗ I t / p ) ,
这里 ⊗ 是矩阵的Kronecker积(亦称张量积)。
注:当 n = p 时,矩阵 A , B 满足等维条件,定义化为普通矩阵乘法,因此,半张量积是普通乘法的推广。本文所说的半张量积均为左半张量积。
命题2.2.1 [
1) 结合律
( F ⋉ G ) ⋉ H = F ⋉ ( G ⋉ H ) .
2) 分配律
{ F ⋉ ( a G ± b H ) = a F ⋉ G ± b F ⋉ H , ( a F ± b G ) ⋉ H = a F ⋉ H ± b G ⋉ H , a , b ∈ R
命题2.2.2 [
( A ⋉ B ) T = B T ⋉ A T .
为了进一步实现交换运算,为此定义换位矩阵。
定义2.2.2 [
w ( I , J ) , ( i , j ) = δ ( i , j ) ( I , J ) = { 1 , I = i 且 J = j ; 0 , 其 他 .
当 n = m 时,我们简记 W [ n ] : = W [ n , n ] 。
命题2.2.3 [
x 2 = R k p x .
其中 R k p : = d i a g ( δ k 1 , δ k 2 , ⋯ , δ k k ) = δ k 2 [ 1 , k + 2 , 2 k + 3 , ⋯ , k 2 ] 称为k维降价矩阵。
利用降价矩阵与换位矩阵,我们可以降低计算逻辑函数的结构矩阵的计算量。
通过换位矩阵,引入半张量积的重要性质——伪交换性。
命题2.2.4 [
设 Y ∈ R t 为行向量,则
A ⋉ Y = Y ⋉ ( I t ⊗ A ) .
设 X ∈ R t 为列向量,则
X ⋉ A = ( I t ⊗ A ) ⋉ X .
设两个行向量 X ∈ R n , Y ∈ R m ,则
X ⋉ Y ⋉ W [ n , m ] = Y ⋉ X .
设两个列向量 X ∈ R n , Y ∈ R m ,则
W [ n , m ] ⋉ X ⋉ Y = Y ⋉ X .
本文只关心有限博弈。
定义2.3.1 [
1) N = { 1 , 2 , ⋯ , n } 表示这里有n玩家(局中人);
2) S = ∏ i = 1 n S i 称为局势,其中
S i = { S 1 i , ⋯ , S k i } , i = 1 , ⋯ , n
是第i个玩家的策略集,它表示第i个玩家有 k i 个策略可供选择,局势是所有玩家策略的笛卡尔积。
3) C = ( c 1 , ⋯ , c n ) ,其中 c i : S → R 是第i个玩家的收益函数为方便计,策略集通常记 S i = { 1 , ⋯ , k i } , i = 1 , ⋯ , n .
这里“有限”博弈指:
a) 玩家数 n < ∞ ,
b) 策略数 | S i | < ∞ , i = 1 , ⋯ , n .
本文我们考虑单输入输出有限博弈(参与者与行动集有限)的动态过程,并假定部分玩家被视为“机器”,其策略固定已知,另一部分玩家作为“人”,他的策略选择的准则是使其收益最大化。本文讨论所有玩家的策略都只有1步记忆的情形。
根据如上假设,此类博弈问题可以转化为下面的多值逻辑控制网络的优化问题。
控制系统为:
x ( k + 1 ) = f ( x ( k ) , u ( k ) ) , k = 1 , 2 , ⋯ (1)
其中
容许控制集为:
最优控制问题(P):假设初始时刻
机器策略
其中c为每一步的收益函数,
针对这种多值逻辑控制的最优控制问题不但包含状态系统的逻辑运算,而且又包含了性能指标的代数运算,如果仅仅只有单一的逻辑系统或一般最优控制方法是很难解决的,为解决此类问题。我们引入矩阵半张量工具将逻辑动态网络转化为对应的代数状态方程。
定理4.1.1 [
这里,
根据定理以及矩阵半张量积的性质,问题(P)可以等价表示为如下问题:
状态方程
其中
初始状态
收益函数所对应的半张量形式为:
目标泛函为
(P为
最优控制问题
变分法、庞特里亚金最大值原理、动态规划法是求解最优控制问题经典的三种方法,本文采用动态规划法求解离散系统的最优控制问题。针对半张量积表示的最优控制问题(
定理4.2.1:若
证明:以max为例证明此定理,反证法:
假设子策略
令
这与
下面我们将定理4.2.1的思想,转化为可计算的递归算法。对于任意给定的
设其性能指标为
则最优控制问题
当
则有如下定理:
定理4.2.2:对
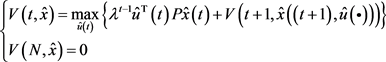

证明:由值函数
两端关于序列
对任何序列
证毕。
根据定理4.2.2,我们容易得到如下算法。
逆推算法4.3.1:
Step 1:利用终端条件
Step 2:根据状态方程
应用此算法通过反复的迭代和回代从而得到
最优轨线
最优策略
考虑有限的人机博弈,双方均有三个可选择的策略
这里机器采取的策略为:在本次博弈中如果赢或平,下次不改变策略,如果本次博弈输,则下次采用对手的策略。
| 机 人 | 1 | 2 | 3 |
|---|---|---|---|
| 1 | 3,3 | 0,4 | 9,2 |
| 2 | 4,0 | 4,4 | 5,3 |
| 3 | 2,9 | 3,5 | 6,6 |
表1. 支付双矩阵
给定初始状态
其中,
解:令
其中
初始条件
求使性能指标最大的控制序列
应用动态规划法求解
有,
当
有,
则当取
有,
则当取
因此所求的最优控制序列为:
将向量转化为标量则最优控制序列为:
注4.4.1:本文只研究了单输入输出的决策最优控制问题,本文所应用的定理和算法对于多输入多输系统的决策最优控制问题仍然适用。
本文研究了有限动态博弈过程中多值逻辑控制网络的收益优化问题,利用矩阵半张量积的方法将逻辑系统转化为对应的代数系统,并给出了半张量形式下目标泛函的表达式。在引入值函数的情况下对其最优性原理进行了证明并给出了算法,同时举例说明算法的有效性。
国家自然科学基金(No. 11761021),贵州民族大学科研基金资助项目(No. 2017ZD017)。
符繁强,韦维,周荧,钱柳. 一类多值控制网络最优决策的半张量积求解法研究 Research on Semi-Tensor Product Solution Method for Optimal Decision of a Class of Multi-Valued Control Networks[J]. 应用数学进展, 2018, 07(10): 1308-1316. https://doi.org/10.12677/AAM.2018.710152